Tracing Ollama
Ollama is an open-source platform that enables users to run large language models (LLMs) locally on their devices, such as Llama 3.2, Gemma 2, Mistral, Code Llama, and more.
Since the local LLM endpoint served by Ollama is compatible with the OpenAI API, you can query it via OpenAI SDK and enable tracing for Ollama with mlflow.openai.autolog(). Any LLM interactions via Ollama will be recorded to the active MLflow Experiment.
import mlflow
mlflow.openai.autolog()
On serverless compute clusters, autologging for genAI tracing frameworks is not automatically enabled. You must explicitly enable autologging by calling the appropriate mlflow.<library>.autolog() function for the specific integrations you want to trace.
Example Usage
- Run the Ollama server with the desired LLM model.
ollama run llama3.2:1b
- Enable auto-tracing for OpenAI SDK.
import mlflow
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking on Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/ollama-demo")
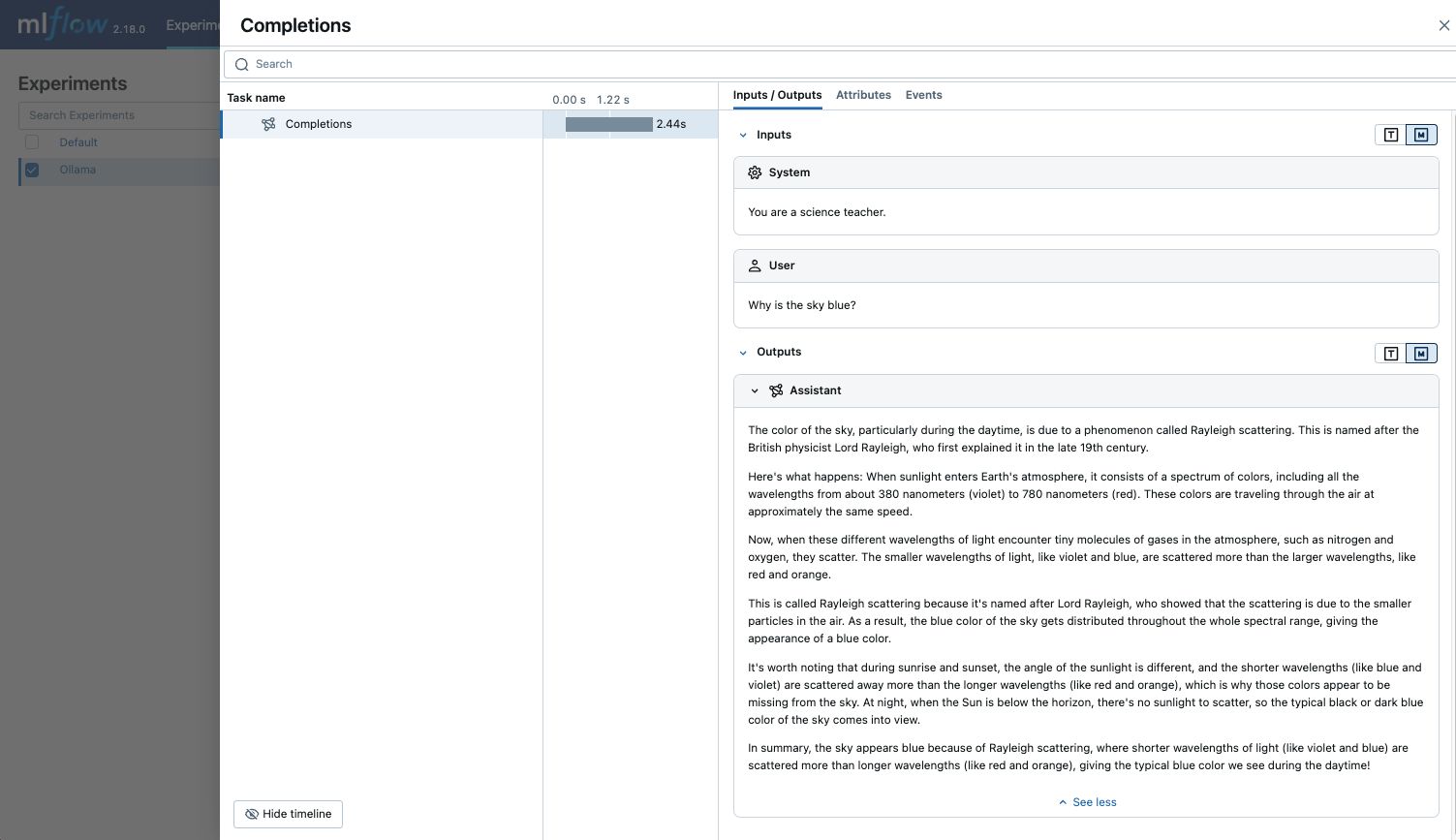
- Query the LLM and see the traces in the MLflow UI.
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # The local Ollama REST endpoint
api_key="dummy", # Required to instantiate OpenAI client, it can be a random string
)
response = client.chat.completions.create(
model="llama3.2:1b",
messages=[
{"role": "system", "content": "You are a science teacher."},
{"role": "user", "content": "Why is the sky blue?"},
],
)
Disable auto-tracing
Auto tracing for Ollama can be disabled globally by calling mlflow.openai.autolog(disable=True) or mlflow.autolog(disable=True).
Additional resources
- Understand tracing concepts - Learn how MLflow captures and organizes trace data
- Debug and observe your app - Use the Trace UI to analyze your locally-run Ollama models
- Evaluate your app's quality - Set up quality assessment for your Ollama-powered application