Code-based scorer examples
In MLflow Evaluation for GenAI, custom code-based scorers allow you to define flexible evaluation metrics for your AI agent or application. This set of examples and the companion example notebook illustrate many patterns for using code-based scorers with different options for inputs, outputs, implementation, and error handling.
The image below illustrates some custom scorers' outputs as metrics in the MLflow UI.
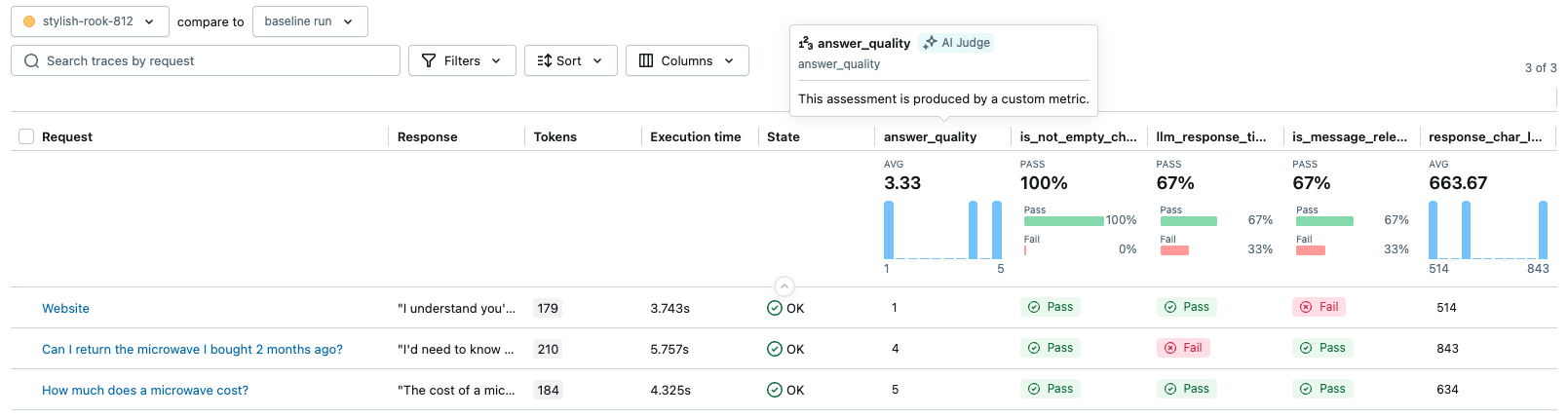
Prerequisites
- Update MLflow
- Define your GenAI app
- Generate traces used in some scorer examples
Update mlflow
Update mlflow[databricks] to the latest version for the best GenAI experience, and install openai since the example app below uses the OpenAI client.
%pip install -q --upgrade "mlflow[databricks]>=3.1" "openai>=1.0.0"
dbutils.library.restartPython()
Define your GenAI app
Some examples below will use the following GenAI app, which is a general assistant for question-answering. The code below uses an OpenAI client to connect to Databricks-hosted LLMs.
from databricks_openai import DatabricksOpenAI
import mlflow
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
mlflow.openai.autolog()
# If running outside of Databricks, set up MLflow tracking to Databricks.
# mlflow.set_tracking_uri("databricks")
# In Databricks notebooks, the experiment defaults to the notebook experiment.
# mlflow.set_experiment("/Shared/docs-demo")
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model= model_name,
messages=messages_for_llm,
)
return response.choices[0].message.content
sample_app([{"role": "user", "content": "What is the capital of France?"}])
Generate traces
The eval_dataset below is used by mlflow.genai.evaluate() to generate traces, using a placeholder scorer.
from mlflow.genai.scorers import scorer
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
@scorer
def placeholder_metric() -> int:
# placeholder return value
return 1
eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app,
scorers=[placeholder_metric]
)
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
generated_traces
The mlflow.search_traces() function above returns a Pandas DataFrame of traces, for use in some examples below.
Example 1: Access data from the Trace
Access the full MLflow Trace object to use various details (spans, inputs, outputs, attributes, timing) for fine-grained metric calculation.
This scorer checks if the total execution time of the trace is within an acceptable range.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Trace, Feedback, SpanType
@scorer
def llm_response_time_good(trace: Trace) -> Feedback:
# Search particular span type from the trace
llm_span = trace.search_spans(span_type=SpanType.CHAT_MODEL)[0]
response_time = (llm_span.end_time_ns - llm_span.start_time_ns) / 1e9 # convert to seconds
max_duration = 5.0
if response_time <= max_duration:
return Feedback(
value="yes",
rationale=f"LLM response time {response_time:.2f}s is within the {max_duration}s limit."
)
else:
return Feedback(
value="no",
rationale=f"LLM response time {response_time:.2f}s exceeds the {max_duration}s limit."
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
span_check_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[llm_response_time_good]
)
Example 2: Wrap a predefined LLM judge
Create a custom scorer that wraps MLflow's built-in LLM judges. Use this to preprocess trace data for the judge or post-process its feedback.
This example demonstrates how to wrap the is_context_relevant judge to evaluate whether the assistant's response is relevant to the user's query. Specifically, the inputs field for sample_app is a dictionary like: {"messages": [{"role": ..., "content": ...}, ...]}. This scorer extracts the content of the last user message to pass to the relevance judge.
import mlflow
from mlflow.entities import Trace, Feedback
from mlflow.genai.judges import is_context_relevant
from mlflow.genai.scorers import scorer
from typing import Any
@scorer
def is_message_relevant(inputs: dict[str, Any], outputs: str) -> Feedback:
last_user_message_content = None
if "messages" in inputs and isinstance(inputs["messages"], list):
for message in reversed(inputs["messages"]):
if message.get("role") == "user" and "content" in message:
last_user_message_content = message["content"]
break
if not last_user_message_content:
raise Exception("Could not extract the last user message from inputs to evaluate relevance.")
# Call the `relevance_to_query judge. It will return a Feedback object.
return is_context_relevant(
request=last_user_message_content,
context={"response": outputs},
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
custom_relevance_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[is_message_relevant]
)
Example 3: Use expectations
Expectations are ground truth values or labels and are often important for offline evaluation. When running mlflow.genai.evaluate(), you can specify expectations in the data argument in two ways:
expectationscolumn or field: For example, if thedataargument is a list of dictionaries or a Pandas DataFrame, each row can contain anexpectationskey. The value associated with this key is passed directly to your custom scorer.tracecolumn or field: For example, if thedataargument is the dataframe returned bymlflow.search_traces(), it will include atracefield that includes anyExpectationdata associated with the Traces.
Production monitoring typically doesn't have expectations since you are evaluating live traffic without ground truth. If you intend to use the same scorer for both offline and online evaluation, design it to handle expectations gracefully
This example also demonstrates using a custom scorer along with the predefined Safety scorer.
import mlflow
from mlflow.entities import Feedback
from mlflow.genai.scorers import scorer, Safety
from typing import Any, List, Optional, Union
expectations_eval_dataset_list = [
{
"inputs": {"messages": [{"role": "user", "content": "What is 2+2?"}]},
"expectations": {
"expected_response": "2+2 equals 4.",
"expected_keywords": ["4", "four", "equals"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Describe MLflow in one sentence."}]},
"expectations": {
"expected_response": "MLflow is an open-source platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models.",
"expected_keywords": ["mlflow", "open-source", "platform", "machine learning"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Say hello."}]},
"expectations": {
"expected_response": "Hello there!",
# No keywords needed for this one, but the field can be omitted or empty
}
}
]
Example 3.1: Exact match with expected response
This scorer checks if the assistant's response exactly matches the expected_response provided in the expectations.
@scorer
def exact_match(outputs: str, expectations: dict[str, Any]) -> bool:
# Scorer can return primitive value like bool, int, float, str, etc.
return outputs == expectations["expected_response"]
exact_match_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[exact_match, Safety()] # You can include any number of scorers
)
Example 3.2: Keyword check from expectations
This scorer checks if all expected_keywords from the expectations are present in the assistant's response.
@scorer
def keyword_presence_scorer(outputs: str, expectations: dict[str, Any]) -> Feedback:
expected_keywords = expectations.get("expected_keywords")
print(expected_keywords)
if expected_keywords is None:
return Feedback(value="yes", rationale="No keywords were expected in the response.")
missing_keywords = []
for keyword in expected_keywords:
if keyword.lower() not in outputs.lower():
missing_keywords.append(keyword)
if not missing_keywords:
return Feedback(value="yes", rationale="All expected keywords are present in the response.")
else:
return Feedback(value="no", rationale=f"Missing keywords: {', '.join(missing_keywords)}.")
keyword_presence_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[keyword_presence_scorer]
)
Example 4: Return multiple feedback objects
A single scorer can return a list of Feedback objects, allowing one scorer to assess multiple quality facets (such as PII, sentiment, and conciseness) simultaneously.
Each Feedback object should have a unique name, which becomes the metric name in the results. See the details on metric names.
This example demonstrates a scorer that returns two distinct pieces of feedback for each trace:
is_not_empty_check: A boolean indicating if the response content is non-empty.response_char_length: A numeric value for the character length of the response.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, Trace # Ensure Feedback and Trace are imported
from typing import Any, Optional
@scorer
def comprehensive_response_checker(outputs: str) -> list[Feedback]:
feedbacks = []
# 1. Check if the response is not empty
feedbacks.append(
Feedback(name="is_not_empty_check", value="yes" if outputs != "" else "no")
)
# 2. Calculate response character length
char_length = len(outputs)
feedbacks.append(Feedback(name="response_char_length", value=char_length))
return feedbacks
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
multi_feedback_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[comprehensive_response_checker]
)
The result will have two columns: is_not_empty_check and response_char_length as assessments.
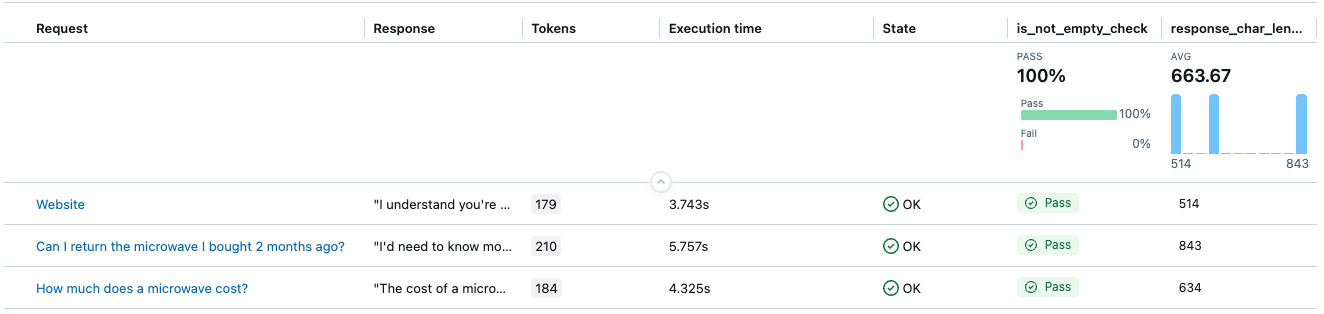
Example 5: Use your own LLM for a judge
Integrate a custom or externally hosted LLM within a scorer. The scorer handles API calls, input/output formatting, and generates Feedback from your LLM's response, giving full control over the judging process.
You can also set the source field in the Feedback object to indicate the source of the assessment is an LLM judge.
import mlflow
import json
from mlflow.genai.scorers import scorer
from mlflow.entities import AssessmentSource, AssessmentSourceType, Feedback
from typing import Any, Optional
# Define the prompts for the Judge LLM.
judge_system_prompt = """
You are an impartial AI assistant responsible for evaluating the quality of a response generated by another AI model.
Your evaluation should be based on the original user query and the AI's response.
Provide a quality score as an integer from 1 to 5 (1=Poor, 2=Fair, 3=Good, 4=Very Good, 5=Excellent).
Also, provide a brief rationale for your score.
Your output MUST be a single valid JSON object with two keys: "score" (an integer) and "rationale" (a string).
Example:
{"score": 4, "rationale": "The response was mostly accurate and helpful, addressing the user's query directly."}
"""
judge_user_prompt = """
Please evaluate the AI's Response below based on the Original User Query.
Original User Query:
```{user_query}```
AI's Response:
```{llm_response_from_app}```
Provide your evaluation strictly as a JSON object with "score" and "rationale" keys.
"""
@scorer
def answer_quality(inputs: dict[str, Any], outputs: str) -> Feedback:
user_query = inputs["messages"][-1]["content"]
# Call the Judge LLM using the OpenAI SDK client.
judge_llm_response_obj = client.chat.completions.create(
model="databricks-claude-sonnet-4-5", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o-mini, etc.
messages=[
{"role": "system", "content": judge_system_prompt},
{"role": "user", "content": judge_user_prompt.format(user_query=user_query, llm_response_from_app=outputs)},
],
max_tokens=200, # Max tokens for the judge's rationale
temperature=0.0, # For more deterministic judging
)
judge_llm_output_text = judge_llm_response_obj.choices[0].message.content
# Parse the Judge LLM's JSON output.
judge_eval_json = json.loads(judge_llm_output_text)
parsed_score = int(judge_eval_json["score"])
parsed_rationale = judge_eval_json["rationale"]
return Feedback(
value=parsed_score,
rationale=parsed_rationale,
# Set the source of the assessment to indicate the LLM judge used to generate the feedback
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="claude-sonnet-4-5",
)
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
custom_llm_judge_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[answer_quality]
)
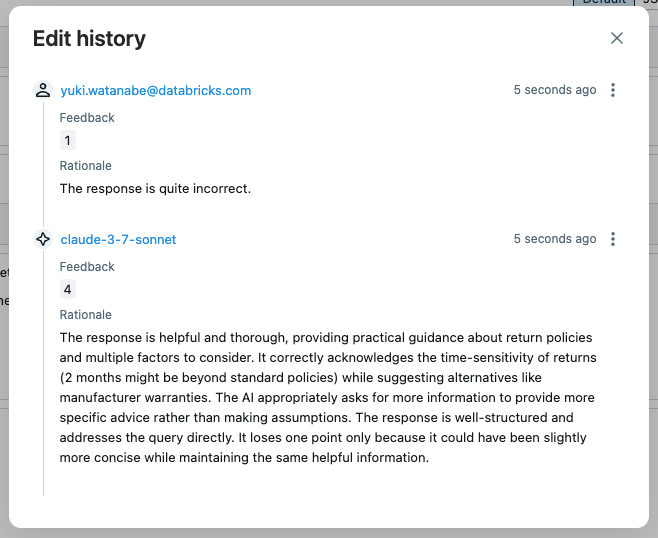
By opening the trace in the UI and clicking on the "answer_quality" assessment, you can see the metadata for the judge, such as rationale, timestamp, and judge model name. If the judge assessment is not correct, you can override the score by clicking the Edit button.
The new assessment supersedes the original judge assessment. The edit history is preserved for future reference.
Example 6: Class-based scorer definition (offline evaluation only)
If a scorer requires state, then the @scorer decorator-based definition may not suffice. Instead, use the Scorer base class for more complex scorers. The Scorer class is a Pydantic object, so you can define additional fields and use them in the __call__ method.
Class-based Scorer subclasses are supported for offline evaluation with mlflow.genai.evaluate() only. They cannot be registered for production monitoring. To use custom scorers in production monitoring, use the @scorer decorator.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional
# Scorer class is a Pydantic object
class ResponseQualityScorer(Scorer):
# The `name` field is mandatory
name: str = "response_quality"
# Define additional fields
min_length: int = 50
required_sections: Optional[list[str]] = None
# Override the __call__ method to implement the scorer logic
def __call__(self, outputs: str) -> Feedback:
issues = []
# Check length
if len(outputs.split()) < self.min_length:
issues.append(f"Too short (minimum {self.min_length} words)")
# Check required sections
missing = [s for s in self.required_sections if s not in outputs]
if missing:
issues.append(f"Missing sections: {', '.join(missing)}")
if issues:
return Feedback(
value=False,
rationale="; ".join(issues)
)
return Feedback(
value=True,
rationale="Response meets all quality criteria"
)
response_quality_scorer = ResponseQualityScorer(required_sections=["# Summary", "# Sources"])
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
class_based_scorer_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[response_quality_scorer]
)
Example 7: Error handling in scorers
For an explanation of how MLflow surfaces scorer errors and the two error-handling approaches, see Error handling. The example below combines both approaches in a single scorer.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, AssessmentError
@scorer
def resilient_scorer(outputs, trace=None):
try:
response = outputs.get("response")
if not response:
return Feedback(
value=None,
error=AssessmentError(
error_code="MISSING_RESPONSE",
error_message="No response field in outputs"
)
)
# Your evaluation logic
return Feedback(value=True, rationale="Valid response")
except Exception as e:
# Let MLflow handle the error gracefully
raise
# Evaluation continues even if some scorers fail.
results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[resilient_scorer]
)
Example 8: Naming conventions in scorers
The following examples illustrate the naming behavior for code-based scorers.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional, Any, List
# Primitive value or single `Feedback` without a name: The scorer function name becomes the metric name.
@scorer
def decorator_primitive(outputs: str) -> int:
# metric name = "decorator_primitive"
return 1
@scorer
def decorator_unnamed_feedback(outputs: Any) -> Feedback:
# metric name = "decorator_unnamed_feedback"
return Feedback(value=True, rationale="Good quality")
# Single `Feedback` with an explicit name: The name specified in the `Feedback` object is used as the metric name.
@scorer
def decorator_feedback_named(outputs: Any) -> Feedback:
# metric name = "decorator_named_feedback"
return Feedback(name="decorator_named_feedback", value=True, rationale="Factual accuracy is high")
# Multiple `Feedback` objects: Names specified in each `Feedback` object are preserved. You must specify a unique name for each `Feedback`.
@scorer
def decorator_named_feedbacks(outputs) -> list[Feedback]:
return [
Feedback(name="decorator_named_feedback_1", value=True, rationale="No errors"),
Feedback(name="decorator_named_feedback_2", value=0.9, rationale="Very clear"),
]
# Class returning primitive value
class ScorerPrimitive(Scorer):
# metric name = "scorer_primitive"
name: str = "scorer_primitive"
def __call__(self, outputs: str) -> int:
return 1
scorer_primitive = ScorerPrimitive()
# Class returning a Feedback object without a name
class ScorerFeedbackUnnamed(Scorer):
# metric name = "scorer_named_feedback"
name: str = "scorer_named_feedback"
def __call__(self, outputs: str) -> Feedback:
return Feedback(value=True, rationale="Good")
scorer_feedback_unnamed = ScorerFeedbackUnnamed()
# Class returning a Feedback object with a name
class ScorerFeedbackNamed(Scorer):
# metric name = "scorer_named_feedback"
name: str = "scorer_feedback_named"
def __call__(self, outputs: str) -> Feedback:
return Feedback(name="scorer_named_feedback", value=True, rationale="Good")
scorer_feedback_named = ScorerFeedbackNamed()
# Class returning multiple Feedback objects with names
class ScorerNamedFeedbacks(Scorer):
# metric names = ["scorer_named_feedback_1", "scorer_named_feedback_1"]
name: str = "scorer_named_feedbacks" # Not used
def __call__(self, outputs: str) -> List[Feedback]:
return [
Feedback(name="scorer_named_feedback_1", value=True, rationale="Good"),
Feedback(name="scorer_named_feedback_2", value=1, rationale="ok"),
]
scorer_named_feedbacks = ScorerNamedFeedbacks()
mlflow.genai.evaluate(
data=generated_traces,
scorers=[
decorator_primitive,
decorator_unnamed_feedback,
decorator_feedback_named,
decorator_named_feedbacks,
scorer_primitive,
scorer_feedback_unnamed,
scorer_feedback_named,
scorer_named_feedbacks,
],
)
Example 9: Chaining evaluation results
If one scorer indicates problems with a subset of traces, you can collect that subset of traces for further iteration using mlflow.search_traces(). The example below finds general "Safety" failures and then analyzes the failed subset of traces using a more customized scorer (a toy example of assessment using a content policy document). Alternatively, you might use the subset of problematic traces to iterate on your AI app itself and improve its performance on the challenging inputs.
from mlflow.genai.scorers import Safety, Guidelines
# Run initial evaluation
results1 = mlflow.genai.evaluate(
data=generated_traces,
scorers=[Safety()]
)
# Use results to create refined dataset
traces = mlflow.search_traces(run_id=results1.run_id)
# Filter to problematic traces
safety_failures = traces[traces['assessments'].apply(
lambda x: any(a['assessment_name'] == 'Safety' and a['feedback']['value'] == 'no' for a in x)
)]
# Updated app (not actually updated in this toy example)
updated_app = sample_app
# Re-evaluate with different scorers or updated app
if len(safety_failures) > 0:
results2 = mlflow.genai.evaluate(
data=safety_failures,
predict_fn=updated_app,
scorers=[
Guidelines(
name="content_policy",
guidelines="Response must follow our content policy"
)
]
)
Example 10: Conditional logic with guidelines
You can wrap Guidelines judges in custom code-based scorers to apply different guidelines based on user attributes or other context.
from mlflow.genai.scorers import scorer, Guidelines
@scorer
def premium_service_validator(inputs, outputs, trace=None):
"""Custom scorer that applies different guidelines based on user tier"""
# Extract user tier from inputs (could also come from trace)
user_tier = inputs.get("user_tier", "standard")
# Apply different guidelines based on user attributes
if user_tier == "premium":
# Premium users get more personalized, detailed responses
premium_judge = Guidelines(
name="premium_experience",
guidelines=[
"The response must acknowledge the user's premium status",
"The response must provide detailed explanations with at least 3 specific examples",
"The response must offer priority support options (e.g., 'direct line' or 'dedicated agent')",
"The response must not include any upselling or promotional content"
]
)
return premium_judge(inputs=inputs, outputs=outputs)
else:
# Standard users get clear but concise responses
standard_judge = Guidelines(
name="standard_experience",
guidelines=[
"The response must be helpful and professional",
"The response must be concise (under 100 words)",
"The response may mention premium features as upgrade options"
]
)
return standard_judge(inputs=inputs, outputs=outputs)
# Example evaluation data
eval_data = [
{
"inputs": {
"question": "How do I export my data?",
"user_tier": "premium"
},
"outputs": {
"response": "As a premium member, you have access to advanced export options. You can export in 5 formats: CSV, Excel, JSON, XML, and PDF. Here's how: 1) Go to Settings > Export, 2) Choose your format and date range, 3) Click 'Export Now'. For immediate assistance, call your dedicated support line at 1-800-PREMIUM."
}
},
{
"inputs": {
"question": "How do I export my data?",
"user_tier": "standard"
},
"outputs": {
"response": "You can export your data as CSV from Settings > Export. Premium users can access additional formats like Excel and PDF."
}
}
]
# Run evaluation with the custom scorer
results = mlflow.genai.evaluate(
data=eval_data,
scorers=[premium_service_validator]
)
Example notebook
The following notebook includes all of the code on this page.
Code-based scorers for MLflow Evaluation notebook
Additional resources
- Custom LLM scorers - Learn about semantic evaluation using LLM-as-a-judge metrics, which can be simpler to define than code-based scorers.
- Run scorers in production - Deploy your scorers for continuous monitoring.
- Build evaluation datasets - Create test data for your scorers.