Dates and timestamps
This documentation has been retired and might not be updated. The products, services, or technologies mentioned in this content are no longer supported. See Datetime patterns.
The Date and Timestamp datatypes changed significantly in Databricks Runtime 7.0. This article describes:
- The
Datetype and the associated calendar. - The
Timestamptype and how it relates to time zones. It also explains the details of time zone offset resolution and the subtle behavior changes in the new time API in Java 8, used by Databricks Runtime 7.0. - APIs to construct date and timestamp values.
- Common pitfalls and best practices for collecting date and timestamp objects on the Apache Spark driver.
Dates and calendars
A Date is a combination of the year, month, and day fields, like (year=2012, month=12, day=31). However, the values of the year, month, and day fields have constraints to ensure that the date value is a valid date in the real world. For example, the value of month must be from 1 to 12, the value of day must be from 1 to 28,29,30, or 31 (depending on the year and month), and so on. The Date type does not consider time zones.
Calendars
Constraints on Date fields are defined by one of many possible calendars. Some, like the Lunar calendar, are used only in specific regions. Some, like the Julian calendar, are used only in history. The de facto international standard is the Gregorian calendar which is used almost everywhere in the world for civil purposes. It was introduced in 1582 and was extended to support dates before 1582 as well. This extended calendar is called the Proleptic Gregorian calendar.
Databricks Runtime 7.0 uses the Proleptic Gregorian calendar, which is already being used by other data systems like pandas, R, and Apache Arrow. Databricks Runtime 6.x and below used a combination of the Julian and Gregorian calendar: for dates before 1582, the Julian calendar was used, for dates after 1582 the Gregorian calendar was used. This is inherited from the legacy java.sql.Date API, which was superseded in Java 8 by java.time.LocalDate, which uses the Proleptic Gregorian calendar.
Timestamps and time zones
The Timestamp type extends the Date type with new fields: hour, minute, second (which can have a fractional part) and together with a global (session scoped) time zone. It defines a concrete time instant. For example, (year=2012, month=12, day=31, hour=23, minute=59, second=59.123456) with session time zone UTC+01:00. When writing timestamp values out to non-text data sources like Parquet, the values are just instants (like timestamp in UTC) that have no time zone information. If you write and read a timestamp value with a different session time zone, you may see different values of the hour, minute, and second fields, but they are the same concrete time instant.
The hour, minute, and second fields have standard ranges: 0–23 for hours and 0–59 for minutes and seconds. Spark supports fractional seconds with up to microsecond precision. The valid range for fractions is from 0 to 999,999 microseconds.
At any concrete instant, depending on time zone, you can observe many different wall clock values:
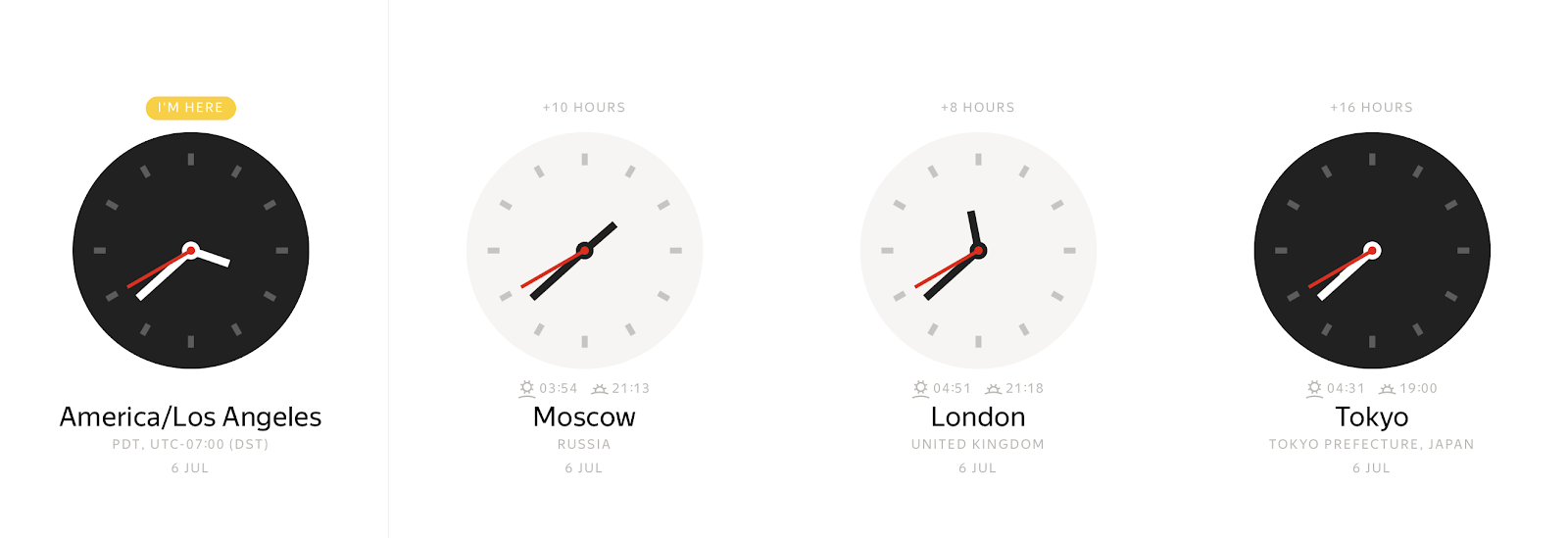
Conversely, a wall clock value can represent many different time instants.
The time zone offset allows you to unambiguously bind a local timestamp to a time instant. Usually, time zone offsets are defined as offsets in hours from Greenwich Mean Time (GMT) or UTC+0 (Coordinated Universal Time). This representation of time zone information eliminates ambiguity, but it is inconvenient. Most people prefer to point out a location such as America/Los_Angeles or Europe/Paris. This additional level of abstraction from zone offsets makes life easier but brings complications. For example, you now have to maintain a special time zone database to map time zone names to offsets. Since Spark runs on the JVM, it delegates the mapping to the Java standard library, which loads data from the Internet Assigned Numbers Authority Time Zone Database (IANA TZDB). Furthermore, the mapping mechanism in Java's standard library has some nuances that influence Spark's behavior.
Since Java 8, the JDK exposed a different API for date-time manipulation and time zone offset resolution and Databricks Runtime 7.0 uses this API. Although the mapping of time zone names to offsets has the same source, IANA TZDB, it is implemented differently in Java 8 and above compared to Java 7.
For example, take a look at a timestamp before the year 1883 in the America/Los_Angeles time zone: 1883-11-10 00:00:00. This year stands out from others because on November 18, 1883, all North American railroads switched to a new standard time system. Using the Java 7 time API, you can obtain a time zone offset at the local timestamp as -08:00:
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
The equivalent Java 8 API returns a different result:
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
Prior to November 18, 1883, time of day in North America was a local matter, and most cities and towns used some form of local solar time, maintained by a well-known clock (on a church steeple, for example, or in a jeweler's window). That's why you see such a strange time zone offset.
The example demonstrates that Java 8 functions are more precise and take into account historical data from IANA TZDB. After switching to the Java 8 time API, Databricks Runtime 7.0 benefited from the improvement automatically and became more precise in how it resolves time zone offsets.
Databricks Runtime 7.0 also switched to the Proleptic Gregorian calendar for the Timestamp type. The ISO SQL:2016 standard declares the valid range for timestamps is from 0001-01-01 00:00:00 to 9999-12-31 23:59:59.999999. Databricks Runtime 7.0 fully conforms to the standard and supports all timestamps in this range. Compared to Databricks Runtime 6.x and below, note the following sub-ranges:
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. Databricks Runtime 6.x and below uses the Julian calendar and doesn't conform to the standard. Databricks Runtime 7.0 fixes the issue and applies the Proleptic Gregorian calendar in internal operations on timestamps such as getting year, month, day, etc. Due to different calendars, some dates that exist in Databricks Runtime 6.x and below don't exist in Databricks Runtime 7.0. For example, 1000-02-29 is not a valid date because 1000 isn't a leap year in the Gregorian calendar. Also, Databricks Runtime 6.x and below resolves time zone name to zone offsets incorrectly for this timestamp range.1582-10-04 00:00:00..1582-10-14 23:59:59.999999. This is a valid range of local timestamps in Databricks Runtime 7.0, in contrast to Databricks Runtime 6.x and below where such timestamps didn't exist.1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Databricks Runtime 7.0 resolves time zone offsets correctly using historical data from IANA TZDB. Compared to Databricks Runtime 7.0, Databricks Runtime 6.x and below might resolve zone offsets from time zone names incorrectly in some cases, as shown in the preceding example.1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Both Databricks Runtime 7.0 and Databricks Runtime 6.x and below conform to the ANSI SQL standard and use Gregorian calendar in date-time operations such as getting the day of the month.2037-01-01 00:00:00..9999-12-31 23:59:59.999999. Databricks Runtime 6.x and below can resolve time zone offsets and daylight saving time offsets incorrectly. Databricks Runtime 7.0 does not.
One more aspect of mapping time zone names to offsets is overlapping of local timestamps that can happen due to daylight savings time (DST) or switching to another standard time zone offset. For instance, on November 3 2019, 02:00:00, most states in the USA turned clocks backwards 1 hour to 01:00:00. The local timestamp 2019-11-03 01:30:00 America/Los_Angeles can be mapped either to 2019-11-03 01:30:00 UTC-08:00 or 2019-11-03 01:30:00 UTC-07:00. If you don't specify the offset and just set the time zone name (for example, 2019-11-03 01:30:00 America/Los_Angeles), Databricks Runtime 7.0 takes the earlier offset, typically corresponding to “summer”. The behavior diverges from Databricks Runtime 6.x and below which takes the “winter” offset. In the case of a gap, where clocks jump forward, there is no valid offset. For a typical one-hour daylight saving time change, Spark moves such timestamps to the next valid timestamp corresponding to “summer” time.
As you can see from the preceding examples, the mapping of time zone names to offsets is ambiguous, and is not one to one. In the cases when it is possible, when constructing timestamps we recommend specifying exact time zone offsets, for example 2019-11-03 01:30:00 UTC-07:00.
ANSI SQL and Spark SQL timestamps
The ANSI SQL standard defines two types of timestamps:
TIMESTAMP WITHOUT TIME ZONEorTIMESTAMP: Local timestamp as (YEAR,MONTH,DAY,HOUR,MINUTE,SECOND). These timestamps are not bound to any time zone, and are wall clock timestamps.TIMESTAMP WITH TIME ZONE: Zoned timestamp as (YEAR,MONTH,DAY,HOUR,MINUTE,SECOND,TIMEZONE_HOUR,TIMEZONE_MINUTE). These timestamps represent an instant in the UTC time zone + a time zone offset (in hours and minutes) associated with each value.
The time zone offset of a TIMESTAMP WITH TIME ZONE does not affect the physical point in time that the timestamp represents, as that is fully represented by the UTC time instant given by the other timestamp components. Instead, the time zone offset only affects the default behavior of a timestamp value for display, date/time component extraction (for example, EXTRACT), and other operations that require knowing a time zone, such as adding months to a timestamp.
Spark SQL defines the timestamp type as TIMESTAMP WITH SESSION TIME ZONE, which is a combination of the fields (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, SESSION TZ) where the YEAR through SECOND field identify a time instant in the UTC time zone, and where SESSION TZ is taken from the SQL config spark.sql.session.timeZone. The session time zone can be set as:
- Zone offset
(+|-)HH:mm. This form allows you to unambiguously define a physical point in time. - Time zone name in the form of region ID
area/city, such asAmerica/Los_Angeles. This form of time zone info suffers from some of the problems described previously like overlapping of local timestamps. However, each UTC time instant is unambiguously associated with one time zone offset for any region ID, and as a result, each timestamp with a region ID based time zone can be unambiguously converted to a timestamp with a zone offset. By default, the session time zone is set to the default time zone of the Java virtual machine.
Spark TIMESTAMP WITH SESSION TIME ZONE is different from:
TIMESTAMP WITHOUT TIME ZONE, because a value of this type can map to multiple physical time instants, but any value ofTIMESTAMP WITH SESSION TIME ZONEis a concrete physical time instant. The SQL type can be emulated by using one fixed time zone offset across all sessions, for instance UTC+0. In that case, you could consider timestamps at UTC as local timestamps.TIMESTAMP WITH TIME ZONE, because according to the SQL standard column values of the type can have different time zone offsets. That is not supported by Spark SQL.
You should notice that timestamps that are associated with a global (session scoped) time zone are not something newly invented by Spark SQL. RDBMSs such as Oracle provide a similar type for timestamps: TIMESTAMP WITH LOCAL TIME ZONE.
Construct dates and timestamps
Spark SQL provides a few methods for constructing date and timestamp values:
- Default constructors without parameters:
CURRENT_TIMESTAMP()andCURRENT_DATE(). - From other primitive Spark SQL types, such as
INT,LONG, andSTRING - From external types like Python datetime or Java classes
java.time.LocalDate/Instant. - Deserialization from data sources such as CSV, JSON, Avro, Parquet, ORC, and so on.
The function MAKE_DATE introduced in Databricks Runtime 7.0 takes three parameters—YEAR, MONTH, and DAY—and constructs a DATE value. All input parameters are implicitly converted to the INT type whenever possible. The function checks that the resulting dates are valid dates in the Proleptic Gregorian calendar, otherwise it returns NULL. For example:
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
To print DataFrame content, call the show() action, which converts dates to strings on executors and transfers the strings to the driver to output them on the console:
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
Similarly, you can construct timestamp values using the MAKE_TIMESTAMP functions. Like MAKE_DATE, it performs the same validation for date fields, and additionally accepts time fields HOUR (0-23), MINUTE (0-59) and SECOND (0-60). SECOND has the type Decimal(precision = 8, scale = 6) because seconds can be passed with the fractional part up to microsecond precision. For example:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
As for dates, print the content of the ts DataFrame using the show() action. In a similar way, show() converts timestamps to strings but now it takes into account the session time zone defined by the SQL config spark.sql.session.timeZone.
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
Spark cannot create the last timestamp because this date is not valid: 2019 is not a leap year.
You might notice that there is no time zone information in the preceding example. In that case, Spark takes a time zone from the SQL configuration spark.sql.session.timeZone and applies it to function invocations. You can also pick a different time zone by passing it as the last parameter of MAKE_TIMESTAMP. Here is an example:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
As the example demonstrates, Spark takes into account the specified time zones but adjusts all local timestamps to the session time zone. The original time zones passed to the MAKE_TIMESTAMP function are lost because the TIMESTAMP WITH SESSION TIME ZONE type assumes that all values belong to one time zone, and it doesn't even store a time zone per every value. According to the definition of the TIMESTAMP WITH SESSION TIME ZONE, Spark stores local timestamps in the UTC time zone, and uses the session time zone while extracting date-time fields or converting the timestamps to strings.
Also, timestamps can be constructed from the LONG type using casting. If a LONG column contains the number of seconds since the epoch 1970-01-01 00:00:00Z, it can be cast to a Spark SQL TIMESTAMP:
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
Unfortunately, this approach doesn't allow you to specify the fractional part of seconds.
Another way is to construct dates and timestamps from values of the STRING type. You can make literals using special keywords:
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
Alternatively, you can use casting that you can apply for all values in a column:
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
The input timestamp strings are interpreted as local timestamps in the specified time zone or in the session time zone if a time zone is omitted in the input string. Strings with unusual patterns can be converted to timestamp using the to_timestamp() function. The supported patterns are described in Datetime Patterns for Formatting and Parsing:
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
If you don't specify a pattern, the function behaves similarly to CAST.
For usability, Spark SQL recognizes special string values in all methods that accept a string and return a timestamp or date:
epochis an alias for date1970-01-01or timestamp1970-01-01 00:00:00Z.nowis the current timestamp or date at the session time zone. Within a single query it always produces the same result.todayis the beginning of the current date for theTIMESTAMPtype or just current date for theDATEtype.tomorrowis the beginning of the next day for timestamps or just the next day for theDATEtype.yesterdayis the day before current one or its beginning for theTIMESTAMPtype.
For example:
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
Spark allows you to create Datasets from existing collections of external objects at the driver side and create columns of corresponding types. Spark converts instances of external types to semantically equivalent internal representations. For example, to create a Dataset with DATE and TIMESTAMP columns from Python collections, you can use:
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
PySpark converts Python's date-time objects to internal Spark SQL representations at the driver side using the system time zone, which can be different from Spark's session time zone setting spark.sql.session.timeZone. The internal values don't contain information about the original time zone. Future operations over the parallelized date and timestamp values take into account only Spark SQL sessions time zone according to the TIMESTAMP WITH SESSION TIME ZONE type definition.
In a similar way, Spark recognizes the following types as external date-time types in Java and Scala APIs:
java.sql.Dateandjava.time.LocalDateas external types for theDATEtypejava.sql.Timestampandjava.time.Instantfor theTIMESTAMPtype.
There is a difference between java.sql.* and java.time.* types. java.time.LocalDate and java.time.Instant were added in Java 8, and the types are based on the Proleptic Gregorian calendar–the same calendar that is used by Databricks Runtime 7.0 and above. java.sql.Date and java.sql.Timestamp have another calendar underneath–the hybrid calendar (Julian + Gregorian since 1582-10-15), which is the same as the legacy calendar used by Databricks Runtime 6.x and below. Due to different calendar systems, Spark has to perform additional operations during conversions to internal Spark SQL representations, and rebase input dates/timestamp from one calendar to another. The rebase operation has a little overhead for modern timestamps after the year 1900, and it can be more significant for old timestamps.
The following example shows how to make timestamps from Scala collections. The first example constructs a java.sql.Timestamp object from a string. The valueOf method interprets the input strings as a local timestamp in the default JVM time zone which can be different from Spark's session time zone. If you need to construct instances of java.sql.Timestamp or java.sql.Date in specific time zone, have a look at java.text.SimpleDateFormat (and its method setTimeZone) or java.util.Calendar.
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
Similarly, you can make a DATE column from collections of java.sql.Date or java.sql.LocalDate. Parallelization of java.sql.LocalDate instances is fully independent of either Spark's session or JVM default time zones, but the same is not true for parallelization of java.sql.Date instances. There are nuances:
java.sql.Dateinstances represent local dates at the default JVM time zone on the driver.- For correct conversions to Spark SQL values, the default JVM time zone on the driver and executors must be the same.
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
To avoid any calendar and time zone related issues, we recommend Java 8 types java.sql.LocalDate/Instant as external types in parallelization of Java/Scala collections of timestamps or dates.
Collect dates and timestamps
The reverse operation of parallelization is collecting dates and timestamps from executors back to the driver and returning a collection of external types. For example above, you can pull the DataFrame back to the driver using the collect() action:
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
Spark transfers internal values of dates and timestamps columns as time instants in the UTC time zone from executors to the driver, and performs conversions to Python datetime objects in the system time zone at the driver, not using Spark SQL session time zone. collect() is different from the show() action described in the previous section. show() uses the session time zone while converting timestamps to strings, and collects the resulted strings on the driver.
In Java and Scala APIs, Spark performs the following conversions by default:
- Spark SQL
DATEvalues are converted to instances ofjava.sql.Date. - Spark SQL
TIMESTAMPvalues are converted to instances ofjava.sql.Timestamp.
Both conversions are performed in the default JVM time zone on the driver. In this way, to have the same date-time fields that you can get using Date.getDay(), getHour(), and so on, and using Spark SQL functions DAY, HOUR, the default JVM time zone on the driver and the session time zone on executors should be the same.
Similarly to making dates/timestamps from java.sql.Date/Timestamp, Databricks Runtime 7.0 performs rebasing from the Proleptic Gregorian calendar to the hybrid calendar (Julian + Gregorian). This operation is almost free for modern dates (after the year 1582) and timestamps (after the year 1900), but it could bring some overhead for ancient dates and timestamps.
You can avoid such calendar-related issues, and ask Spark to return java.time types, which were added since Java 8. If you set the SQL config spark.sql.datetime.java8API.enabled to true, the Dataset.collect() action returns:
java.time.LocalDatefor Spark SQLDATEtypejava.time.Instantfor Spark SQLTIMESTAMPtype
Now the conversions don't suffer from the calendar-related issues because Java 8 types and Databricks Runtime 7.0 and above are both based on the Proleptic Gregorian calendar. The collect() action doesn't depend on the default JVM time zone. The timestamp conversions don't depend on time zone at all. Date conversions use the session time zone from the SQL config spark.sql.session.timeZone. For example, consider a Dataset with DATE and TIMESTAMP columns, with the default JVM time zone to set to Europe/Moscow and the session time zone set to America/Los_Angeles.
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
The show() action prints the timestamp at the session time America/Los_Angeles, but if you collect the Dataset, it is converted to java.sql.Timestamp and the toString method prints Europe/Moscow:
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
Actually, the local timestamp 2020-07-01 00:00:00 is 2020-07-01T07:00:00Z at UTC. You can observe that if you enable Java 8 API and collect the Dataset:
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
You can convert a java.time.Instant object to any local timestamp independently from the global JVM time zone. This is one of the advantages of java.time.Instant over java.sql.Timestamp. The former requires changing the global JVM setting, which influences other timestamps on the same JVM. Therefore, if your applications process dates or timestamps in different time zones, and the applications should not clash with each other while collecting data to the driver using Java or Scala Dataset.collect() API, we recommend switching to Java 8 API using the SQL config spark.sql.datetime.java8API.enabled.