Veja compute métricas
Este artigo explica como usar a ferramenta nativa compute métricas na interface do usuário Databricks para reunir hardware key e Spark métricas. A interface de usuário métricas está disponível para todos os fins e para o Job compute.
As métricas estão disponíveis quase em tempo real, com um atraso normal de menos de um minuto. As métricas são armazenadas no Databricks-gerenciar storage, e não no storage do cliente.
sem servidor compute para Notebook e Job usa percepções de consulta em vez da IU métrica. Para obter mais informações sobre serverless compute métricas, consulte view query percepções.
Acesse compute métricas UI
Para view a interface de usuário compute métricas:
- Clique em Calcular na barra lateral.
- Clique no compute recurso para o qual o senhor deseja view métricas.
- Clique nas métricas tab.
As métricas de hardware para todos os nós são exibidas por default. Para view as métricas Spark , clique no menu suspenso com a etiqueta Hardware e selecione Spark . Você também pode selecionar GPU se a instância estiver habilitada para GPU.
Filtrar métricas por período de tempo
O senhor pode view métricas históricas selecionando um intervalo de tempo usando o filtro de seleção de data. As métricas são coletadas a cada minuto, portanto, o senhor pode filtrar por qualquer intervalo de dia, hora ou minuto dos últimos 30 dias. Clique no ícone do calendário para selecionar entre intervalos de dados predefinidos ou clique dentro da caixa de texto para definir valores personalizados.
Os intervalos de tempo exibidos nos gráficos se ajustam com base no período de tempo que você está visualizando. A maioria das métricas são médias baseadas no intervalo de tempo que o senhor está visualizando no momento.
Você também pode obter as métricas mais recentes clicando no botão Atualizar .
visualizar métricas no nível do nó
Por default, a página de métricas mostra as métricas de todos os nós dentro de um cluster (incluindo o driver), com a média calculada ao longo do período.
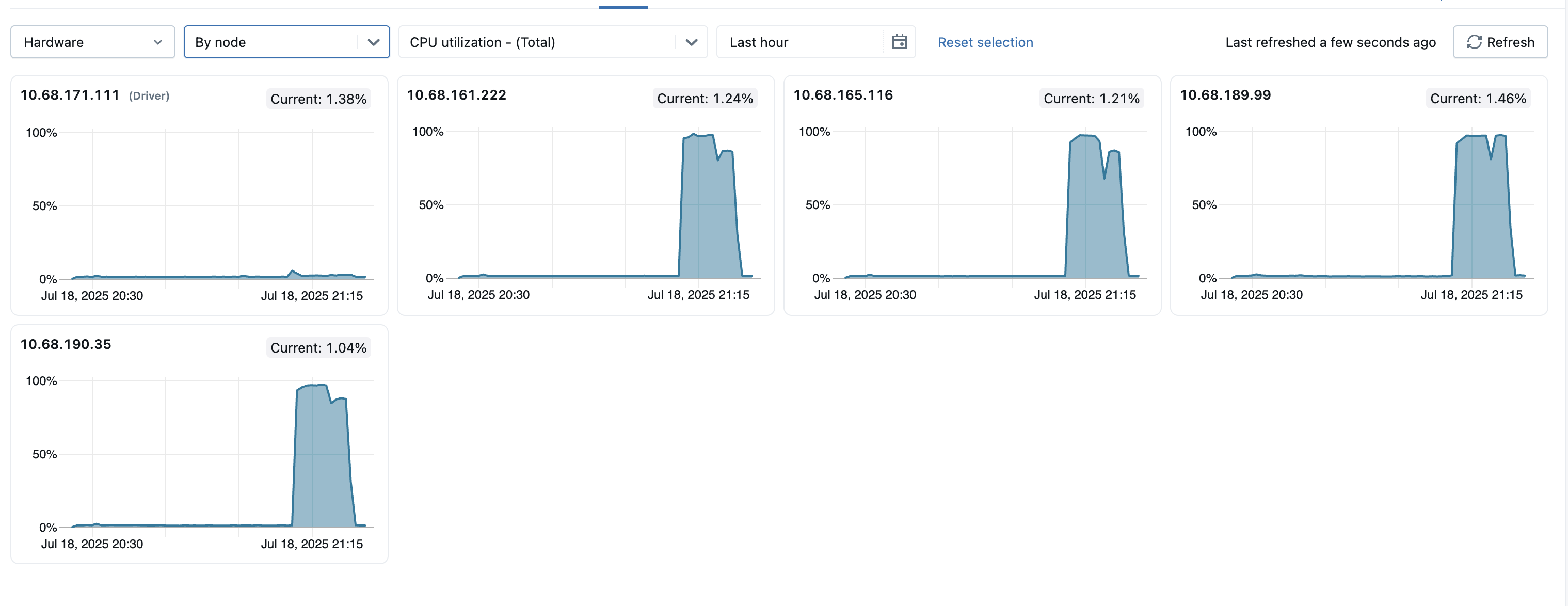
Você pode view as métricas de nós individuais clicando no menu suspenso "Todos os nós" e selecionando o nó para o qual deseja view as métricas. As métricas da GPU estão disponíveis apenas no nível de cada nó individual. As métricas do Spark não estão disponíveis para nós individuais.
Para ajudar a identificar nós atípicos dentro do cluster, você também pode view as métricas de todos os nós individuais em uma única página. Para acessar essa view, clique no menu dropdown Todos os nós e selecione Por nó , depois selecione a subcategoria de métricas que deseja view.
Gráficos métricos de hardware
Os seguintes gráficos de métricas de hardware estão disponíveis para view na interface de usuário de métricas compute:
-
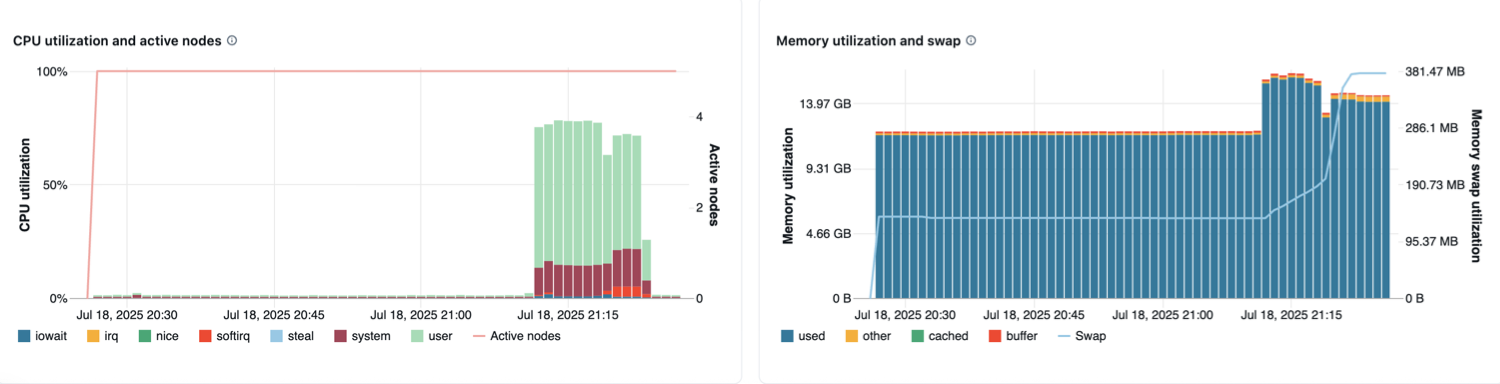
Utilização da CPU e nós ativos : O gráfico de linhas exibe o número de nós ativos em cada instante de tempo para o compute especificado. O gráfico de barras exibe a porcentagem de tempo que a CPU passou em cada modo, com base no custo total em segundos de CPU. A métrica de utilização é a média do intervalo de tempo exibido no gráfico. Os modos de monitoramento são os seguintes:
- convidado: Se você estiver executando VMs, a CPU que essas VMs usam
- iowait: Tempo gasto esperando pela E/S
- parado: Tempo em que a CPU não tinha nada para fazer
- irq: Tempo gasto em solicitações de interrupção
- nice: Tempo usado por processos que têm um niceness positivo, ou seja, uma prioridade mais baixa do que outras tarefas
- softirq: Tempo gasto em solicitações de interrupção de software
- roubar: se você é uma VM, hora em que outras VMs “roubaram” de suas CPUs
- sistema: O tempo gasto no kernel
- usuário: O tempo gasto na área do usuário
-
Utilização de memória e swap : O gráfico de linhas mostra o uso total de memória swap por modo, medido em bytes e calculado como média no intervalo de tempo exibido. O gráfico de barras mostra o uso total de memória por modo, também medido em bytes e calculado como média no intervalo de tempo exibido. Os seguintes tipos de uso são monitorados:
- usado: Total de memória em uso no nível do sistema operacional, incluindo a memória usada por processos em segundo plano em execução em um compute. Como o driver e os processos em segundo plano utilizam memória, o uso ainda pode ocorrer mesmo quando nenhum trabalho Spark está em execução.
- grátis: memória não utilizada
- buffer: memória usada pelos buffers do kernel
- em cache: memória usada pelo cache do sistema de arquivos no nível do sistema operacional
-
Rede recebida e transmitida : O número de bytes recebidos e transmitidos pela rede por cada dispositivo, calculado como a média com base no intervalo de tempo exibido no gráfico.
-
Espaço livre no sistema de arquivos : O uso total do sistema de arquivos por cada ponto de montagem, medido em bytes e calculado como média com base no intervalo de tempo exibido no gráfico.
Gráficos de métricas do Spark
Os seguintes gráficos Spark métricas estão disponíveis para view na UI compute métricas:
- Distribuição da carga do servidor : Esses gráficos mostram a utilização da CPU no último minuto para cada nó no recurso compute . Cada bloco é um link clicável que leva à página de métricas do nó individual.
- Tarefa ativa : O número total de tarefas em execução em um determinado momento, calculado com base no intervalo de tempo exibido no gráfico.
- Total de tarefas com falha : O número total de tarefas que falharam no executor, calculado com base no intervalo de tempo exibido no gráfico.
- Total de tarefas concluídas : O número total de tarefas que foram concluídas no executor, calculado com base no intervalo de tempo exibido no gráfico.
- Número total de tarefas : O número total de todas as tarefas (em execução, com falha e concluídas) no executor, calculado com base no intervalo de tempo exibido no gráfico.
- Leitura total consultada : O tamanho total dos dados de leitura consultada, medido em bytes e calculado com base em qualquer intervalo de tempo exibido no gráfico.
Shuffle readsignifica a soma dos dados de leitura serializados em todos os executores no início de um estágio. - Total registrado: O tamanho total dos dados registrados, medido em bytes e calculado com base em qualquer intervalo de tempo exibido no gráfico.
Shuffle Writeé a soma de todos os dados serializados gravados em todos os executores antes da transmissão (normalmente no final de um estágio). - Duração total da tarefa : O tempo total decorrido que a JVM gastou executando a tarefa no executor, medido em segundos e calculado como a média com base no intervalo de tempo exibido no gráfico.
Gráficos de métricas de GPU
As GPU métricas estão disponíveis apenas em Databricks Runtime ML 13.3 e acima.
Os gráficos de métricas de GPU a seguir estão disponíveis para view na interface de usuário de métricas de compute:
- Distribuição da carga do servidor : este gráfico mostra a utilização da CPU no último minuto para cada nó.
- Utilização do decodificador por GPU : A porcentagem de utilização do decodificador da GPU, calculada com base no intervalo de tempo exibido no gráfico.
- Utilização do codificador por GPU : A porcentagem de utilização do codificador da GPU, calculada com base no intervalo de tempo exibido no gráfico.
- Utilização de memória do buffer de quadros por GPU (bytes) : A utilização da memória do buffer de quadros, medida em bytes e calculada a média com base no intervalo de tempo exibido no gráfico.
- Utilização de memória por GPU : A porcentagem de utilização da memória da GPU, calculada com base no intervalo de tempo exibido no gráfico.
- Utilização por GPU : A porcentagem de utilização da GPU, calculada com base no intervalo de tempo exibido no gráfico.
Solução de problemas
Se o senhor vir métricas incompletas ou ausentes para um período, pode ser um dos seguintes problemas:
- Uma interrupção no serviço Databricks responsável por consultar e armazenar métricas.
- Problemas de rede do lado do cliente.
- O site compute está ou estava em um estado insalubre.