Schema evolution in Databricks
Schema evolution refers to a system's ability to adapt to changes in the structure of data over time. These changes are common when working with semi-structured data, event streams, or third-party sources where new fields are added, data types shift, or nested structures evolve.
Common changes include:
- New columns: Additional fields not previously defined, sometimes with a custom backfill value.
- Column renaming: Changing a column name, for example, from
nametofull_name. - Dropped columns: Removing columns from the table schema.
- Type widening: Changing a column's type to a broader one. For example, an
INTfield becomingDOUBLE. - Other type changes: Changing a column's type. For example, an
INTfield becomingSTRING.
Supporting schema evolution is critical for building resilient, long-running pipelines that can accommodate changing data without frequent manual updates.
Components
Databricks schema evolution involves four main component categories, each handling schema changes independently:
- Connectors: Components that ingest data from external sources. These include Auto Loader, Kafka, Kinesis, and Lakeflow connectors.
- Format parsers: Functions that decode raw formats, including
from_json,from_avro,from_xml, andfrom_protobuf. - Engines: Processing engines that execute queries, including Structured Streaming.
- Datasets: Streaming tables, materialized views, Delta tables, and views that persist and serve data.
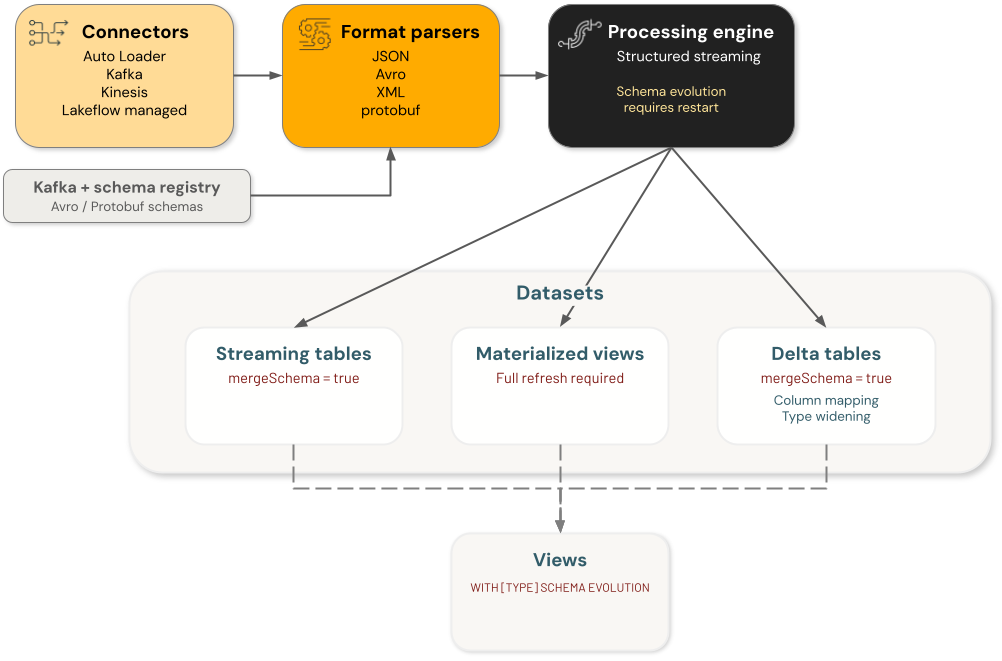
Each component in the data engineering architecture's schema evolution is independent. You are responsible for configuring schema evolution in individual components to achieve the desired behavior in your data processing flow.
For example, when using Auto Loader to ingest data into a Delta table, there are two persisted schemas: one is managed by Auto Loader in its schema location and the other is the schema of the target Delta table. In a stable state, those two are the same. When Auto Loader evolves its schema, based on incoming data, the Delta table must also evolve its schema, or the query fails. In that case, you can (a) update the target Delta table schema by enabling schema evolution or using a direct DDL command, or (b) do a full rewrite of the target Delta table.
Schema evolution support by connector
The following sections detail how each Databricks component handles different types of schema changes.
Auto Loader
Auto Loader supports column changes and type widening. Configure automatic schema evolution with cloudFiles.schemaEvolutionMode and rescuedDataColumn. You can manually set schemaHints or an immutable schema. When evolving the schema automatically, the stream initially fails. On restart, the evolved schema is used. See How does Auto Loader schema evolution work?.
- New columns: Supported, depending on the
schemaEvolutionModeselected. Fail with a manual restart required to add new columns to the schema. - Column renaming: Supported, depending on the
schemaEvolutionModeselected. The renamed column is treated as a new column added, and the old column is populated withNULLfor new rows. Fail with a manual restart required to update the schema. - Dropped columns: Supported. Treated as soft deletes, where new rows for the deleted column are set to
NULL. - Type widening: Supported in Databricks Runtime 16.4 and above with
schemaEvolutionModeset toaddNewColumnsWithTypeWidening. Supported data type changes are widened automatically. Unsupported type changes are captured in therescuedDataColumn. See Automatic type widening with Auto Loader. - Other type changes: Not supported. Type changes are captured in the
rescuedDataColumnifrescueDataColumnhas been set andschemaEvolutionModeset torescue. Otherwise, requires a manual schema change.
Delta connector
The Delta connector can support schema evolution. If reading from a Delta table with column mapping and schemaTrackingLocation enabled, it supports schema evolution for column renaming and dropped columns. You must set the correct Spark config for each of those respective changes to evolve the schema without stopping the stream. Otherwise, the stream evolves its tracked schema whenever a change is detected and then stops. You must then manually restart the streaming query to resume processing.
- New columns: Supported. With
mergeSchemaenabled, new columns are added automatically. Otherwise, the query fails and you must restart the stream to add the new columns to the schema, but the Delta table does not require a rewrite. - Column renaming: Supported. You can evolve schema within a streaming query with the Spark configuration
spark.databricks.delta.streaming.allowSourceColumnRename. - Dropped columns: Supported. You can evolve schema within a streaming query with the Spark configuration
spark.databricks.delta.streaming.allowSourceColumnDrop. - Type widening: Supported in Databricks Runtime 16.4 LTS and above. With
mergeSchemaenabled and type widening enabled on the target table, type changes are handled automatically. You can enable type widening with thedelta.enableTypeWideningtable property. See Type widening. - Other type changes: Not supported.
SaaS and CDC connectors
The SaaS and CDC connectors evolve the schema automatically when columns change. This is handled through an automatic restart when a change is detected. Type changes require a full refresh.
- New columns: Supported. The query automatically restarts to resolve schema mismatch.
- Column renaming: Supported. The query automatically restarts to resolve schema mismatch. The renamed column is treated as a new column added.
- Dropped columns: Supported. Dropped columns are treated as soft deletes, where new rows for the deleted column are set to
NULL. - Type widening: Not supported. Updating the schema requires a full refresh.
- Other type changes: Not supported. Updating the schema requires a full refresh.
Kinesis, Kafka, Pub/Sub, and Pulsar connectors
No native schema evolution supported. Each of the connector functions returns a binary blob. Schema evolution is handled by the format parser.
- New columns: Handled by the format parser.
- Column renaming: Handled by the format parser.
- Dropped columns: Handled by the format parser.
- Type widening: Handled by the format parser.
- Other type changes: Handled by the format parser.
Schema evolution support by format parser
from_json parser
The from_json parser does not support schema evolution. You must update the schema manually. When using from_json within Lakeflow pipelines, automatic schema evolution can be enabled with schemaLocationKey and schemaEvolutionMode.
- New columns: When automatic schema evolution is enabled, it behaves like Auto Loader.
- Columns renaming: When automatic schema evolution is enabled, it behaves like Auto Loader.
- Dropped columns: When automatic schema evolution is enabled, it behaves like Auto Loader.
- Type widening: When automatic schema evolution is enabled, it behaves like Auto Loader.
- Other type changes: When automatic schema evolution is enabled, it behaves like Auto Loader.
from_avro and from_protobuf parsers
The from_avro and from_protobuf parsers behave the same way. The schema can be fetched from the Confluent Schema Registry, or the user can provide a schema and must update the schema manually. There is no concept of schema evolution within the from_avro or from_protobuf function; it must be handled by the execution engine and Schema Registry.
- New columns: Supported with Confluent Schema Registry. Otherwise, user must update schema manually.
- Column renaming: Supported with Confluent Schema Registry. Otherwise, user must update schema manually.
- Dropped columns: Supported with Confluent Schema Registry. Otherwise, user must update schema manually.
- Type widening: Supported with Confluent Schema Registry. Otherwise, user must update schema manually.
- Other type changes: Supported with Confluent Schema Registry. Otherwise, user must update schema manually.
from_csv and from_xml parsers
The from_csv and from_xml parsers do not support schema evolution.
- New columns: Not supported
- Column renaming: Not supported
- Dropped columns: Not supported
- Type widening: Not supported
- Other type changes: Not supported
Schema evolution support by engine
Structured Streaming
A streaming query's schema is locked in during the planning phase, and all micro-batches reuse that plan without re-planning. If the source schema changes mid-execution, the query fails, and the user must restart the streaming query so Spark can re-plan against the new schema.
The dataset that the stream writes to must also support schema evolution.
- New columns: Supported. The query fails and you must restart the stream to resolve the schema mismatch.
- Column renaming: Supported. The query fails and you must restart the stream to resolve the schema mismatch.
- Dropped columns: Supported. The query fails and you must restart the stream to resolve the schema mismatch.
- Type widening: Supported. The query fails and you must restart the stream to resolve the schema mismatch.
- Other type changes: Supported. The query fails and you must restart the stream to resolve the schema mismatch.
Schema evolution by dataset
Streaming tables
Streaming tables support merge schema evolution behavior by default. Updating the schema does not require a manual restart but arbitrary schema changes require a full refresh.
- New columns: Supported. The query automatically restarts to resolve the schema mismatch.
- Column renaming: Supported. The query restarts to resolve the schema mismatch. The renamed column is treated as a new column added.
- Dropped columns: Supported. Dropped columns are treated as soft deletes, where new rows for the deleted column are set to NULL.
- Type widening: Supported. Type widening must be enabled either at the pipeline level or on the table directly. See type widening in Lakeflow pipelines.
- Other type changes: Not supported. Updating the schema requires a full refresh.
Materialized views
Any update to the schema or the defining query triggers a full recompute of the materialized view.
- New columns: Full recompute triggered.
- Column renaming: Full recompute triggered.
- Dropped columns: Full recompute triggered.
- Type widening: Full recompute triggered.
- Other type changes: Full recompute triggered.
Delta tables
Delta tables support a variety of configurations to update table schema, including renaming, dropping, and widening the type of columns without rewriting table data. Configurations supported include merge schema evolution, column mapping, type widening, and overwriteSchema.
- New columns: Supported. Auto-evolves when merge schema evolution is enabled, without requiring a Delta table rewrite. If merge schema evolution is not enabled, updates fail.
- Column renaming: Supported. Can rename through manual
ALTER TABLE DDLcommands with column mapping enabled. Does not require a Delta table rewrite. - Dropped columns: Supported. Can drop columns through manual
ALTER TABLE DDLcommands with column mapping enabled. Does not require a Delta table rewrite. - Type widening: Supported. Automatically applies type change when type widening and merge schema evolution are enabled. You can widen columns through manual
ALTER TABLE DDLcommands when type widening is enabled. Without either configured, operations fail. See Widen types with automatic schema evolution. - Other type changes: Supported, but requires a full rewrite of the Delta Table. You must enable
overwriteSchema, which enables a full rewrite of the Delta Table. Otherwise, operations fail.
Views
If the view has a column_list that doesn't match the new schema, or it has a query that can't be parsed, the view becomes invalid. If it doesn't, you can enable schema evolution for type changes with SCHEMA TYPE EVOLUTION and for type changes, as well as new, renamed, and dropped columns with SCHEMA EVOLUTION (which is a superset of type evolution).
- New columns: Supported. With
SCHEMA EVOLUTIONmode, the view auto-evolves without any manual intervention if there's no explicitcolumn_list. Otherwise, the view can become invalid and the user can't query it. - Columns renaming: Supported. With
SCHEMA EVOLUTIONmode, the view auto-evolves without any manual intervention if there's no explicitcolumn_list. Otherwise, the view can become invalid. - Dropped columns: Supported. With
SCHEMA EVOLUTIONmode, the view auto-evolves without any manual intervention if there's no explicitcolumn_list. Otherwise, the view can become invalid. - Type widening: Supported. With
SCHEMA TYPE EVOLUTIONmode, the view auto-evolves for any type changes. WithSCHEMA EVOLUTIONmode, the view auto-evolves without any manual intervention if there's no explicitcolumn_list. Otherwise, the view can become invalid. - Other type changes: Supported. With
SCHEMA TYPE EVOLUTIONmode, the view auto-evolves for any type changes. WithSCHEMA EVOLUTIONmode, the view auto-evolves without any manual intervention if there's no explicitcolumn_list. Otherwise, the view can become invalid.
Example
The following example shows how to ingest a Kafka topic with Avro-encoded payloads registered in Confluent Schema Registry, and write them to a managed Delta table with schema evolution enabled.
Key points illustrated:
- Integrate with the Kafka Connector.
- Decode Avro records using from_avro with a Kafka Schema Registry.
- Handle schema evolution by setting
avroSchemaEvolutionMode. - Write to a Delta table with
mergeSchemaenabled to allow additive changes.
The code assumes that you have a Kafka topic using Confluent schema registry, outputting Avro-encoded data.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)