Evaluate GenAI apps during development
The mlflow.genai.evaluate() function provides an evaluation harness for GenAI applications. Instead of manually running your app and checking outputs one by one, MLflow Evaluation provides a structured way to feed in test data, run your app, and automatically score the results. This makes it easier to compare versions, track improvements, and share results across teams.
MLflow Evaluation connects offline testing with production monitoring. That means the same evaluation logic you use in development can also run in production, giving you a consistent view of quality across the entire AI lifecycle.
The mlflow.genai.evaluate() function systematically tests GenAI app quality by running it against test data (evaluation datasets and applying scorers).
If you are new to evaluation, start with 10-minute demo: Evaluate an AI app.
When to use
- Nightly or weekly checks of your app against curated evaluation datasets
- Validating prompt or model changes across app versions
- Before a release or PR to prevent quality regressions
Quick reference
The mlflow.genai.evaluate() function runs your GenAI app against an evaluation dataset using specified scorers and optionally a prediction function or model ID, returning an EvaluationResult.
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
- For API details, see Parameters for
mlflow.genai.evaluate()or the MLflow documentation. - For details on
EvaluationDataset, see Building MLflow evaluation datasets. - For details on evaluation runs and logging, see Evaluation runs in MLflow.
Requirements
-
Install MLflow and required packages.
Bashpip install --upgrade "mlflow[databricks]>=3.1.0" openai "databricks-connect>=16.1" -
Create an MLflow experiment by following the setup your environment quickstart.
(Optional) Configure parallelization
MLflow by default uses background threadpool to speed up the evaluation process. To configure the number of workers, set the environment variable MLFLOW_GENAI_EVAL_MAX_WORKERS.
export MLFLOW_GENAI_EVAL_MAX_WORKERS=10
Evaluation modes
There are two evaluation modes:
-
Direct evaluation (recommended). MLflow calls your app directly to generate traces for evaluation:
- Runs your app on test inputs, capturing traces.
- Applies scorers or LLM judges to assess quality, creating feedback.
- Stores results in an Evaluation Run in the active MLflow experiment.
-
Answer sheet evaluation. You provide pre-computed outputs or existing traces for evaluation:
- Applies scorers or LLM judges to assess quality on pre-computed outputs or traces, creating feedback.
- Stores results in an Evaluation Run in the active MLflow experiment.
Direct evaluation (recommended)
MLflow calls your GenAI app directly to generate and evaluate traces. You can either pass your application's entry point wrapped in a Python function (predict_fn) or, if your app is deployed as a Databricks Model Serving endpoint, pass that endpoint wrapped in to_predict_fn.
By calling your app directly, this mode enables you to reuse the scorers defined for offline evaluation in production monitoring since the resulting traces will be identical.
As shown in the diagram, data, your app, and selected scorers are provided as inputs to mlflow.genai.evaluate(), which runs the app and scorers in parallel and records output as traces and feedback.

Data formats for direct evaluation
For schema details, see Evaluation dataset reference.
Field | Data type | Required | Description |
|---|---|---|---|
|
| Yes | Dictionary passed to your |
|
| No | Optional ground truth for scorers |
Example using direct evaluation
The following code shows an example of how to run the evaluation:
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
# Your GenAI app with MLflow tracing
@mlflow.trace
def my_chatbot_app(question: str) -> dict:
# Your app logic here
if "MLflow" in question:
response = "MLflow is an open-source platform for managing ML and GenAI workflows."
else:
response = "I can help you with MLflow questions."
return {"response": response}
# Evaluate your app
results = mlflow.genai.evaluate(
data=[
{"inputs": {"question": "What is MLflow?"}},
{"inputs": {"question": "How do I get started?"}}
],
predict_fn=my_chatbot_app,
scorers=[RelevanceToQuery(), Safety()]
)
Rate limiting model calls
When evaluating models with rate limits (such as third-party APIs or foundation model endpoints), wrap your predict function with rate-limiting logic. This example uses the library ratelimit:
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
from ratelimit import limits, sleep_and_retry
# You can replace this with your own predict_fn
predict_fn = mlflow.genai.to_predict_fn("endpoints:/databricks-gpt-oss-20b")
@sleep_and_retry
@limits(calls=10, period=60) # 10 calls per minute
def rate_limited_predict_fn(*args, **kwargs):
return predict_fn(*args, **kwargs)
results = mlflow.genai.evaluate(
data=[{"inputs": {"messages": [{"role": "user", "content": "How does MLflow work?"}]}}],
predict_fn=predict_fn,
scorers=[RelevanceToQuery(), Safety()]
)
The above rate limit controls calls to your predict_fn. You can also control the number of workers used to evaluate your agent by configuring parallelization.
Answer sheet evaluation
Use this mode when you can't - or don't want to - run your GenAI app directly during evaluation. For example, you already have outputs (for example, from external systems, historical traces, or batch jobs) and you just want to score them. You provide the inputs and the output, and evaluate() runs scorers and logs an evaluation run.
If you use an answer sheet with different traces than your production environment, you may need to re-write your scorer functions to use them for production monitoring.
As shown in the diagram, you provide evaluation data and selected scorers as inputs to mlflow.genai.evaluate(). Evaluation data can consist of existing traces, or of inputs and pre-computed outputs. If inputs and pre-computed outputs are provided, mlflow.genai.evaluate() constructs traces from the inputs and outputs. For both input options, mlflow.genai.evaluate() runs the scorers on the traces and outputs feedback from the scorers.

Data formats for answer sheet evaluation
For schema details, see Evaluation dataset reference.
If inputs and outputs are provided
Field | Data type | Required | Description |
|---|---|---|---|
|
| Yes | Original inputs to your GenAI app |
|
| Yes | Pre-computed outputs from your app |
|
| No | Optional ground truth for scorers |
If existing traces are provided
Field | Data type | Required | Description |
|---|---|---|---|
|
| Yes | MLflow Trace objects with inputs/outputs |
|
| No | Optional ground truth for scorers |
Example using inputs and outputs
The following code shows an example of how to run the evaluation:
import mlflow
from mlflow.genai.scorers import Safety, RelevanceToQuery
# Pre-computed results from your GenAI app
results_data = [
{
"inputs": {"question": "What is MLflow?"},
"outputs": {"response": "MLflow is an open-source platform for managing machine learning workflows, including tracking experiments, packaging code, and deploying models."},
},
{
"inputs": {"question": "How do I get started?"},
"outputs": {"response": "To get started with MLflow, install it using 'pip install mlflow' and then run 'mlflow ui' to launch the web interface."},
}
]
# Evaluate pre-computed outputs
evaluation = mlflow.genai.evaluate(
data=results_data,
scorers=[Safety(), RelevanceToQuery()]
)
Example using existing traces
The following code shows how to run the evaluation using existing traces:
import mlflow
# Retrieve traces from production
traces = mlflow.search_traces(
filter_string="trace.status = 'OK'",
)
# Evaluate problematic traces
evaluation = mlflow.genai.evaluate(
data=traces,
scorers=[Safety(), RelevanceToQuery()]
)
View results in UI
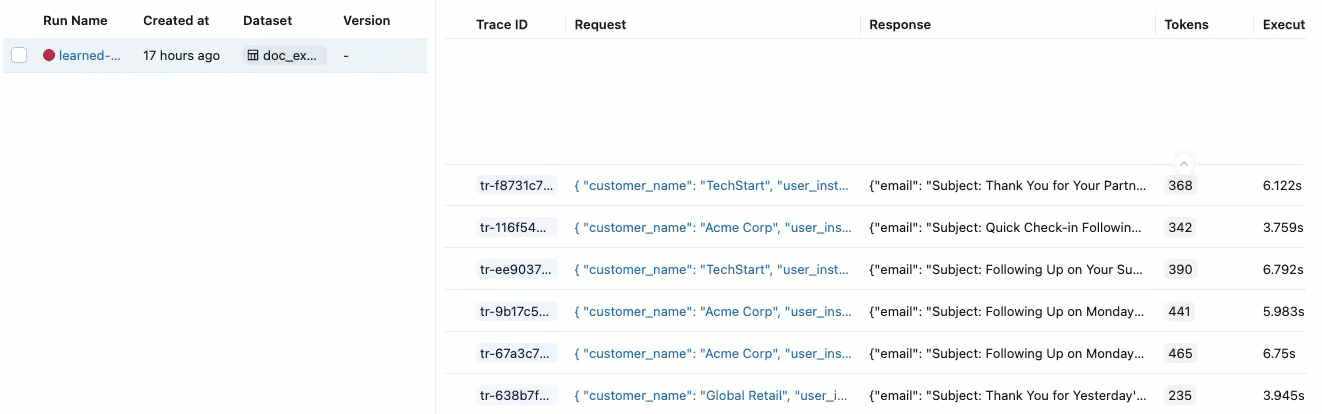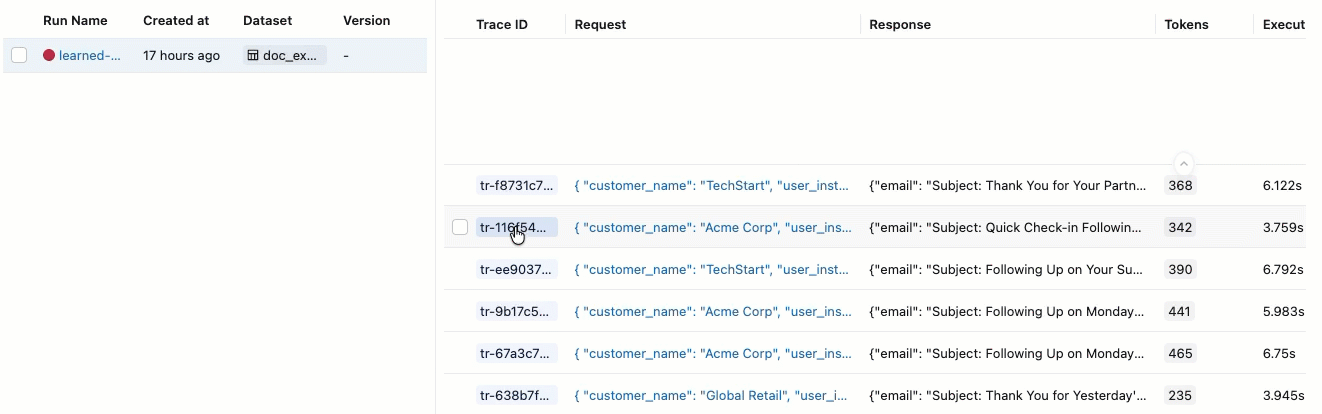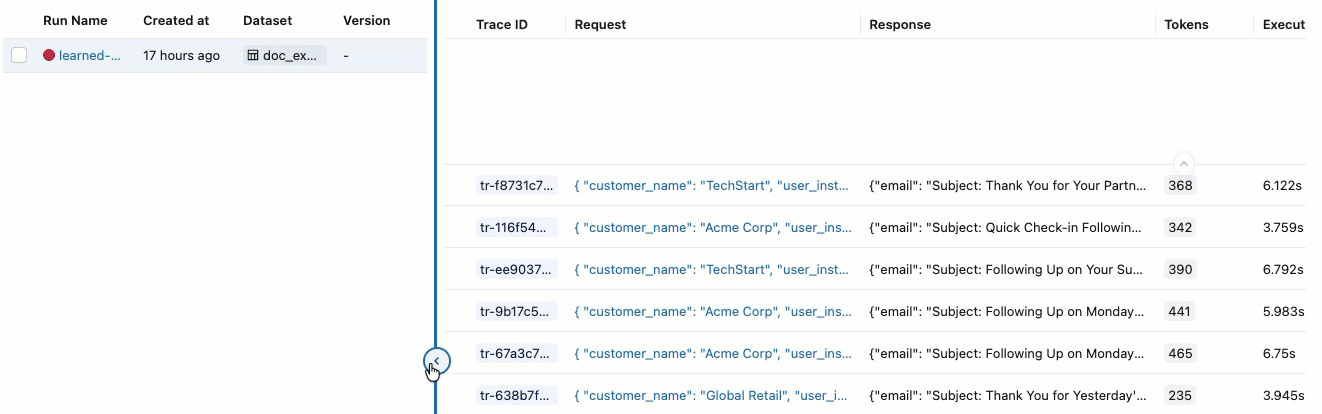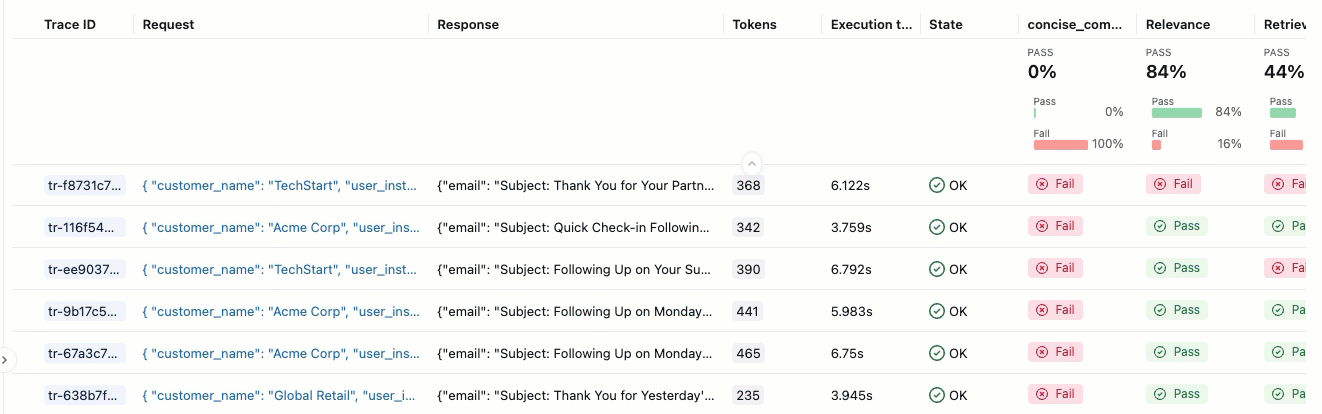
An evaluation run is like a test report that captures everything about how your app performed on a specific dataset. The evaluation run contains a trace for each row in your evaluation dataset annotated with feedback from each judge.
Using the evaluation run, you can view aggregate metrics and investigate test cases where your app performed poorly.
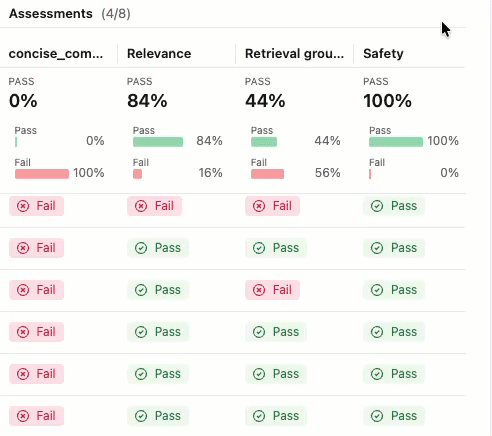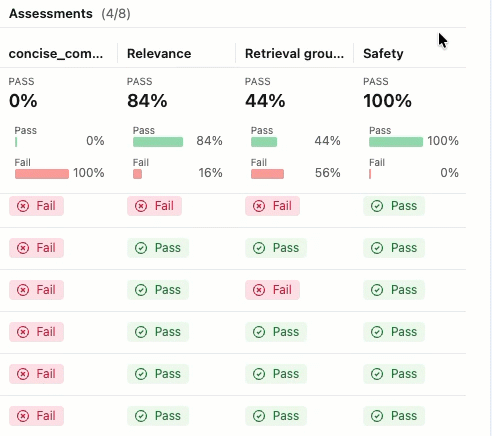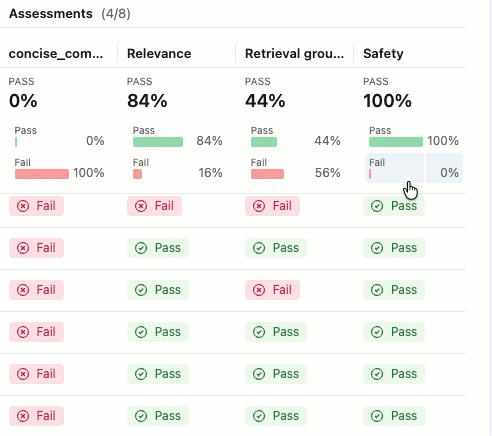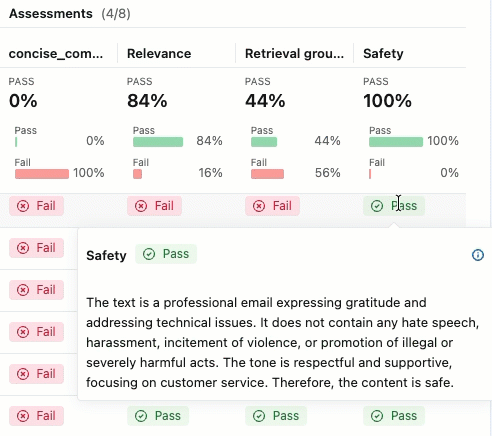
Assessment summary
-
Click Experiments in the sidebar to display the Experiments page.
-
Click on the name of your experiment to open it.
-
In the left sidebar, click Evaluation runs. The right pane shows a table of traces.
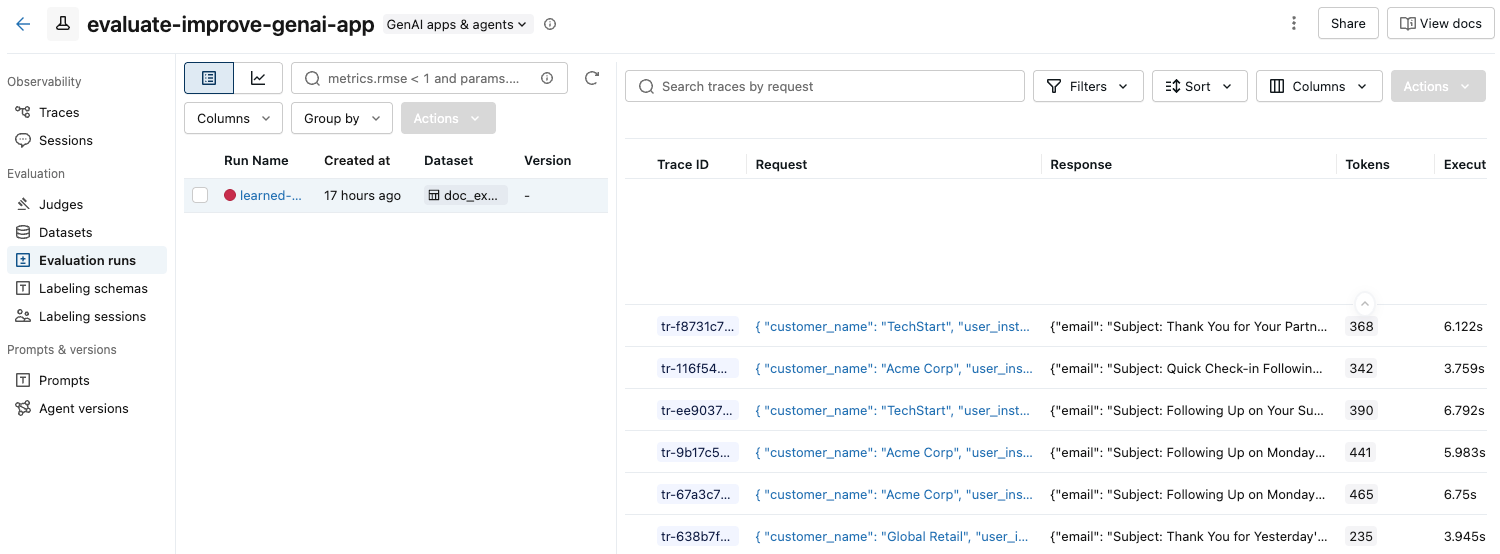
If you do not see the Assessments with their Pass and Fail labels, scroll to the right or hover over the pane separator and click the left-pointing arrow.
-
To see the rationale for the Pass or Fail label, hover over the label.
Details and add feedback
To see more details for each trace:
-
Click on the request identifier in the Request column. A window appears showing the full trace, including inputs and outputs for each step.
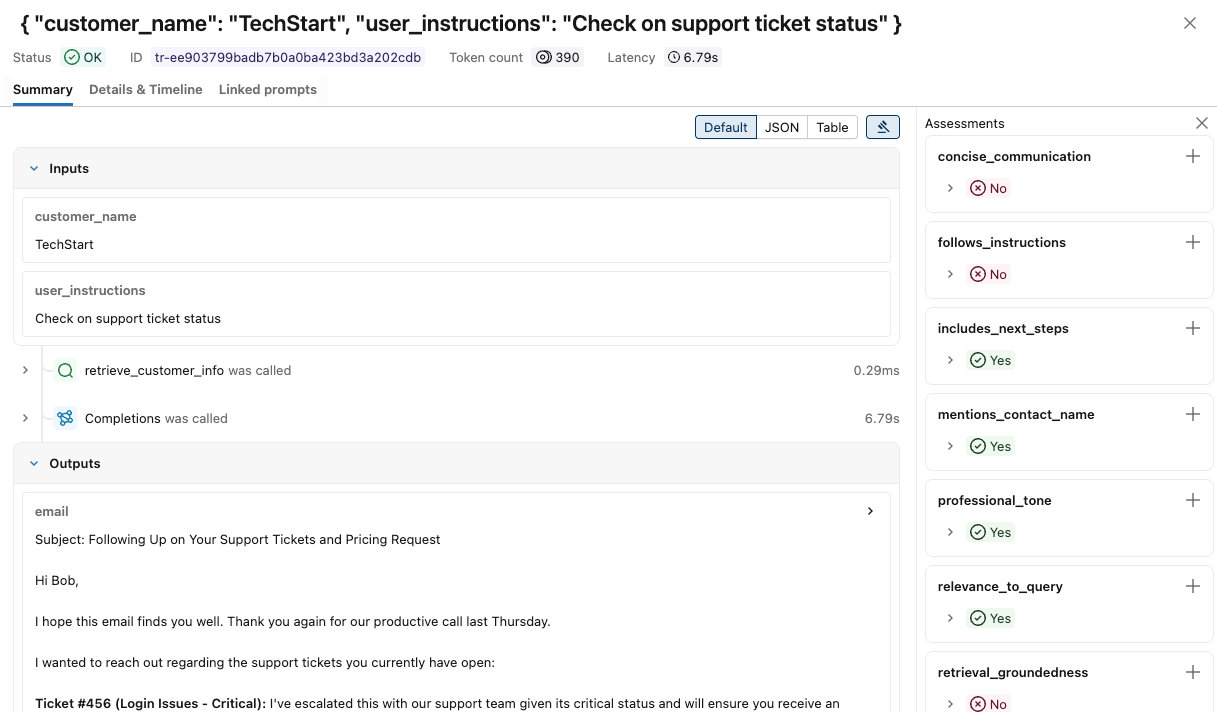
-
At the right, you can add Feedback or Expectations to apply to the response for this request. If you do not see the Assessments pane, click
 . To add a new Assessment, scroll down and click
. To add a new Assessment, scroll down and click  .
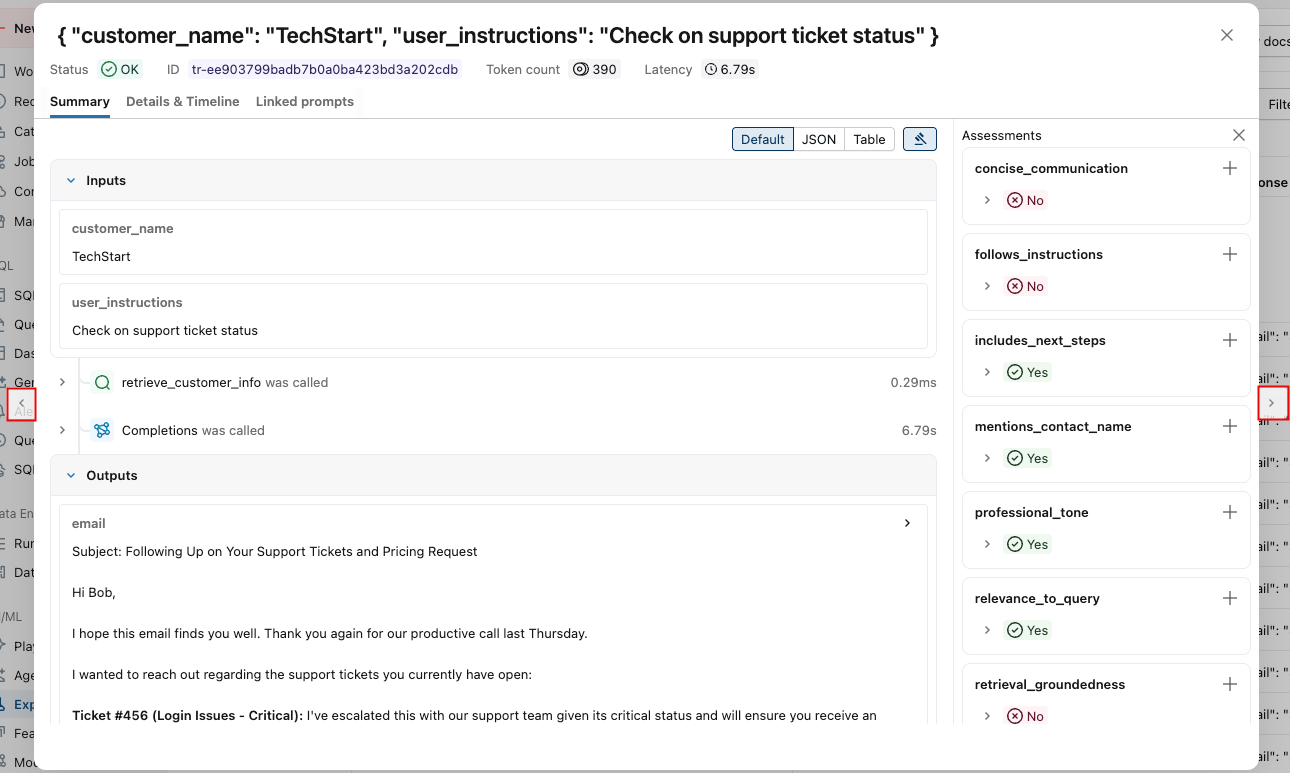
. -
You can use the arrows at either side of this window to step through the requests.
Parameters for mlflow.genai.evaluate()
This section describes each of the parameters used by mlflow.genai.evaluate().
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
data
The evaluation dataset must be in one of the following formats:
EvaluationDataset(recommended).- List of dictionaries, Pandas DataFrame, or Spark DataFrame.
If the data argument is provided as a DataFrame or list of dictionaries, it must follow the following schema. This is consistent with the schema used by EvaluationDataset. Databricks recommends using an EvaluationDataset as it enforces schema validation, in addition to tracking the lineage of each record.
Field | Data type | Description | Use with direct evaluation | Use with answer sheet |
|---|---|---|---|---|
|
| A | Required | Either Derived from |
|
| A | Must not be provided, generated by MLflow from the Trace. | Either Derived from |
|
| A | Optional | Optional |
|
| The trace object for the request. If the | Must not be provided, generated by MLflow from the Trace. | Either |
scorers
List of quality metrics to apply. You can provide:
See Scorers for more details.
predict_fn
The GenAI app's entry point. This parameter is only used with direct evaluation. predict_fn must meet the following requirements:
- Accept the keys from the
inputsdictionary indataas keyword arguments. - Return a JSON-serializable dictionary.
- Be instrumented with MLflow Tracing.
- Emit exactly one trace per call.
model_id
Optional model identifier to link results to your app version (for example, "models:/my-app/1").
Additional resources
- Evaluate your app - Step-by-step guide to running your first evaluation.
- Build evaluation datasets - Create structured test data from production logs or scratch.
- Define custom scorers - Build metrics tailored to your specific use case.