Create and manage compute policies
This article explains how to create and manage policies in your workspace. For information on writing policy definitions, see Compute policy reference.
What are compute policies?
A policy is a tool workspace admins can use to limit a user or group's compute creation permissions based on a set of policy rules.
Policies provide the following benefits:
- Limit users to creating clusters with prescribed settings.
- Limit users to creating a certain number of clusters.
- Simplify the user interface and enable more users to create their own clusters (by fixing and hiding some values).
- Control cost by limiting per-cluster maximum cost (by setting limits on attributes whose values contribute to hourly price).
- Enforce cluster-scoped library installations.
Create a policy
These instructions use the policy UI, which allows you to configure policy definitions using dropdown menus and other UI elements. You can also edit the full policy definition as JSON. For more information, see Configure policy definitions using UI elements.
To create a policy:
- Click
 Compute in the sidebar.
Compute in the sidebar. - Click the Policies tab.
- Click Create policy.
- Name the policy. Policy names are case-insensitive.
- Optionally, select a policy family from the Family dropdown. This determines the template from which you build the policy.
- Enter a Description of the policy. This helps others know the purpose of the policy.
- Under Advanced options, you can specify the cluster type, max compute resources per user, and max DBUs per hour.
- In the Definitions tab, add new definitions or edit inherited definitions. Add JSON rules in the Advanced options section, or click the Edit definition as JSON button to edit the entire policy definition as JSON.
- In the Tags section, define rules around custom tags
- In the Libraries tab, add any compute-scoped libraries that you want the policy to install on the compute. See Add libraries to a policy.
- Click Create.
To update the policy permissions, open the policy's overview page and click See all permissions to open the permissions modal.
Use a policy family
When you create a policy, you can choose to use a policy family. Policy families are Databricks-provided policy templates with pre-populated rules, designed to address common compute use cases.
When using a policy family, the rules for your policy are inherited from the policy family. After selecting a policy family, you can create the policy as-is, or choose to add rules or override the given rules. For more on policy families, see Default policies and policy families.
Add libraries to a policy
You can add libraries to a policy so libraries are automatically installed on compute resources. You can add a maximum of 500 libraries to a policy.
You may have previously added compute-scoped libraries using init scripts. Databricks recommends using compute policies instead of init scripts to install libraries.
To add a library to your policy:
-
At the bottom of the Create policy page, click the Libraries tab.
-
Click Add library.
-
Select one of the Library Source options, then follow the instructions as outlined below:
Library source
Instructions
Workspace
Select a workspace file or upload a Whl, zipped wheelhouse (with
*.wheelhouse.whlextension), JAR, ZIP, tar, or requirements.txt file. See Install libraries from workspace filesVolumes
Select a Whl, JAR, or requirements.txt file from a volume. See Install libraries from a volume.
File Path/S3
Select the library type and provide the full URI to the library object (for example:
s3://bucket-name/path/to/library.whl). See Install libraries from object storage.PyPI
Enter a PyPI package name. See PyPI package.
Maven
Specify a Maven coordinate. See Maven or Spark package.
CRAN
Enter the name of a package. See CRAN package.
DBFS (Deprecated)
Load a JAR or Whl file to the DBFS root. This is deprecated and not a recommended pattern.
-
Click Add.
Effect of adding libraries to policies
If you add libraries to a policy:
- Users can't install or uninstall compute-scoped libraries on compute that use this policy.
- Libraries configured through the UI, REST API, or CLI on existing compute are removed the next time the compute restarts.
- Dependency libraries for tasks that use this policy in jobs compute resources are disabled.
Policy permissions
By default, workspace admins have permissions on all policies. Non-admin users must be granted permissions on a policy to access it.
If a user has unrestricted cluster creation permissions, then they will also have access to the Unrestricted policy. This allows them to create fully configurable compute resources.
If a user doesn't have access to any policies, the policy dropdown does not display in their UI.
Restrict the number of compute resources per users
Policy permissions allow you to set a max number of compute resources per user. This determines how many resources a user can create using that policy. If the user exceeds the limit, the operation fails.
To restrict the number of resources a user can create using a policy, enter a value into the Max compute resources per user setting under Advanced options.
Databricks doesn't proactively terminate resources to maintain the limit. If a user has three compute resources running with the policy and the workspace admin reduces the limit to one, the three resources will continue to run. Extra resources must be manually terminated to comply with the limit.
Manage a policy
After you create a policy, you can edit, clone, and delete it.
You can also monitor the policy's adoption by viewing the compute resources that use the policy. From the Policies page, click the policy you want to view. Then click the Compute or Jobs tabs to see a list of resources that use the policy.
Edit a policy
You might want to edit a policy to update its permissions or its definitions. To edit a policy, select the policy from the Policies page then click Edit.
After you update a policy's definitions, the compute resources created using that policy aren't automatically updated with the new policy definitions. You can choose to update all or some of these compute resources using policy compliance enforcement. See Enforce policy compliance.
Clone a policy
You can also use the cloning feature to create a new policy from an existing policy. Open the policy you want to clone then click the ![]() kebab menu and select Clone button. Then change any values of the fields that you want to modify and click Create.
kebab menu and select Clone button. Then change any values of the fields that you want to modify and click Create.
Delete a policy
Select the policy from the Policies page then click the ![]() kebab menu and select Delete. When asked if you're sure you want to delete the policy, click Delete again.
kebab menu and select Delete. When asked if you're sure you want to delete the policy, click Delete again.
Any compute governed by a deleted policy can still run, but it cannot be edited unless the user has unrestricted cluster creation permissions.
Enforce policy compliance
After you edit a policy, the compute resources created using that policy do not automatically update to adhere to the new policy rules. To view a list of compute resources governed by the policy, click the policy in the UI to view the all-purpose compute and jobs that use the policy.
These lists will also tell you if any compute resources are out of compliance with the current policy definitions.
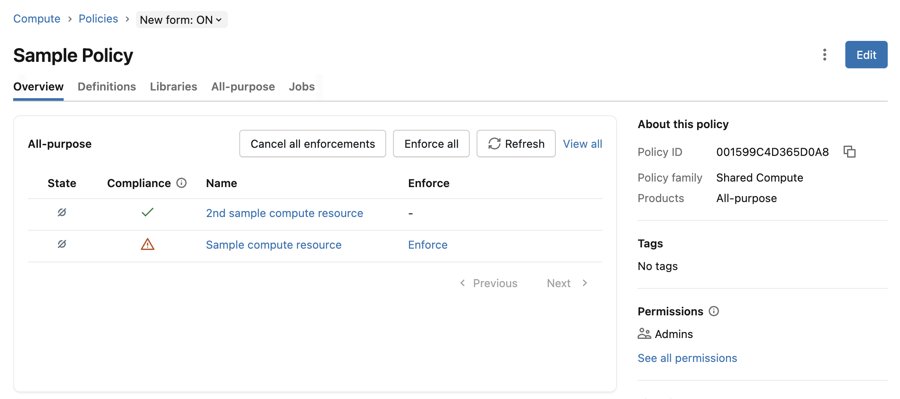
To update compute resources to comply with a policy:
-
From the Policies page, click the policy you have updated.
-
View the All-purpose or Jobs sections to see a list of resources or jobs that use the policy. The Compliance column tells you which resources are in compliance with the current policy definitions.
-
Click Enforce all to update all compute resources in the list that are out of compliance. You can also individually update compute resources by clicking the Enforce button in the resource's row.
-
For all-purpose compute, choose how to apply the updates:
- Enforce on next restart (default): Schedules the configuration update to apply the next time the compute terminates or restarts. Running workloads aren't interrupted. Only workspace admins can schedule or cancel deferred enforcement.
- Restart and enforce: Immediately restarts the compute and applies the updated configuration.
Jobs compute is always enforced immediately, because enforcement doesn't require running job runs to terminate.
-
Click Enforce to make the updates. After the enforcement operation is completed you are given a summary of the changes made.
-
Click Done.
When you enforce policy compliance, array-type attributes such as init scripts are matched by index position. If a policy defines a value at a given position, the existing value at that position is replaced. The replaced value is not moved to another position in the array. To preview the changes before enforcing, click Enforce next to an individual resource to see how its attributes will be updated.
Cancel a scheduled enforcement
Workspace admins can cancel pending deferred enforcements on all-purpose compute:
- To cancel all pending enforcements for a policy, click Cancel all enforcements on the policy details page.
- To cancel the pending enforcement for a single compute resource, open the
 kebab menu on that compute resource and select Cancel pending enforcement.
kebab menu on that compute resource and select Cancel pending enforcement.
When a deferred enforcement is scheduled on a compute resource, the compute details page includes an Update scheduled on next restart label. Workspace admins can cancel the pending enforcement from this page by clicking the kebab menu ![]() and then selecting Cancel pending enforcement.
and then selecting Cancel pending enforcement.
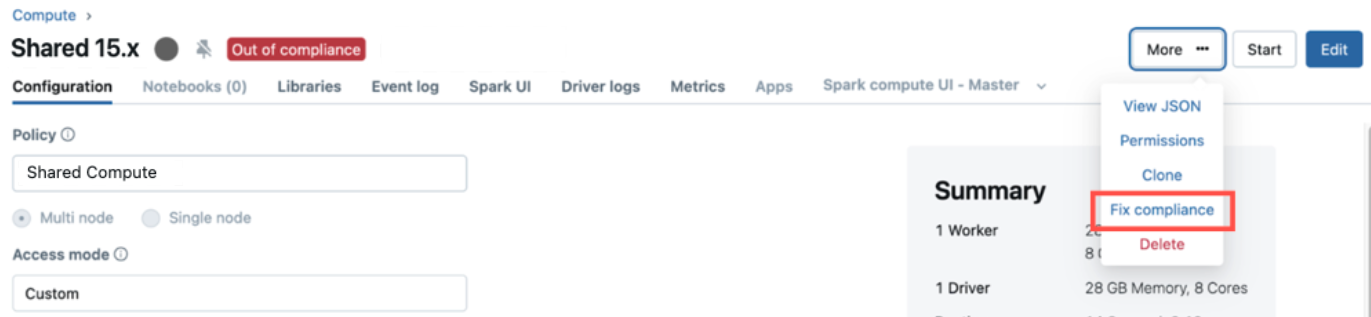
Enforce compliance from the compute details page
Out-of-compliance all-purpose compute resources include an Out of compliance label in their compute details UI. Users with CAN MANAGE permissions on the compute resource can schedule enforcement from this page by clicking the kebab menu ![]() and then selecting Fix compliance.
and then selecting Fix compliance.