Manage projects
A project is the top-level container for your Lakebase resources, including branches, computes, databases, and roles. This page explains how to create projects, understand their structure, configure settings, and manage their lifecycle.
If you're new to Lakebase, start with Get started to create your first project.
Understanding projects
Project structure
Understanding the Lakebase project structure helps you organize and manage your resources effectively. A project is the top-level container for your databases, branches, computes, and related resources. Each project includes settings for compute defaults, restore windows, and updates that apply to all branches within the project.
At the top level, a project contains one or more branches. Within a project, you can create branches for different environments such as development, testing, staging, and production. Each branch contains its own computes, roles, and databases.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Branches
Data resides in branches. Each Lakebase project is created with a root branch called production, which cannot be deleted. While you can create additional branches and designate a different branch as your default branch, the root branch cannot be deleted.
You can create child branches from any branch in your project. When you create a child branch, it inherits all databases, roles, and data from its parent branch at the time of creation. Subsequent changes in the parent branch don't automatically propagate to the child branch, enabling isolated development, testing, or experimentatation.
Each branch can contain multiple databases and roles. Learn more: Manage branches
Computes
A compute is a virtualized computing resource that includes vCPU and memory for running Postgres. When you create a project, a primary R/W (read-write) compute is created for the project's default branch. Each branch has a single primary R/W compute. To connect to a database that resides on a branch, you must connect through the R/W compute associated with the branch.
In addition to the primary R/W compute, you can add one or more read replica (read-only) computes to any branch. Read replicas enable you to offload read-only workloads from your primary compute for use cases such as horizontal read scaling, analytics and reporting queries, and read-only access for users or applications. Learn more: Manage computes, Read replicas
Roles
Roles are Postgres roles. A role is required to create and access a database. A role belongs to a branch. When you create a project, a Postgres role is automatically created for your Databricks identity (for example, user@databricks.com), which is the owner of the default databricks_postgres database. Any role created in the Lakebase UI is created with databricks_superuser privileges. There is a limit of 500 roles per branch. Learn more: Manage roles
Databases
A database is a container for SQL objects such as schemas, tables, views, functions, and indexes. In Lakebase, a database belongs to a branch. The default branch of your project is created with a database named databricks_postgres. There is a limit of 500 databases per branch. Learn more: Manage databases
Schemas
All databases in Lakebase are created with a public schema, which is the default behavior for any standard Postgres instance. SQL objects are created in the public schema by default.
Project limits
Lakebase Postgres enforces the following limits for projects:
Resource | Limit |
|---|---|
Maximum number of concurrently active computes | 20 |
Maximum number of read replicas per branch | 6 |
Maximum number of branches per project | 500 |
Maximum number of Postgres roles per branch | 500 |
Maximum number of Postgres databases per branch | 500 |
Database storage quota (per branch) | 16 TB |
Maximum number of projects per workspace | 1000 |
Maximum number of protected branches | 1 |
Maximum number of root branches | 3 |
Maximum number of unarchived branches | 10 |
Maximum number of manual snapshots | 10 |
Maximum history retention period | 30 days |
Minimum scale to zero time | 60 seconds |
Maximum scale to zero time | 7 days |
Concurrently active compute limit
The concurrently active compute limit caps how many computes can run at the same time to prevent resource exhaustion. This limit protects against accidental resource surges, such as starting many compute endpoints at once. The default limit is 20 concurrently active computes per project.
Important: The default branch is exempt from this limit, ensuring it remains available at all times.
When you exceed the limit, additional computes beyond the limit remain suspended and you see an error when attempting to connect to them. To resolve this:
- Suspend other active computes and try again.
- If you encounter this error often, contact Databricks Support to request a limit increase.
Computes with scale to zero enabled automatically suspend after a period of inactivity, helping you stay within the concurrently active compute limit.
Database storage quota
Each branch has a 16 TB database storage quota. This is an operational quota rather than an architectural limit, because data lives in cloud object storage instead of on a provisioned local disk.
When a database reaches its quota, write performance drops, but you can still drop or delete data to reclaim space. Contact Databricks Support if you need a larger quota.
Only your actual data (tables and indexes, as reported by Postgres) counts against the quota. History retained for point-in-time restore doesn't.
Region availability
Supported regions:
us-east-1(US East - N. Virginia)us-east-2(US East - Ohio)us-west-2(US West - Oregon)ca-central-1(Canada - Central)sa-east-1(South America - São Paulo)eu-central-1(Europe - Frankfurt)eu-west-1(Europe - Ireland)eu-west-2(Europe - London)ap-south-1(Asia Pacific - Mumbai)ap-southeast-1(Asia Pacific - Singapore)ap-southeast-2(Asia Pacific - Sydney)ap-northeast-1(Asia Pacific - Tokyo)
Your Lakebase project is created in your Databricks workspace region.
Postgres version support
Lakebase Postgres Autoscaling supports Postgres 16, Postgres 17, and Postgres 18. Postgres 17 is the default version. To use Postgres 18, select it when creating a new project.
Create and manage projects
Create a project
You can create multiple projects in Lakebase Postgres to keep applications or customers fully isolated, ensuring clean separation of data and resources.
To create a project:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Click the apps switcher in the top right corner to open the Lakebase App.
- Click New project.
- Configure your project settings:
- Display name: Enter a name for your project. You can use any characters, including spaces and special characters. Common naming patterns include naming after the application (for example,
My Analytics App) or the customer or tenant the project serves (for example,Acme Corp DB). A resource name is derived from your display name automatically and is used to identify the project in API and SDK calls. The dialog shows the resulting resource name (for example,projects/my-analytics-app) so you can verify it before creating the project. - Postgres version: Select the Postgres version you want to use.
- Serverless usage policy (optional): Select a serverless usage policy to attribute serverless compute costs to a specific policy. See Serverless usage policies.
- Display name: Enter a name for your project. You can use any characters, including spaces and special characters. Common naming patterns include naming after the application (for example,
The Create project dialog shows the project configuration options.
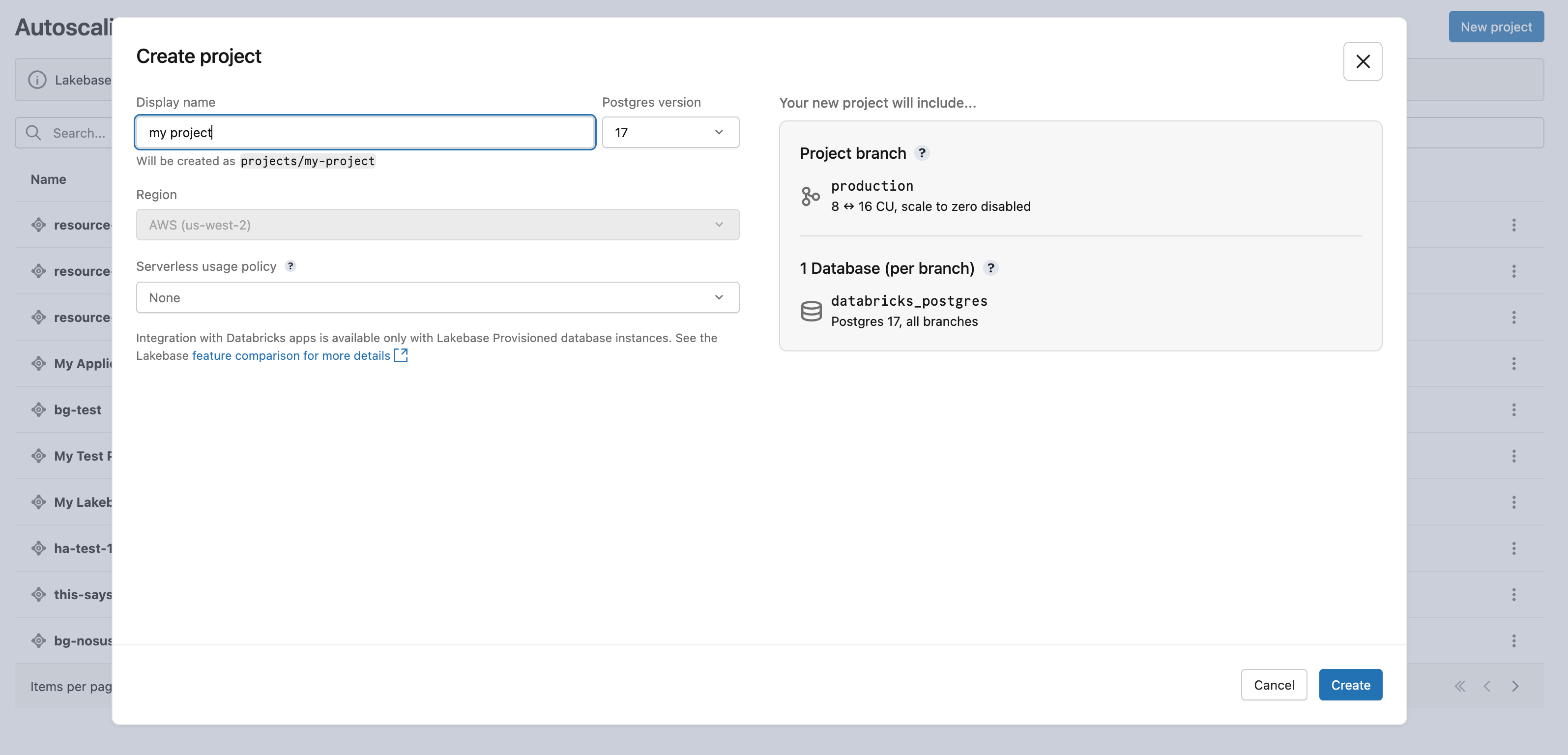
The Region for your Lakebase project is set to your Databricks workspace region and cannot be modified.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version=17,
budget_policy_id="<policy-id>"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
# Create a project with a custom project ID
databricks postgres create-project my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}'
Create a project with a custom project ID. The project_id is specified as a query parameter and becomes part of the project's resource name (for example, projects/my-app).
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}' | jq
This is a long-running operation. The response includes an operation name that you can use to check the status. The operation typically completes within seconds.
The project_id parameter is required.
If you are creating a project with the same ID as a recently deleted project, note that deleted project IDs are reserved for 7 days. To reuse the ID immediately, permanently delete the original project first.
A new project includes the following resources by default:
-
A single
productionbranch (the default branch) -
A single primary read-write compute associated with the branch with the following default settings:
Branch
Compute Units (CU)
HA
Autoscaling
Scale-to-zero
production8 - 16 CU
When you create a project, the
productionbranch is created with a compute that has scale-to-zero enabled by default with a 24-hour inactivity timeout. You can adjust the timeout or turn off scale-to-zero for this compute if needed. -
A Postgres database (named
databricks_postgres) -
A Postgres role for your Databricks identity (for example,
user@databricks.com)
To change compute settings for an existing project, see Configure project settings. To modify default compute settings for new projects, see Compute defaults in Configure project settings.
Get project details
Retrieve details for a specific project.
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Click the apps switcher in the top right corner to open the Lakebase App.
- Select your project from the projects list to view its details.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
# Get project details
databricks postgres get-project projects/my-project
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Response includes:
name: Resource name (projects/my-project)status: Project configuration and current state (display_name, pg_version, etc.)
Note: The spec field is not populated for GET operations. All resource properties are returned in the status field.
List projects
List all projects in your workspace.
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Click the apps switcher in the top right corner to open the Lakebase App.
- The projects list displays all projects you have access to.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
# List all projects
databricks postgres list-projects
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Response format:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": 17
}
}
]
}
Configure project settings
After creating a project, you can modify various settings from the project dashboard by navigating to Settings:
General settings
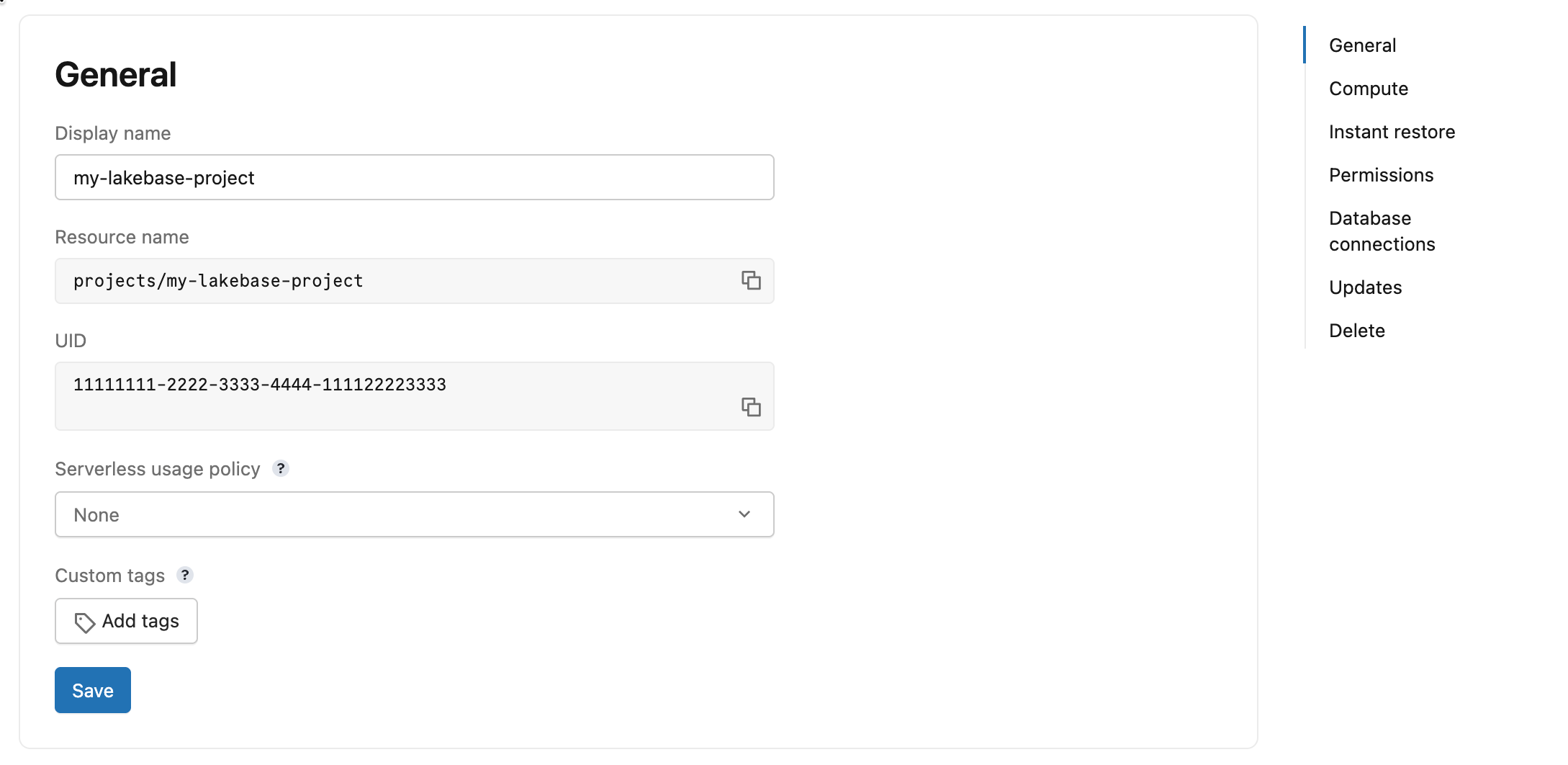
The general settings page displays the following fields:
- Display name: The editable display name for your project.
- Resource name: Read-only. The full resource path for your project (format:
projects/{project_id}). Use this value in API and SDK calls to identify the project. - UID: Read-only. The system-generated unique identifier for your project.
- Serverless usage policy: Associate a serverless usage policy with your project to attribute serverless compute costs to a specific policy. See Serverless usage policies.
- Custom tags: Add key-value tags to your project. Tags are logged in your account's billable usage records (
system.billing.usage) and can be used to track costs by team, project, or cost center. See Custom tags. When you update custom tags using the API or CLI, the new list replaces all existing tags.
- UI
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec, ProjectCustomTag, FieldMask
w = WorkspaceClient()
# Update project display name
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.display_name"]),
project=Project(spec=ProjectSpec(display_name="My Updated Project Name"))
).wait()
# Update serverless usage policy
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.budget_policy_id"]),
project=Project(spec=ProjectSpec(budget_policy_id="<policy-id>"))
).wait()
# Update custom tags (replaces all existing tags)
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.custom_tags"]),
project=Project(spec=ProjectSpec(custom_tags=[
ProjectCustomTag(key="team", value="data-eng"),
ProjectCustomTag(key="cost-center", value="1234")
]))
).wait()
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
# Update serverless usage policy
databricks postgres update-project projects/my-project spec.budget_policy_id \
--json '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}'
# Update custom tags
databricks postgres update-project projects/my-project spec.custom_tags \
--json '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}'
# Update project display name
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
# Update serverless usage policy
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.budget_policy_id" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}' | jq
# Update custom tags
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.custom_tags" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}' | jq
These are long-running operations. The response includes an operation name that you can use to check the status.
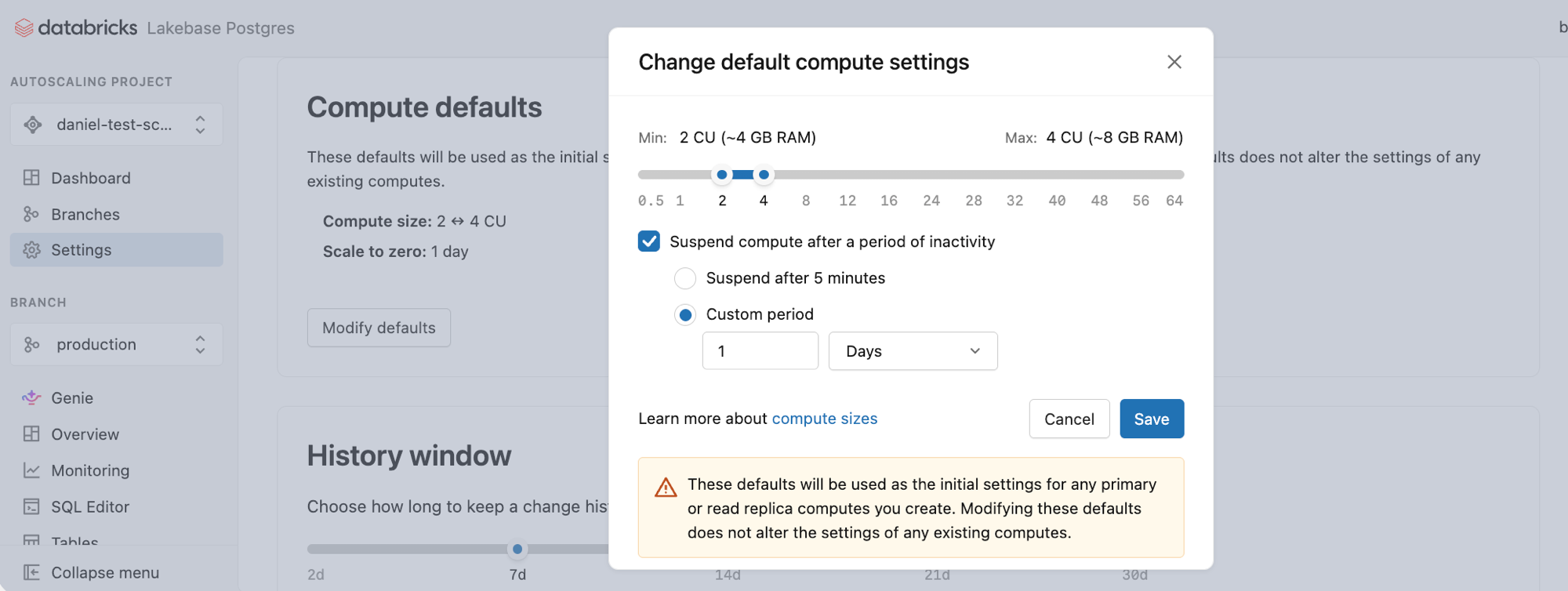
Compute defaults
These defaults are used as the initial settings for any primary or read replica computes you create. Modifying these defaults does not alter the settings of any existing computes.
Default values:
- Compute size: 2 ↔ 4 CU (autoscaling range; ~4–8 GB RAM)
- Scale to zero: Enabled by default—Suspend compute after a period of inactivity is checked, with Suspend after 24 hours selected
Click Modify defaults to open the dialog and change these values.
To modify settings for an existing compute, see Manage computes.
Lakebase Postgres supports compute sizes from 0.5 CU to 112 CU. Autoscaling is available for computes up to 64 CU (0.5, then integer increments: 1, 2, 3... 64). Larger fixed-size computes are available up to 112 CU. Each Compute Unit (CU) provides 2 GB of RAM.
Lakebase Provisioned vs Autoscaling: In Lakebase Provisioned, each Compute Unit allocated approximately 16 GB of RAM. In Lakebase Autoscaling, each CU allocates 2 GB of RAM. This change provides more granular scaling options and cost control.
Representative sizes:
Compute Units | RAM |
|---|---|
0.5 CU | 1 GB |
1 CU | 2 GB |
4 CU | 8 GB |
8 CU | 16 GB |
16 CU | 32 GB |
32 CU | 64 GB |
64 CU | 128 GB |
112 CU | 224 GB |
- To enable autoscaling, set a compute size range using the slider. Autoscaling dynamically adjusts compute resources based on workload demand. Learn more: Autoscaling
- Adjust the scale-to-zero setting to increase or decrease the amount of inactive compute time before a compute suspends (from 60 seconds up to 7 days when enabled). You can also disable scale-to-zero for an always-active compute. Learn more: Scale to zero
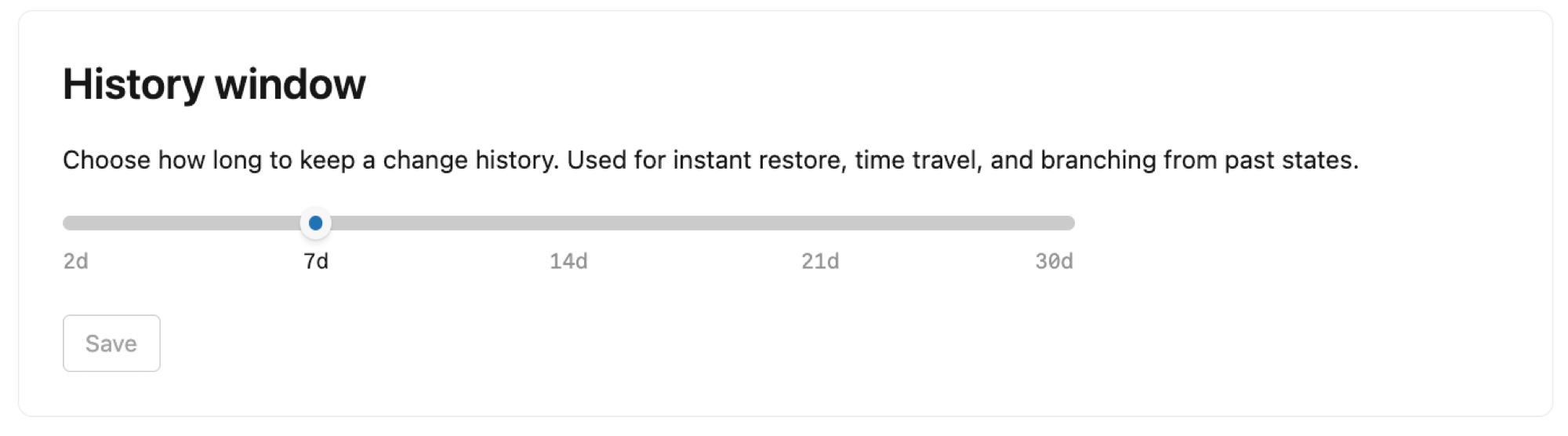
History window
Configure the history window length for your project. By default, Lakebase retains a history of changes for root branches in your project, enabling point-in-time restore for recovering lost data, querying data at a point in time for investigating data issues, and branching from past states for development workflows.
You can set the history window from 2 days up to 30 days, with a default of 7 days. Note that:
- Extending the history window increases your storage
- The history window setting affects all branches in your project
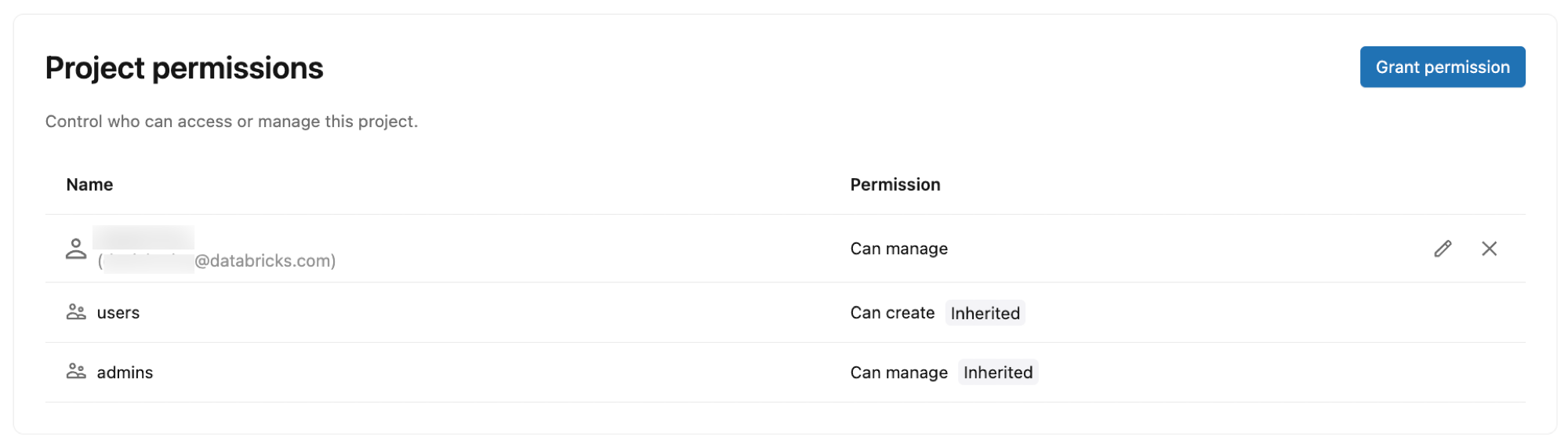
Project permissions
Control who can access and manage your Lakebase project by granting permissions to Databricks identities, groups, and service principals. Project permissions determine what actions users can perform within the project, such as creating branches, managing computes, and viewing connection details.
Permission types:
- CAN CREATE: View and create project resources
- CAN USE: View and use project resources (list, view, connect, and perform certain branch operations) without creating or deleting projects or branches
- CAN MANAGE: Full control over project configuration and resources
Default permissions:
When you create a project, the following permissions are automatically assigned:
- Project owner (the user who created the project): CAN MANAGE (full control)
- Workspace users: CAN CREATE (can view and create projects)
- Workspace admins: CAN MANAGE (full control)
To grant access to other users, see Manage project permissions.
Project permissions and database access are separate
Project permissions control Lakebase platform actions, while database access is controlled by Postgres roles and their associated permissions. See Create Postgres roles and Manage database permissions.
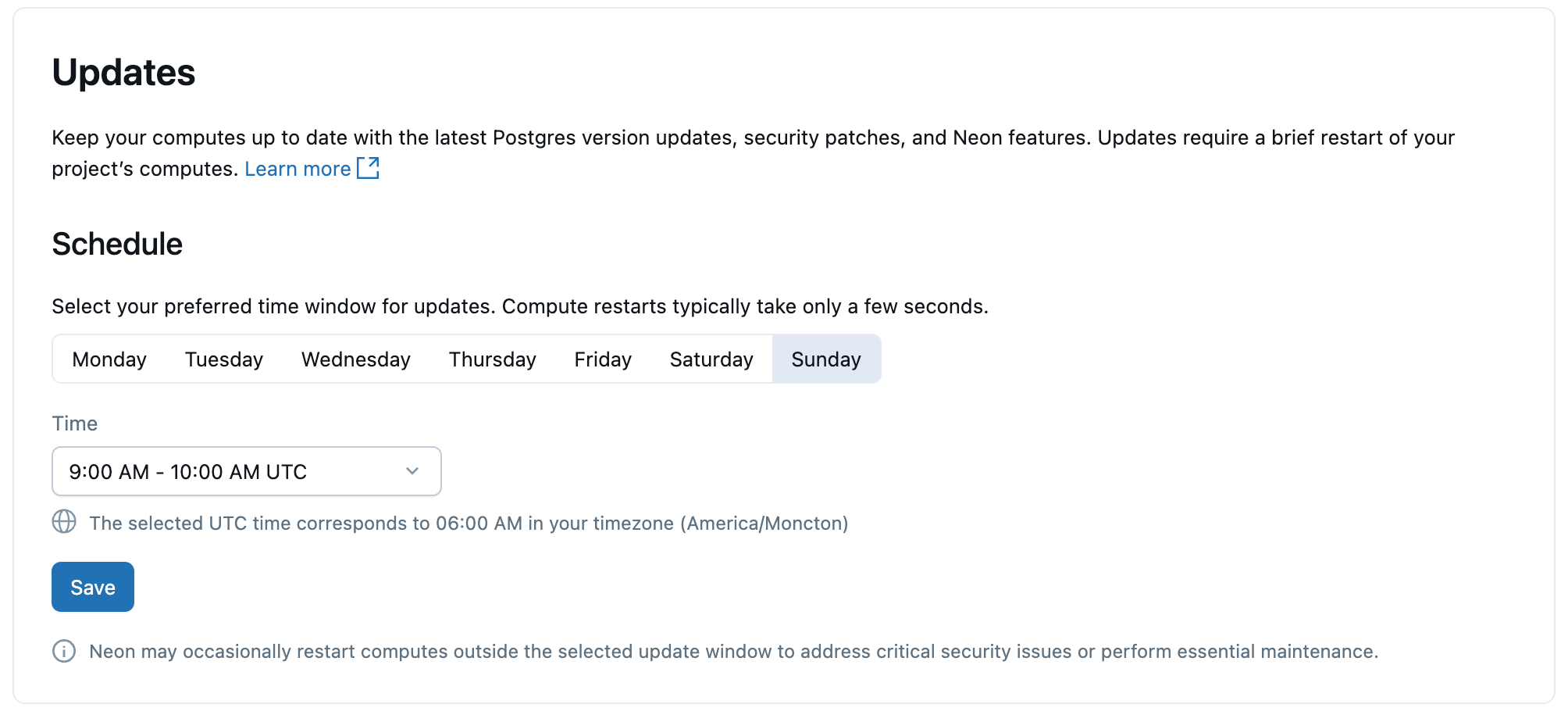
Updates
To keep your Lakebase computes and Postgres instances up to date, Lakebase automatically applies scheduled updates that include Postgres minor version upgrades, security patches, and platform features. Updates are applied to the computes within your project and require a brief compute restart that takes a few seconds.
Updates are applied automatically, but you can set a preferred day and time for updates. Restarts occur within your selected time window.
For detailed information about updates, see Manage updates.
Delete a project
When you delete a project, it enters a soft-deleted state by default and is retained for 7 days before being permanently deleted. During this window, you can recover the project and restore all its data. See Recover a deleted project. To skip the retention period and remove the project immediately, see Permanently delete a project.
While a project is soft-deleted, attempts to connect to it or retrieve database credentials return generic errors (such as endpoint not found or connection refused) rather than an error indicating that the project was deleted. If you encounter these errors unexpectedly, check whether the project has been soft-deleted by listing projects with show_deleted=true. See Find soft-deleted projects.
Before deleting
Databricks recommends deleting all associated Unity Catalog catalogs and synced tables before deleting the project. Otherwise, attempting to view catalogs or run SQL queries that reference them results in errors.
If you are not the owner of the tables or catalogs, you must reassign ownership to yourself before deletion.
Only users with CAN MANAGE permission on the Lakebase project can delete it. See Project ACLs and Manage project permissions for details.
Delete a project
To delete a project:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Navigate to your project's Settings in the Lakebase App.
- In the Delete project section, click Delete and enter the project name to confirm deletion.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name()}")
This is a long-running operation. The project and all its resources (branches, endpoints, databases, roles, data) will be deleted.
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
This is a long-running operation. The project and all its resources (branches, endpoints, databases, roles, data) will be deleted.
# Delete a project
databricks postgres delete-project projects/my-project
This command returns immediately. The project and all its resources will be deleted.
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
This is a long-running operation. The response includes an operation name that you can use to check the deletion status.
Permanently delete a project
To permanently delete a Lakebase project immediately without waiting for the 7-day soft-delete retention period to expire:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.delete_project(name="projects/my-project", purge=True)
operation.wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.DeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().deleteProject(
new DeleteProjectRequest()
.setName("projects/my-project")
.setPurge(true)
).waitForCompletion();
databricks postgres delete-project projects/my-project --purge
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project?purge=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Recover a deleted project
When you delete a Lakebase project, it enters a soft-deleted state and is retained for 7 days before being permanently deleted. During this window, you can recover the project and restore all its data.
What is restored
Recovering a soft-deleted project restores the following:
- All branches and their data
- All Postgres databases and roles
- All compute endpoints and their configurations
- Project settings, including compute defaults, restore window settings, and update preferences
- Project permissions
Some resources may require reconfiguration after recovery. Contact Databricks Support if you encounter issues after recovering a project.
Find soft-deleted projects
To list all projects including soft-deleted ones, use the show_deleted parameter. This is useful for finding the resource name of a project you want to recover.
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for project in w.postgres.list_projects(show_deleted=True):
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
if project.delete_time:
print(f" Deleted: {project.delete_time}")
print(f" Purge time: {project.purge_time}")
databricks postgres list-projects --show-deleted
curl -X GET "$WORKSPACE/api/2.0/postgres/projects?show_deleted=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Recover a project
To recover a soft-deleted Lakebase project:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.undelete_project(name="projects/my-project")
operation.wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.UndeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().undeleteProject(
new UndeleteProjectRequest().setName("projects/my-project")
).waitForCompletion();
databricks postgres undelete-project projects/my-project
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/undelete" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq