Point-in-time feature joins
Point-in-time correctness creates a training dataset that reflects feature values as of the time each label observation was recorded. This is important to prevent data leakage, which occurs when you use feature values for model training that were not available at the time the label was recorded. This type of error can be hard to detect and can negatively affect the model's performance.
Time series feature tables include a timestamp key column that ensures that each row in the training dataset represents the latest known feature values as of the row's timestamp. You should use time series feature tables whenever feature values change over time, for example with time series data, event-based data, or time-aggregated data.
The following diagram shows how the timestamp key is used. The feature value recorded for each timestamp is the latest value before that timestamp, indicated by the outlined orange circle. If no values have been recorded, the feature value is null. For more details, see How time series feature tables work.
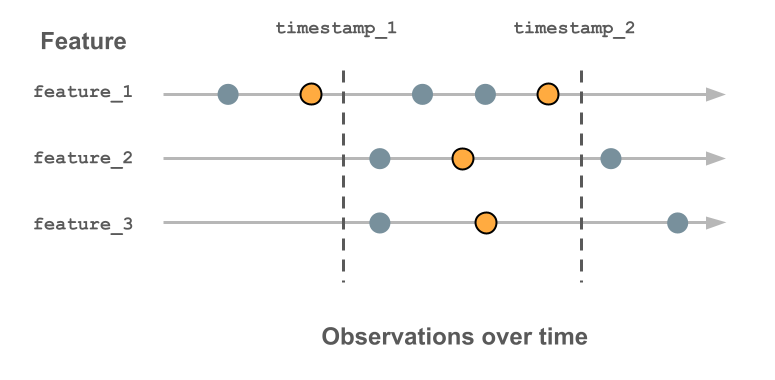
- With Databricks Runtime 13.3 LTS and above, any Delta table in Unity Catalog with primary keys and timestamp keys can be used as a time series feature table.
- For better performance in point-in-time lookups, Databricks recommends liquid clustering (
databricks-feature-engineering0.6.0 and above) on time series tables. See Use liquid clustering for tables and Data skipping. - Point-in-time lookup functionality is sometimes referred to as “time travel”. The point-in-time functionality in Databricks Feature Store is not related to Delta Lake time travel.
How time series feature tables work
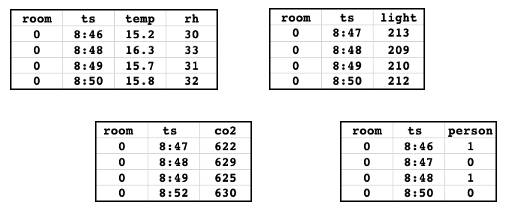
Suppose you have the following feature tables. This data is taken from the example notebook.
The tables contain sensor data measuring the temperature, relative humidity, ambient light, and carbon dioxide in a room. The ground truth table indicates if a person was present in the room. Each of the tables has a primary key ('room') and a timestamp key ('ts'). For simplicity, only data for a single value of the primary key ('0') is shown.
The following figure illustrates how the timestamp key is used to ensure point-in-time correctness in a training dataset. Feature values are matched based on the primary key (not shown in the diagram) and the timestamp key, using an AS OF join. The AS OF join ensures that the most recent value of the feature at the time of the timestamp is used in the training set.
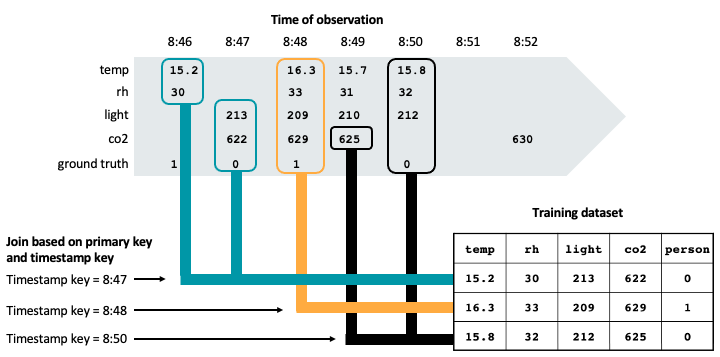
As shown in the figure, the training dataset includes the latest feature values for each sensor prior to the timestamp on the observed ground truth.
If you created a training dataset without taking into account the timestamp key, you might have a row with these feature values and observed ground truth:
temp | rh | light | co2 | ground truth |
|---|---|---|---|---|
15.8 | 32 | 212 | 630 | 0 |
However, this is not a valid observation for training, because the co2 reading of 630 was taken at 8:52, after the observation of the ground truth at 8:50. The future data is “leaking” into the training set, which will impair the model's performance.
Requirements
- For Feature Engineering in Unity Catalog: Feature Engineering in Unity Catalog client (any version).
- For Workspace Feature Store (legacy): Feature Store client v0.3.7 and above.
How to specify time-related keys
To use point-in-time functionality, you must specify time-related keys using the timeseries_columns argument (for Feature Engineering in Unity Catalog) or the timestamp_keys argument (for Workspace Feature Store). This indicates that feature table rows should be joined by matching the most recent value for a particular primary key that is not later than the value of the timestamps_keys column, instead of joining based on an exact time match.
If you do not use timeseries_columns or timestamp_keys, and only designate a time series column as a primary key column, feature store does not apply point-in-time logic to the time series column during joins. Instead, it matches only rows with an exact time match instead of matching all rows prior to the timestamp.
Create a time series feature table in Unity Catalog
In Unity Catalog, any table with a TIMESERIES primary key is a time series feature table. To create a time series feature table, see Create a feature table in Unity Catalog. The following examples illustrate the different types of time series tables.
Publish time series tables to online stores
When working with feature tables that contain timestamp data, you need to consider whether to designate the timestamp column as a timeseries_column or treat it as a regular column, depending on your online serving requirements.
Timestamp columns marked with time series designation
Use timeseries_column when you need point-in-time correctness for training datasets and want to look up the most recent feature values as of a specific timestamp in online applications. A time series feature table must have one timestamp key and cannot have any partition columns. The timestamp key column must be of TimestampType or DateType.
Databricks recommends that time series feature tables have no more than two primary key columns to ensure performant writes and lookups.
- FeatureEngineeringClient API
- SQL API
fe = FeatureEngineeringClient()
# Create a time series table for point-in-time joins
fe.create_table(
name="catalog.schema.user_behavior_features",
primary_keys=["user_id", "event_timestamp"],
timeseries_columns="event_timestamp", # Enables point-in-time logic
df=features_df # DataFrame must contain primary keys and time series columns
)
-- Create table with time series constraint for point-in-time joins
CREATE TABLE catalog.schema.user_behavior_features (
user_id STRING NOT NULL,
event_timestamp TIMESTAMP NOT NULL, -- part of primary key and designated as TIMESERIES
purchase_amount DOUBLE,
page_views_last_hour INT,
CONSTRAINT pk_user_behavior PRIMARY KEY (user_id, event_timestamp TIMESERIES)
) USING DELTA
TBLPROPERTIES (
'delta.enableChangeDataFeed' = 'true'
);
If a feature table has a DATE or TIMESTAMP column as a primary key that is not declared as a timeseries column using timeseries_columns, you cannot use the table with create_feature_spec(), create_training_set(), or publish_table(). These APIs require that all DATE and TIMESTAMP primary key columns are declared as timeseries columns.
If your use case requires a date or timestamp value as a plain lookup key (exact-match semantics, no point-in-time logic), change the column type to STRING instead.
Update a time series feature table
When writing features to the time series feature tables, your DataFrame must supply values for all features of the feature table, unlike regular feature tables. This constraint reduces the sparsity of feature values across timestamps in the time series feature table.
- Feature Engineering in Unity Catalog
- Workspace Feature Store client v0.13.4 and above
fe = FeatureEngineeringClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.write_table(
"ml.ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
fs = FeatureStoreClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.write_table(
"ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
Streaming writes to time series feature tables is supported.
Create a training set with a time series feature table
To perform a point-in-time lookup for feature values from a time series feature table, you must specify a timestamp_lookup_key in the feature's FeatureLookup, which indicates the name of the DataFrame column that contains timestamps against which to lookup time series features. Databricks Feature Store retrieves the latest feature values prior to the timestamps specified in the DataFrame's timestamp_lookup_key column and whose primary keys (excluding timestamp keys) match the values in the DataFrame's lookup_key columns, or null if no such feature value exists.
- Feature Engineering in Unity Catalog
- Workspace Feature Store
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ml.ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fe.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
For faster lookup performance when Photon is enabled, pass use_spark_native_join=True to FeatureEngineeringClient.create_training_set. This requires databricks-feature-engineering version 0.6.0 or above.
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fs.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
Any FeatureLookup on a time series feature table must be a point-in-time lookup, so it must specify a timestamp_lookup_key column to use in your DataFrame. Point-in-time lookup does not skip rows with null feature values stored in the time series feature table.
Set a time limit for historical feature values
With Feature Store client v0.13.0 or above, or any version of Feature Engineering in Unity Catalog client, you can exclude feature values with older timestamps from the training set. To do so, use the parameter lookback_window in the FeatureLookup.
The data type of lookback_window must be datetime.timedelta, and the default value is None (all feature values are used, regardless of age).
For example, the following code excludes any feature values that are more than 7 days old:
- Feature Engineering in Unity Catalog
- Workspace Feature Store
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
When you call create_training_set with the above FeatureLookup, it automatically performs the point-in-time join and excludes feature values older than 7 days.
The lookback window is applied during training and batch inference. During online inference, the latest feature value is always used, regardless of the lookback window.
Score models with time series feature tables
When you score a model trained with features from time series feature tables, Databricks Feature Store retrieves the appropriate features using point-in-time lookups with metadata packaged with the model during training. The DataFrame you provide to FeatureEngineeringClient.score_batch (for Feature Engineering in Unity Catalog) or FeatureStoreClient.score_batch (for Workspace Feature Store) must contain a timestamp column with the same name and DataType as the timestamp_lookup_key of the FeatureLookup provided to FeatureEngineeringClient.create_training_set or FeatureStoreClient.create_training_set.
For faster lookup performance when Photon is enabled, pass use_spark_native_join=True to FeatureEngineeringClient.score_batch. This requires databricks-feature-engineering version 0.6.0 or above.
Publish time series features to an online store
You can use FeatureEngineeringClient.publish_table (for Feature Engineering in Unity Catalog) or FeatureStoreClient.publish_table (for Workspace Feature Store) to publish time series feature tables to online stores. Databricks Feature Store provides the functionality to publish either a snapshot or a window of time series data to the online store, depending on the online store provider. The following table shows the supported modes for each provider.
Online store provider | Snapshot mode | Window mode |
|---|---|---|
Amazon DynamoDB (v0.3.8 and above) | X | X |
Amazon Aurora (MySQL-compatible) | X |
|
Amazon RDS MySQL | X |
|
Publish a time series snapshot
In snapshot mode, publish_table publishes the latest feature values for each primary key in the feature table. The online store supports primary key lookup but does not support point-in-time lookup.
For online stores that do not support time to live, Databricks Feature Store supports only snapshot publish mode. For online stores that do support time to live, the default publish mode is snapshot unless time to live (ttl) is specified in the OnlineStoreSpec at the time of creation.
Publish a time series window
In window mode, publish_table publishes all feature values for each primary key in the feature table to the online store and automatically removes expired records. A record is considered expired if the record's timestamp (in UTC) is more than the specified time to live duration in the past. Refer to cloud-specific documentation for details on time-to-live.
The online store supports primary key lookup and automatically retrieves the feature value with the latest timestamp.
In window mode, you must provide a value for time to live (ttl) in the OnlineStoreSpec when you create the online store. The ttl cannot be changed once set. All subsequent publish calls inherit the ttl and are not required to explicitly define it in the OnlineStoreSpec.
Notebook example: Time series feature table
These example notebooks illustrate point-in-time lookups on time series feature tables.
Use this notebook in workspaces enabled for Unity Catalog.
Time series feature table example notebook (Unity Catalog)
The following notebook is designed for workspaces that are not enabled for Unity Catalog. It uses the Workspace Feature Store.