Backfilling historical data with pipelines
In data engineering, backfilling refers to the process of retroactively processing historical data through a data pipeline that was designed for processing current or streaming data.
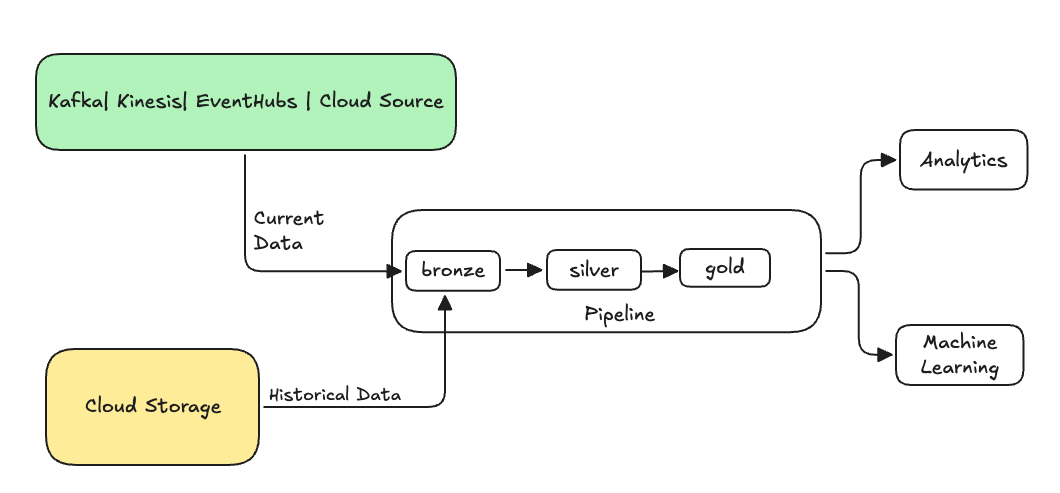
Typically, this is a separate flow sending data into your existing tables. The following illustration shows a backfill flow sending historical data to the bronze tables in your pipeline.
Some scenarios that might require a backfill:
- Process historical data from a legacy system to train a machine learning (ML) model or build a historical trend analysis dashboard.
- Reprocess a subset of data due to a data quality issue with upstream data sources.
- Your business requirements changed and you need to backfill data for a different time period that was not covered by the initial pipeline.
- Your business logic changed and you need to reprocess both historical and current data.
A backfill in Lakeflow Spark Declarative Pipelines is supported with a specialized append flow that uses the ONCE option. See append_flow or CREATE FLOW (pipelines) for more information about the ONCE option.
Considerations when backfilling historical data into a streaming table
- Typically, append the data to the bronze streaming table. Downstream silver and gold layers will pick up the new data from the bronze layer.
- Ensure your pipeline can handle duplicate data gracefully in case the same data is appended multiple times.
- Ensure the historical data schema is compatible with the current data schema.
- Consider the data volume size and the required processing time SLA, and accordingly configure the cluster and batch sizes.
Example: Adding a backfill to an existing pipeline
In this example, say you have a pipeline that ingests raw event registration data from a cloud storage source, starting Jan 01, 2025. You later realize that you want to backfill the previous three years of historical data for downstream reporting and analysis uses cases. All data is in one location, partitioned by year, month, and day, in JSON format.
Initial pipeline
Here's the starting pipeline code that incrementally ingests the raw event registration data from the cloud storage.
- Python
- SQL
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Here we use the modifiedAfter Auto Loader option to ensure we are not processing all data from the cloud storage path. The incremental processing is cutoff at that boundary.
Other data sources, such as Kafka, Kinesis, and Azure Event Hubs have equivalent reader options to achieve the same behavior.
Backfill data from previous 3 years
Now you want to add one or more flows to backfill previous data. In this example, take the following steps:
- Use the
append onceflow. This performs a one-time backfill without continuing to run after that first backfill. The code remains in your pipeline, and if the pipeline is ever fully refreshed, the backfill is re-run. - Create three backfill flows, one for each year (in this case, the data is split by year in the path). For Python, we parameterize the creation of the flows, but in SQL we repeat the code three times, once for each flow.
If you are working on your own project and not using serverless compute, you may want to update the max workers for the pipeline. Increasing the max workers ensures you have the resources to process the historical data while continuing to process the current streaming data within the expected SLA.
If you use serverless compute with enhanced autoscaling (the default), then your cluster automatically increases in size when your load increases.
- Python
- SQL
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
This implementation highlights several important patterns.
Separation of concerns
- Incremental processing is independent of backfill operations.
- Each flow has its own configuration and optimization settings.
- There is a clear distinction between incremental and backfill operations.
Controlled execution
- Using the
ONCEoption ensures that each backfill runs exactly once. - The backfill flow remains in the pipeline graph, but becomes idle after it's complete. It is ready for use on full refresh, automatically.
- There is a clear audit trail of backfill operations in the pipeline definition.
Processing optimization
- You can split the large backfill into multiple smaller backfills for faster processing, or for control of the processing.
- Using enhanced autoscaling dynamically scales the cluster size based on the current cluster load.
Schema evolution
- Using
schemaEvolutionMode="addNewColumns"handles schema changes gracefully. - You have consistent schema inference across historical and current data.
- There is safe handling of new columns in newer data.