Track and compare models using MLflow Logged Models
MLflow Logged Models help you track a model's progress throughout its lifecycle. When you train a model, use mlflow.<model-flavor>.log_model() to create a LoggedModel that ties together all of its critical information using a unique ID. To leverage the power of LoggedModels, get started with MLflow 3.
For GenAI applications, LoggedModels can be created to capture git commits or sets of parameters as dedicated objects that can then be linked to traces and metrics. In deep learning and classical ML, LoggedModels are produced from MLflow runs, which are existing concepts in MLflow and can be thought of as jobs that execute model code. Training runs produce models as outputs, and evaluation runs use existing models as input to produce metrics and other information you can use to assess the performance of a model.
The LoggedModel object persists throughout the model's lifecycle, across different environments, and contains links to artifacts such as metadata, metrics, parameters, and the code used to generate the model. Logged Model tracking lets you compare models against each other, find the most performant model, and track down information during debugging.
Logged Models can also be registered to the Unity Catalog model registry, making information about the model from all MLflow experiments and workspaces available in a single location. For more details, see Model Registry improvements with MLflow 3.
![]()
Improved tracking for gen AI and deep learning models
Generative AI and deep learning workflows especially benefit from the granular tracking that Logged Models provides.
Gen AI - unified evaluation and trace data:
- Gen AI models generate additional metrics during evaluation and deployment, such as reviewer feedback data and traces.
- The
LoggedModelentity allows you to query all the information generated by a model using a single interface.
Deep learning - efficient checkpoint management:
- Deep learning training creates multiple checkpoints, which are snapshots of the model's state at a particular point during training.
- MLflow creates a separate
LoggedModelfor each checkpoint, containing the model's metrics and performance data. This allows you to compare and evaluate checkpoints to identify the best-performing models efficiently.
Create a Logged Model
To create a Logged Model, use the same log_model() API as existing MLflow workloads. The following code snippets show how to create a Logged Model for gen AI, deep learning, and traditional ML workflows.
For complete, runnable notebook examples, see Example notebooks.
- Gen AI
- Deep learning
- Traditional ML
The following code snippet shows how to log a LangChain agent. Use the log_model() method for your flavor of agent.
# Log the chain with MLflow, specifying its parameters
# As a new feature, the LoggedModel entity is linked to its name and params
model_info = mlflow.langchain.log_model(
lc_model=chain,
name="basic_chain",
params={
"temperature": 0.1,
"max_tokens": 2000,
"prompt_template": str(prompt)
},
model_type="agent",
input_example={"messages": "What is MLflow?"},
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
Start an evaluation job and link the metrics to a Logged Model by providing the unique model_id for the LoggedModel:
# Start a run to represent the evaluation job
with mlflow.start_run() as evaluation_run:
eval_dataset: mlflow.entities.Dataset = mlflow.data.from_pandas(
df=eval_df,
name="eval_dataset",
)
# Run the agent evaluation
result = mlflow.evaluate(
model=f"models:/{logged_model.model_id}",
data=eval_dataset,
model_type="databricks-agent"
)
# Log evaluation metrics and associate with agent
mlflow.log_metrics(
metrics=result.metrics,
dataset=eval_dataset,
# Specify the ID of the agent logged above
model_id=logged_model.model_id
)
The following code snippet shows how to create Logged Models during deep learning training. Use the log_model() method for your flavor of MLflow model.
# Start a run to represent the training job
with mlflow.start_run():
# Load the training dataset with MLflow. We will link training metrics to this dataset.
train_dataset: Dataset = mlflow.data.from_pandas(train_df, name="train")
X_train, y_train = prepare_data(train_dataset.df)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(scripted_model.parameters(), lr=0.01)
for epoch in range(101):
X_train, y_train = X_train.to(device), y_train.to(device)
out = scripted_model(X_train)
loss = criterion(out, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Obtain input and output examples for MLflow Model signature creation
with torch.no_grad():
input_example = X_train[:1]
output_example = scripted_model(input_example)
# Log a checkpoint with metrics every 10 epochs
if epoch % 10 == 0:
# Each newly created LoggedModel checkpoint is linked with its
# name, params, and step
model_info = mlflow.pytorch.log_model(
pytorch_model=scripted_model,
name=f"torch-iris-{epoch}",
params={
"n_layers": 3,
"activation": "ReLU",
"criterion": "CrossEntropyLoss",
"optimizer": "Adam"
},
step=epoch,
signature=mlflow.models.infer_signature(
model_input=input_example.cpu().numpy(),
model_output=output_example.cpu().numpy(),
),
input_example=X_train.cpu().numpy(),
)
# Log metric on training dataset at step and link to LoggedModel
mlflow.log_metric(
key="accuracy",
value=compute_accuracy(scripted_model, X_train, y_train),
step=epoch,
model_id=model_info.model_id,
dataset=train_dataset
)
The following code snippet shows how to log a sklearn model and link metrics to the Logged Model. Use the log_model() method for your flavor of MLflow model.
## Log the model
model_info = mlflow.sklearn.log_model(
sk_model=lr,
name="elasticnet",
params={
"alpha": 0.5,
"l1_ratio": 0.5,
},
input_example = train_x
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
# Evaluate the model on the training dataset and log metrics
# These metrics are now linked to the LoggedModel entity
predictions = lr.predict(train_x)
(rmse, mae, r2) = compute_metrics(train_y, predictions)
mlflow.log_metrics(
metrics={
"rmse": rmse,
"r2": r2,
"mae": mae,
},
model_id=logged_model.model_id,
dataset=train_dataset
)
Example notebooks
For example notebooks that illustrate the use of LoggedModels, see the following pages:
View models and track progress
You can view your Logged Models in the workspace UI:
- Go to the Experiments tab in your workspace.
- Select an experiment. Then, select the Models tab.
This page contains all the Logged Models associated with the experiment, along with their metrics, parameters, and artifacts.
![]()
You can generate charts to track metrics across runs.
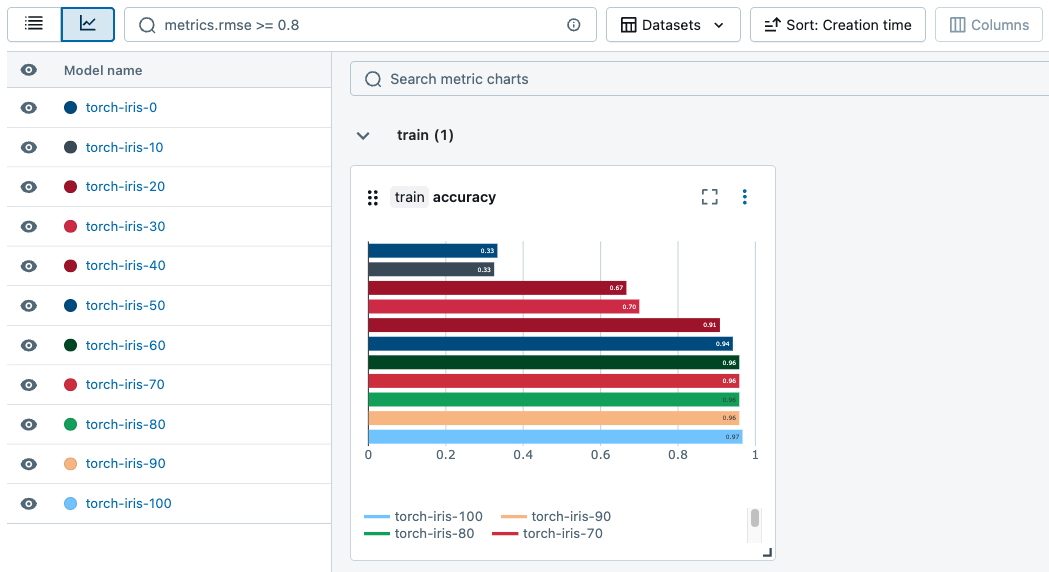
Search and filter Logged Models
From the Models tab, you can search and filter Logged Models based on their attributes, parameters, tags, and metrics.
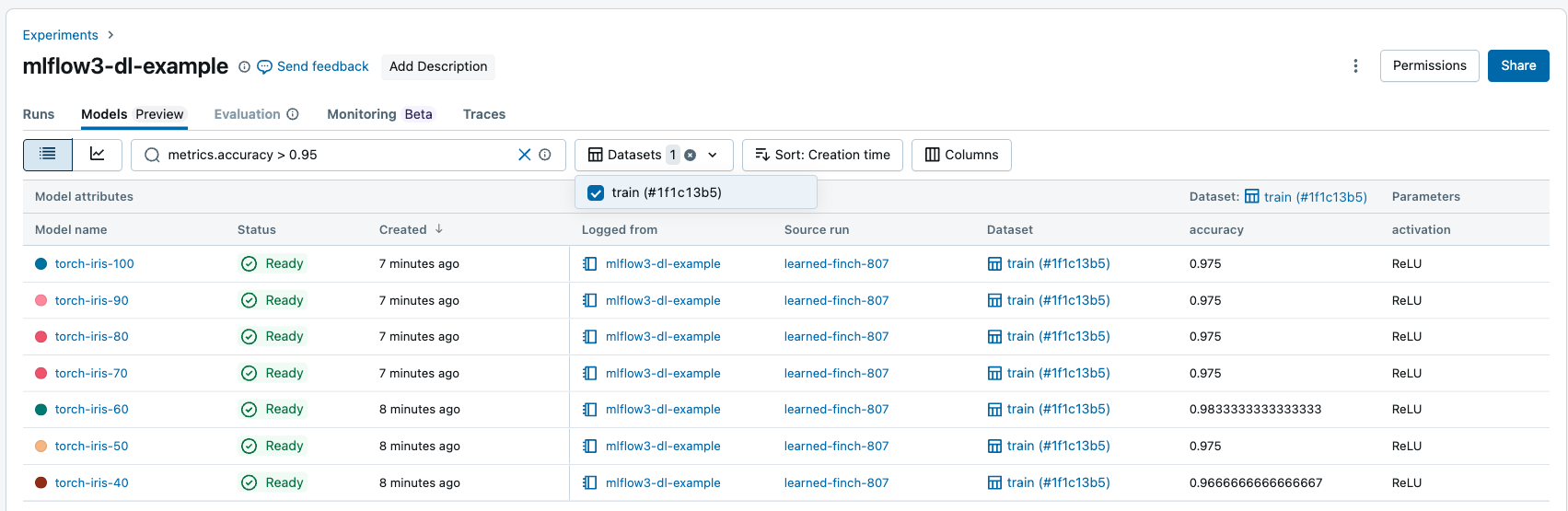
You can filter metrics based on dataset-specific performance, and only models with matching metric values on the given datasets are returned. If dataset filters are provided without any metric filters, models with any metrics on those datasets are returned.
You can filter based on the following attributes:
model_idmodel_namestatusartifact_uricreation_time(numeric)last_updated_time(numeric)
Use the following operators to search and filter string-like attributes, parameters, and tags:
=,!=,IN,NOT IN
Use the following comparison operators to search and filter numeric attributes and metrics,:
=,!=,>,<,>=,<=
Search Logged Models programmatically
You can search for Logged Models using the MLflow API:
## Get a Logged Model using a model_id
mlflow.get_logged_model(model_id = <my-model-id>)
## Get all Logged Models that you have access to
mlflow.search_logged_models()
## Get all Logged Models with a specific name
mlflow.search_logged_models(
filter_string = "model_name = <my-model-name>"
)
## Get all Logged Models created within a certain time range
mlflow.search_logged_models(
filter_string = "creation_time >= <creation_time_start> AND creation_time <= <creation_time_end>"
)
## Get all Logged Models with a specific param value
mlflow.search_logged_models(
filter_string = "params.<param_name> = <param_value_1>"
)
## Get all Logged Models with specific tag values
mlflow.search_logged_models(
filter_string = "tags.<tag_name> IN (<tag_value_1>, <tag_value_2>)"
)
## Get all Logged Models greater than a specific metric value on a dataset, then order by that metric value
mlflow.search_logged_models(
filter_string = "metrics.<metric_name> >= <metric_value>",
datasets = [
{"dataset_name": <dataset_name>, "dataset_digest": <dataset_digest>}
],
order_by = [
{"field_name": metrics.<metric_name>, "dataset_name": <dataset_name>,"dataset_digest": <dataset_digest>}
]
)
For more information and additional search parameters see the MLflow 3 API documentation.
Search runs by model inputs and outputs
You can search runs by model ID to return all runs that have the Logged Model as an input or output. For more information on the filter string syntax, see filtering for runs.
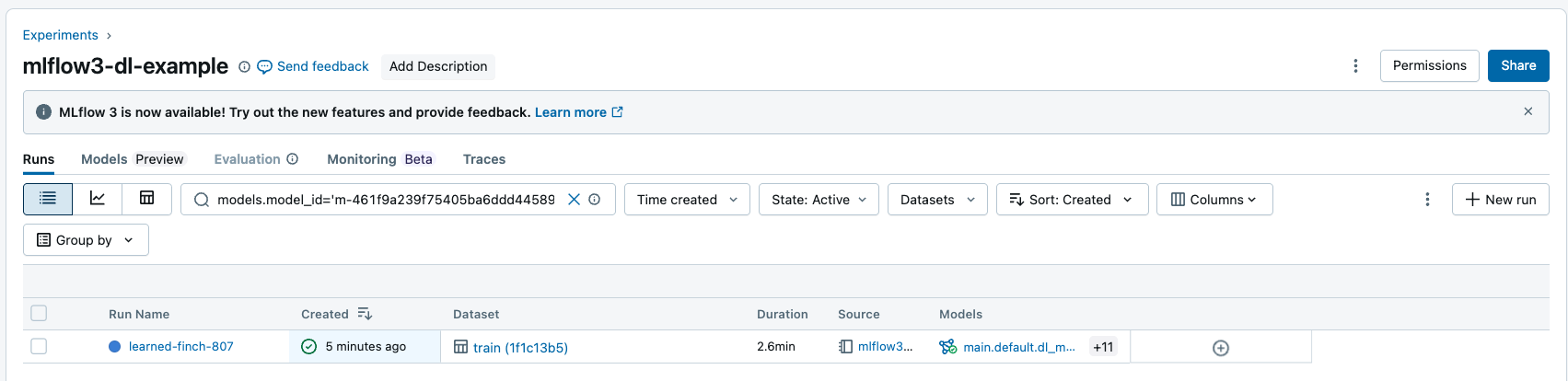
You can search for runs using the MLflow API:
## Get all Runs with a particular model as an input or output by model id
mlflow.search_runs(filter_string = "models.model_id = <my-model-id>")
Additional resources
To learn more about other new features of MLflow 3, see the following articles: