Tracing OpenAI

MLflow Tracing provides automatic tracing capability for OpenAI. By enabling auto tracing
for OpenAI by calling the mlflow.openai.autolog function, MLflow will capture traces for LLM invocation and log them to the active MLflow Experiment.
MLflow trace automatically captures the following information about OpenAI calls:
- Prompts and completion responses
- Latencies
- Model name
- Additional metadata such as
temperature,max_tokens, if specified. - Function calling if returned in the response
- Any exception if raised
Prerequisites
To use MLflow Tracing with OpenAI, you need to install MLflow and the OpenAI SDK.
- Development
- Production
For development environments, install the full MLflow package with Databricks extras and openai:
pip install --upgrade "mlflow[databricks]>=3.1" openai
The full mlflow[databricks] package includes all features for local development and experimentation on Databricks.
For production deployments, install mlflow-tracing and openai:
pip install --upgrade mlflow-tracing openai
The mlflow-tracing package is optimized for production use.
MLflow 3 is highly recommended for the best tracing experience with OpenAI.
Before running the examples, you'll need to configure your environment:
For users outside Databricks notebooks: Set your Databricks environment variables:
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
For users inside Databricks notebooks: These credentials are automatically set for you.
API Keys: Ensure your OpenAI API key is configured. For production environments, use AI Gateway or Databricks secrets instead of hardcoded values for secure API key management.:
export OPENAI_API_KEY="your-openai-api-key"
Supported APIs
MLflow supports automatic tracing for the following OpenAI APIs:
Chat Completion | Embeddings | Function Calling | Structured Outputs | Streaming | Async | Image | Audio |
|---|---|---|---|---|---|---|---|
✅ | ✅ | ✅ | ✅ (*1) | ✅ (*2) | ✅ (*1) |
(*1) Streaming support was added in MLflow 2.15.0.
(*2) Async and structured output supported were added in MLflow 2.21.0.
To request support for additional APIs, please open a feature request on GitHub.
Basic Example
On serverless compute clusters, autologging for genAI tracing frameworks is not automatically enabled. You must explicitly enable autologging by calling the appropriate mlflow.<library>.autolog() function for the specific integrations you want to trace.
import openai
import mlflow
import os
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/openai-tracing-demo")
openai_client = openai.OpenAI()
messages = [
{
"role": "user",
"content": "What is the capital of France?",
}
]
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.1,
max_tokens=100,
)
For production environments, use AI Gateway or Databricks secrets instead of hardcoded values for secure API key management.
OpenAI Example with Secrets
Once your secret is stored, use it in your MLflow tracing code:
import openai
import mlflow
import os
# Configure your secret scope and key names
secret_scope_name = "openai-secrets"
secret_key_name = "api-key"
# Retrieve the API key from Databricks secrets
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get(
scope=secret_scope_name,
key=secret_key_name
)
# Verify the API key was loaded successfully
assert os.environ["OPENAI_API_KEY"] is not None, "API key not loaded from secrets"
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/openai-tracing-demo")
# Now you can use OpenAI as usual
openai_client = openai.OpenAI()
messages = [
{
"role": "user",
"content": "What is the capital of France?",
}
]
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.1,
max_tokens=100,
)
Streaming
MLflow Tracing supports streaming API of the OpenAI SDK. With the same set up of auto tracing, MLflow automatically traces the streaming response and render the concatenated output in the span UI. The actual chunks in the response stream can be found in the Event tab as well.
import openai
import mlflow
import os
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Uncomment and set if not globally configured
# Enable trace logging
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/openai-streaming-demo")
client = openai.OpenAI()
stream = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "How fast would a glass of water freeze on Titan?"}
],
stream=True, # Enable streaming response
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Async
MLflow Tracing supports asynchronous API of the OpenAI SDK since MLflow 2.21.0. The usage is same as the synchronous API.
import openai
import mlflow
import os
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Uncomment and set if not globally configured
# Enable trace logging
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/openai-async-demo")
client = openai.AsyncOpenAI()
response = await client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "How fast would a glass of water freeze on Titan?"}
],
# Async streaming is also supported
# stream=True
)
Function Calling
MLflow Tracing automatically captures function calling response from OpenAI models. The function instruction in the response will be highlighted in the trace UI. Moreover, you can annotate the tool function with the @mlflow.trace decorator to create a span for the tool execution.
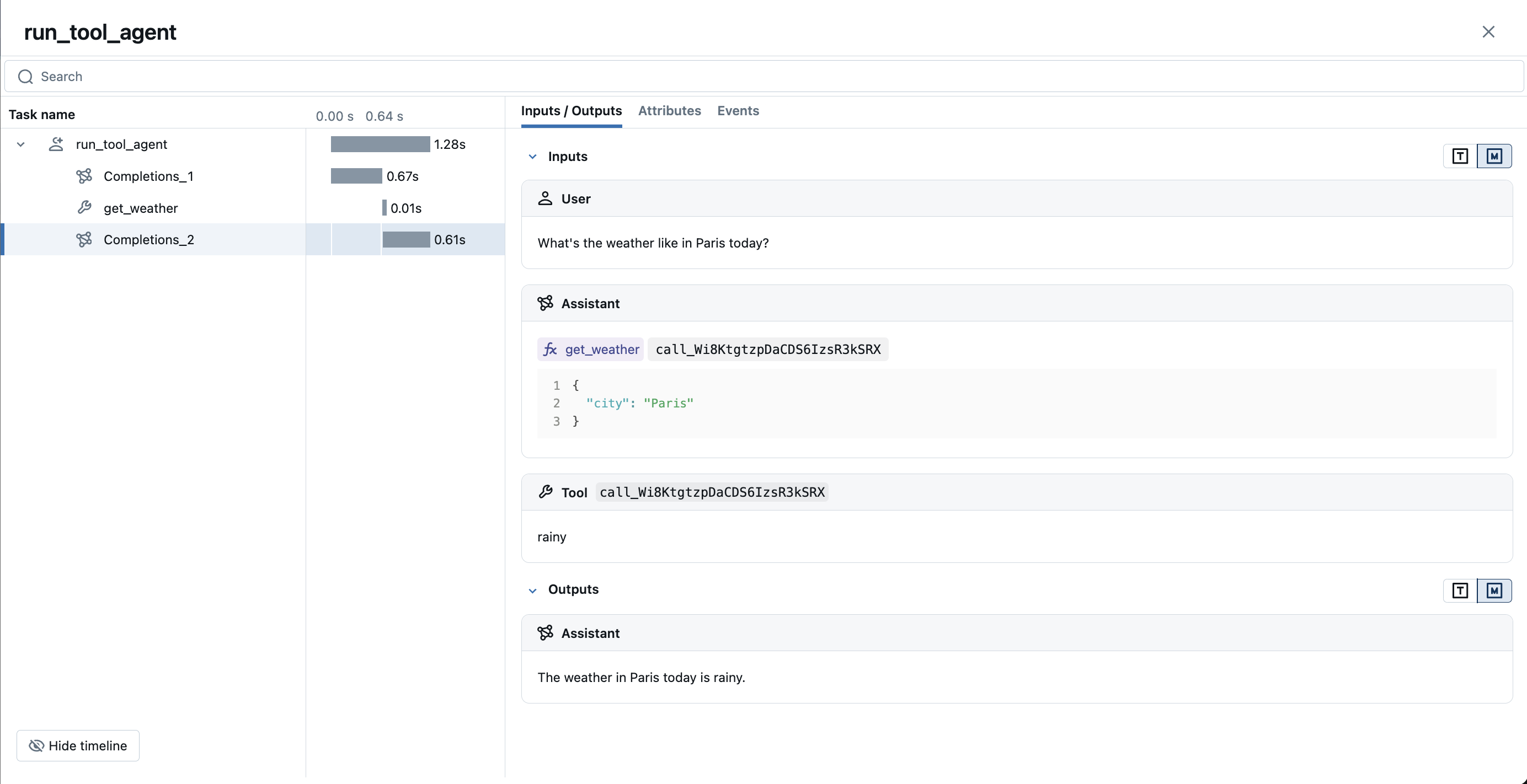
The following example implements a simple function calling agent using OpenAI Function Calling and MLflow Tracing for OpenAI.
import json
from openai import OpenAI
import mlflow
from mlflow.entities import SpanType
import os
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Uncomment and set if not globally configured
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/openai-function-agent-demo")
# Assuming autolog is enabled globally or called earlier
# mlflow.openai.autolog()
client = OpenAI()
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
},
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools,
)
ai_msg = response.choices[0].message
messages.append(ai_msg)
# If the model request tool call(s), invoke the function with the specified arguments
if tool_calls := ai_msg.tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
if tool_func := _tool_functions.get(function_name):
args = json.loads(tool_call.function.arguments)
tool_result = tool_func(**args)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result,
}
)
# Sent the tool results to the model and get a new response
response = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
return response.choices[0].message.content
# Run the tool calling agent
question = "What's the weather like in Paris today?"
answer = run_tool_agent(question)
Disable auto-tracing
Auto tracing for OpenAI can be disabled globally by calling mlflow.openai.autolog(disable=True) or mlflow.autolog(disable=True).