Scorers and LLM judges
Scorers are a key component of the MLflow GenAI evaluation framework. They provide a unified interface to define evaluation criteria for your models, agents, and applications. Like their name suggests, scorers score how well your application did based on the evaluation criteria. This could be a pass/fail, true/false, numerical value, or a categorical value.
You can use the same scorer for evaluation in development and monitoring in production to keep evaluation consistent throughout the application lifecycle.
Choose the right type of scorer depending on how much customization and control you need. Each approach builds on the previous one, adding more complexity and control.
Start with built-in judges for quick evaluation. As your needs evolve, build custom LLM judges for domain-specific criteria and create custom code-based scorers for deterministic business logic.
Approach | Level of customization | Use cases |
|---|---|---|
Minimal (moderate for Guidelines judges) | Quickly try LLM evaluation with built-in scorers such as Built-in judges also include Guidelines judges, built-in judges that check whether responses pass or fail custom natural-language rules, such as style or factuality guidelines. | |
Full | Create fully customized LLM judges with detailed evaluation criteria and feedback optimization. Capable of returning numerical scores, categories, or boolean values. | |
Full | Programmatic and deterministic scorers that evaluate things like exact matching, format validation, and performance metrics. | |
Full | When you need specialized metrics available from open-source evaluation frameworks. |
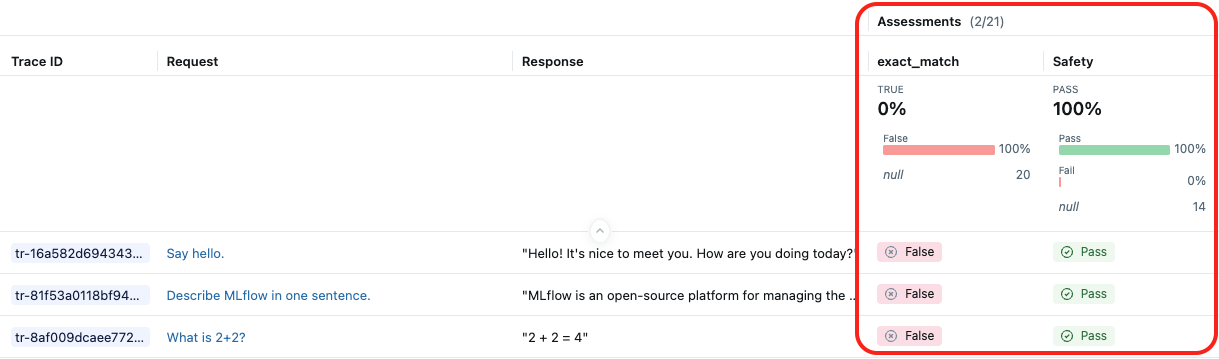
The following screenshot shows the results from the built-in LLM judge Safety and a custom scorer exact_match:
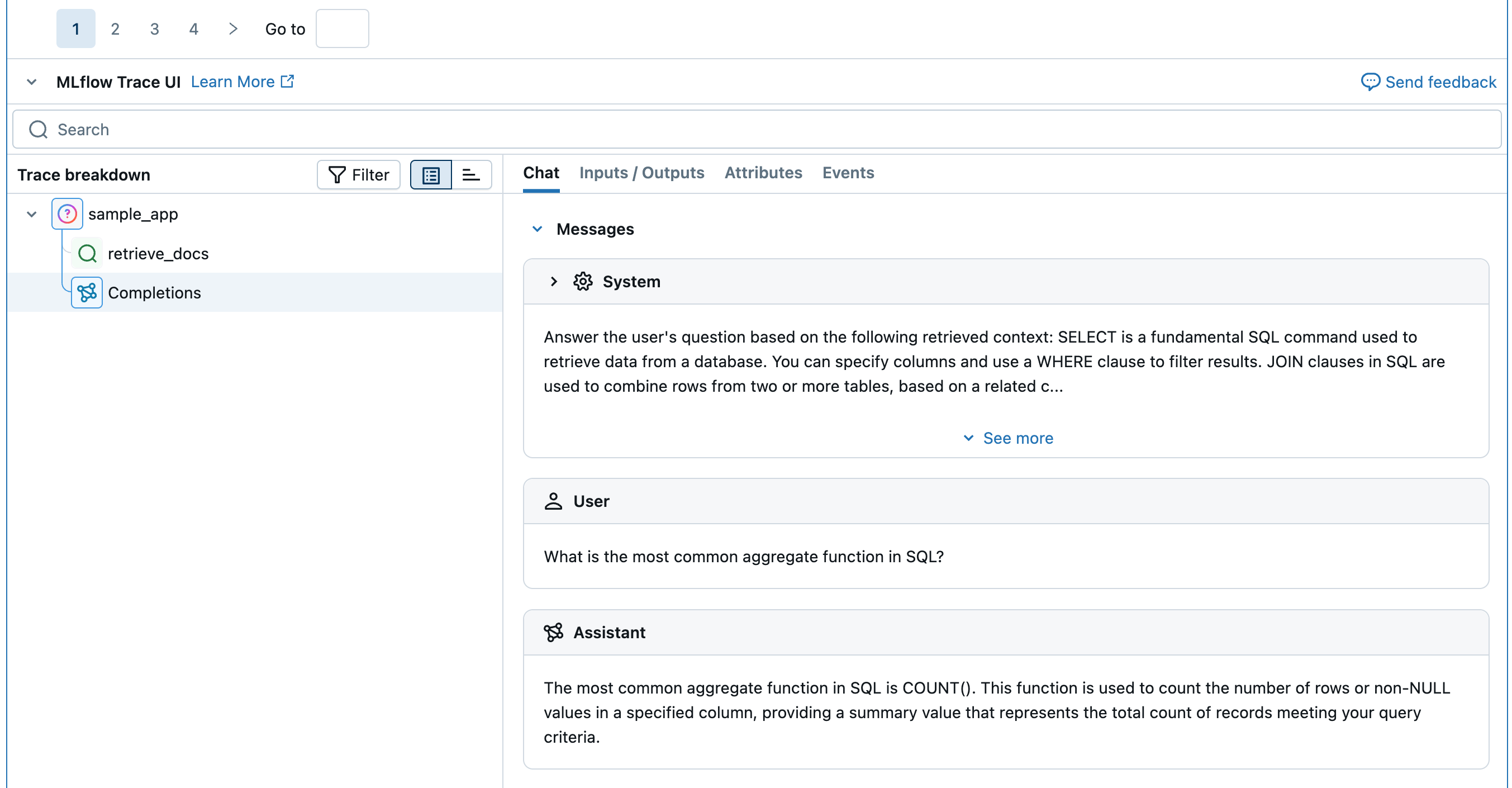
How scorers work
A scorer receives a Trace from either evaluate() or the monitoring service. It then does the following:
- Parses the
traceto extract specific fields and data that are used to assess quality - Runs the scorer to perform the quality assessment based on the extracted fields and data
- Returns the quality assessment as
Feedbackto attach to thetrace
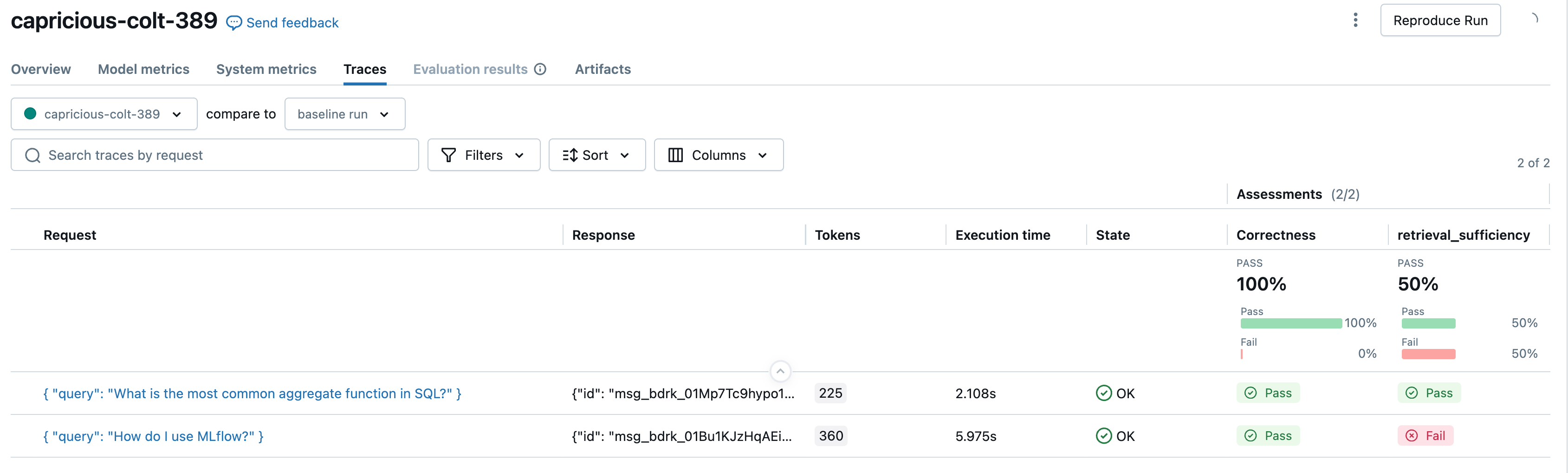
LLMs as judges
LLM judges are a type of MLflow Scorer that uses Large Language Models for quality assessment.
Think of a judge as an AI assistant specialized in quality assessment. It can evaluate your app's inputs, outputs, and even explore the entire execution trace to make assessments based on criteria you define. For example, a judge can understand that give me healthy food options and food to keep me fit are similar queries.
Judges are a type of scorer that use LLMs for evaluation. Use them directly with mlflow.genai.evaluate() or wrap them in custom scorers for advanced scoring logic.
Built-in LLM judges
MLflow provides research-validated built-in judges for common quality dimensions like relevance, safety, groundedness, and correctness. For the complete list and detailed guidance on each judge, see Built-in LLM judges.
Multi-turn judges
For conversational AI systems, MLflow also provides built-in judges that evaluate entire conversations rather than individual turns. See Multi-turn judges.
Custom LLM judges
In addition to built-in judges, you can create your own judges using custom prompts and instructions.
Use custom LLM judges when you need to define specialized evaluation tasks, need more control over grades or scores (not just pass/fail), or need to validate that your agent made appropriate decisions and performed operations correctly for your specific use case. Use judge alignment to train custom LLM judges to match human evaluation standards through systematic feedback.
See Custom judges.
Select the LLM that powers the judge
By default, each judge uses a Databricks-hosted LLM designed to perform GenAI quality assessments. You can change the judge model by using the model argument in the judge definition. Specify the model in the format <provider>:/<model-name>. For example:
from mlflow.genai.scorers import Correctness
Correctness(model="databricks:/databricks-gpt-5-mini")
Information about the models powering LLM judges
- LLM judges might use third-party services to evaluate your GenAI applications, including Azure OpenAI operated by Microsoft.
- For Azure OpenAI, Databricks has opted out of Abuse Monitoring so no prompts or responses are stored with Azure OpenAI.
- When cross-Geo processing is disabled, LLM judges process content in the workspace's Databricks Geo. If no eligible in-Geo model is available, the judge returns a geo-restriction error. When cross-Geo processing is enabled, LLM judges can process content in other Geos.
- Disabling Partner-powered AI features prevents the LLM judge from calling partner-powered models. You can still use LLM judges by providing your own model.
- LLM judges are intended to help customers evaluate their GenAI agents/applications, and LLM judge outputs should not be used to train, improve, or fine-tune an LLM.
Judge accuracy
Databricks continuously improves judge quality through:
- Research validation against human expert judgment
- Metrics tracking: Cohen's Kappa, accuracy, F1 score
- Diverse testing on academic and real-world datasets
Code-based scorers
Custom code-based scorers offer the ultimate flexibility to define precisely how your GenAI application's quality is measured. You can define evaluation metrics tailored to your specific business use case, whether based on simple heuristics, advanced logic, or programmatic evaluations.
Use custom scorers for the following scenarios:
- Defining a custom heuristic or code-based evaluation metric.
- Customizing how the data from your app's trace is mapped to built-in LLM judges.
- Using your own LLM (rather than a Databricks-hosted LLM judge) for evaluation.
- Any other use cases where you need more flexibility and control than provided by custom LLM judges.
See Code-based scorers.