Create a source-controlled pipeline
In Databricks, you can source control a pipeline and all of the code associated with it. By source controlling all files associated with your pipeline, changes to your transformation code, exploration code, and pipeline configuration are all versioned in Git and can be tested in development and confidently deployed to production.
A source-controlled pipeline offers the following advantages:
- Traceability: Capture every change in Git history.
- Testing: Validate pipeline changes in a development workspace before promoting to a shared production workspace. Every developer has their own development pipeline on their own code branch in a Git folder and in their own schema.
- Collaboration: When individual development and testing is finished, code changes are pushed to the main production pipeline.
- Governance: Align with enterprise CI/CD and deployment standards.
Databricks allows for pipelines and their source files to be source-controlled together using Declarative Automation Bundles. With bundles, pipeline configuration is source-controlled in the form of YAML configuration files alongside the Python or SQL source files of a pipeline. One bundle might have one or many pipelines, as well as other resource types, such as jobs.
This page shows how to set up a source-controlled pipeline using Declarative Automation Bundles (formerly known as Databricks Asset Bundles). For more information about bundles, see What are Declarative Automation Bundles?.
Requirements
To create a source-controlled pipeline, you must already have:
- A Git folder created in your workspace and configured. A Git folder allows individual users to author and test changes before committing them to a Git repository. See Databricks Git folders.
- The Lakeflow Pipelines Editor. See Develop and debug ETL pipelines with the Lakeflow Pipelines Editor for more information.
- For the full set of privileges required to create, run, refresh, and view pipelines and their output, see Manage identities, permissions, and privileges for pipelines.
Create a new pipeline in a bundle
Databricks recommends creating a pipeline that is source-controlled from the start. Alternatively, you can add an existing pipeline to a bundle that is already source-controlled. See Migrate existing resources to a bundle.
To create a new source-controlled pipeline:
-
At the top of the sidebar, click
 New and then select
New and then select  ETL pipeline.
ETL pipeline. -
Make any changes that you want to the pipeline name or schema. See Create a new ETL pipeline.
-
Click the
 menu (to the right of the
menu (to the right of the  Use sample code button) and select
Use sample code button) and select  Set up as source-controlled.
Set up as source-controlled. -
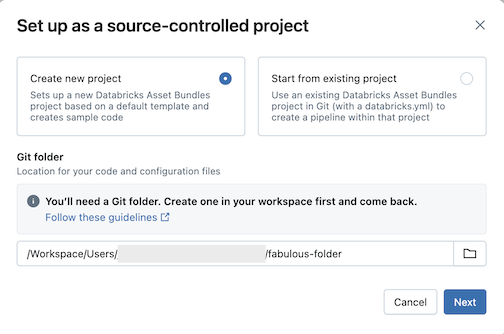
Click Create new project, then select a Git folder where you want to put your code and configuration:
-
Click Next.
-
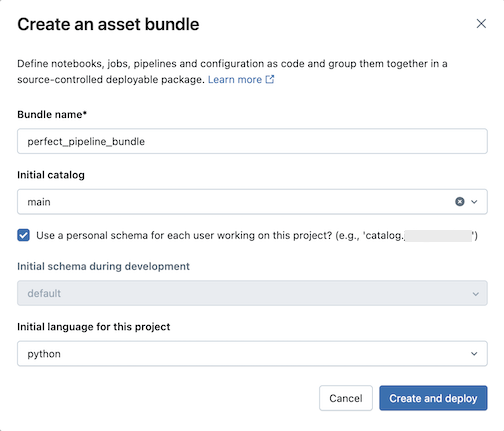
Enter the following in the Create an asset bundle dialog:
- Bundle name: The name of the bundle.
- Initial catalog: The name of the catalog that contains the schema to use.
- Use a personal schema: Leave this box checked if you want to isolate edits to a personal schema, so that when users in your organization collaborate on the same project you don't overwrite each other’s changes in dev.
- Initial language: The initial language to use for the project's sample pipeline files, either Python or SQL.
-
Click Create and deploy. A bundle with a pipeline is created in the Git folder.
Explore the pipeline bundle
Next, explore the pipeline bundle that was created.
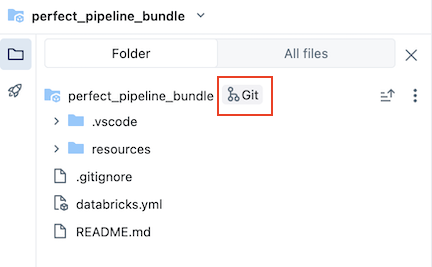
The bundle, which is in the Git folder, contains bundle system files and the databricks.yml file, which defines variables, target workspace URLs and permissions, and other settings for the bundle. Because databricks.yml lives in the bundle root (the parent of the pipeline root), switch to the All files tab in the pipeline asset browser to see it. The resources folder of a bundle is where definitions for resources such as pipelines and jobs are contained.
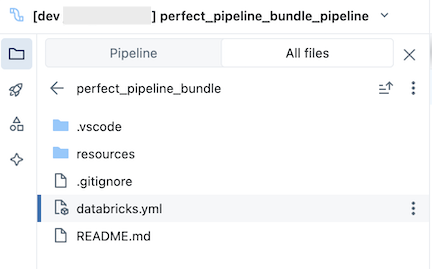
Open the resources folder, then click the pipeline editor button to view the source-controlled pipeline:
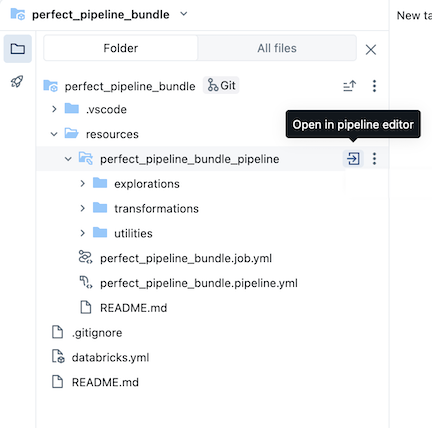
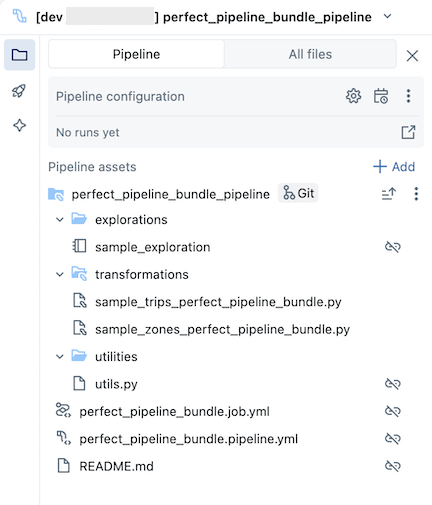
The sample pipeline bundle includes the following files:
-
A sample exploration notebook
-
Two sample code files that do transformations on tables
-
A sample code file that contains a utility function
-
A job configuration YAML file that defines the job in the bundle that runs the pipeline
-
A pipeline configuration YAML file that defines the pipeline
importantYou must edit this file to permanently persist any configuration changes to the pipeline, including changes made through the UI, otherwise UI changes are overridden when the bundle is redeployed. For example, to set a different default catalog for the pipeline, edit the
catalogfield in this configuration file. -
A README file with additional details about the sample pipeline bundle and instructions on how to run the pipeline
For information about pipeline files, see Pipeline asset browser.
For more information about authoring and deploying changes to the pipeline bundle, see Author bundles in the workspace and Deploy bundles and run workflows from the workspace.
Run the pipeline
You can run either individual transformations or the entire source-controlled pipeline:
- To run and preview a single transformation in the pipeline, select the transformation file in the workspace browser tree to open it in the file editor. At the top of the file in the editor, click the Run file play button.
- To run all transformations in the pipeline, click the Run pipeline button in the upper right of the Databricks workspace.
For more information about running pipelines, see Run pipeline code.
Update the pipeline
You can update artifacts in your pipeline or add additional explorations and transformations, but then you will want to push those changes to GitHub. Click the ![]() Git icon associated with the pipeline bundle or click the kebab for the folder then Git... to select which changes to push. See Commit and push changes.
Git icon associated with the pipeline bundle or click the kebab for the folder then Git... to select which changes to push. See Commit and push changes.
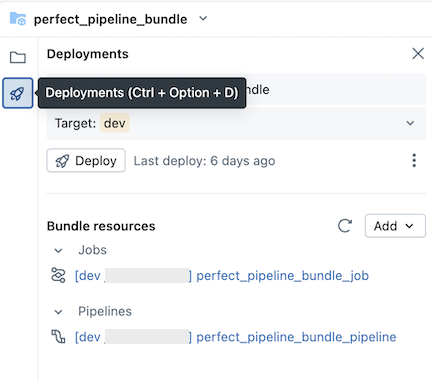
In addition, when you update pipeline configuration files or add or remove files from the bundle, these changes are not propagated to the target workspace until you explicitly deploy the bundle. See Deploy bundles and run workflows from the workspace.
Databricks recommends that you keep the default setup for source-controlled pipelines. The default setup is configured so that you do not need to edit the pipeline bundle YAML configuration when additional files are added through the UI.
Add an existing pipeline to a bundle
To add an existing pipeline to a bundle, first create a bundle in the workspace, then add the pipeline YAML definition to the bundle, as described in the following pages:
For information on how to migrate resources to a bundle using the Databricks CLI, see Migrate existing resources to a bundle.
Additional resources
For additional tutorials and reference material for pipelines, see Spark Declarative Pipelines.