Storage architecture
Lakebase separates storage from compute. Your database data lives in a Databricks-managed distributed storage layer, independent of the compute instances that run your queries. Storage persists and remains highly available whether your compute is running, paused, or scaling.
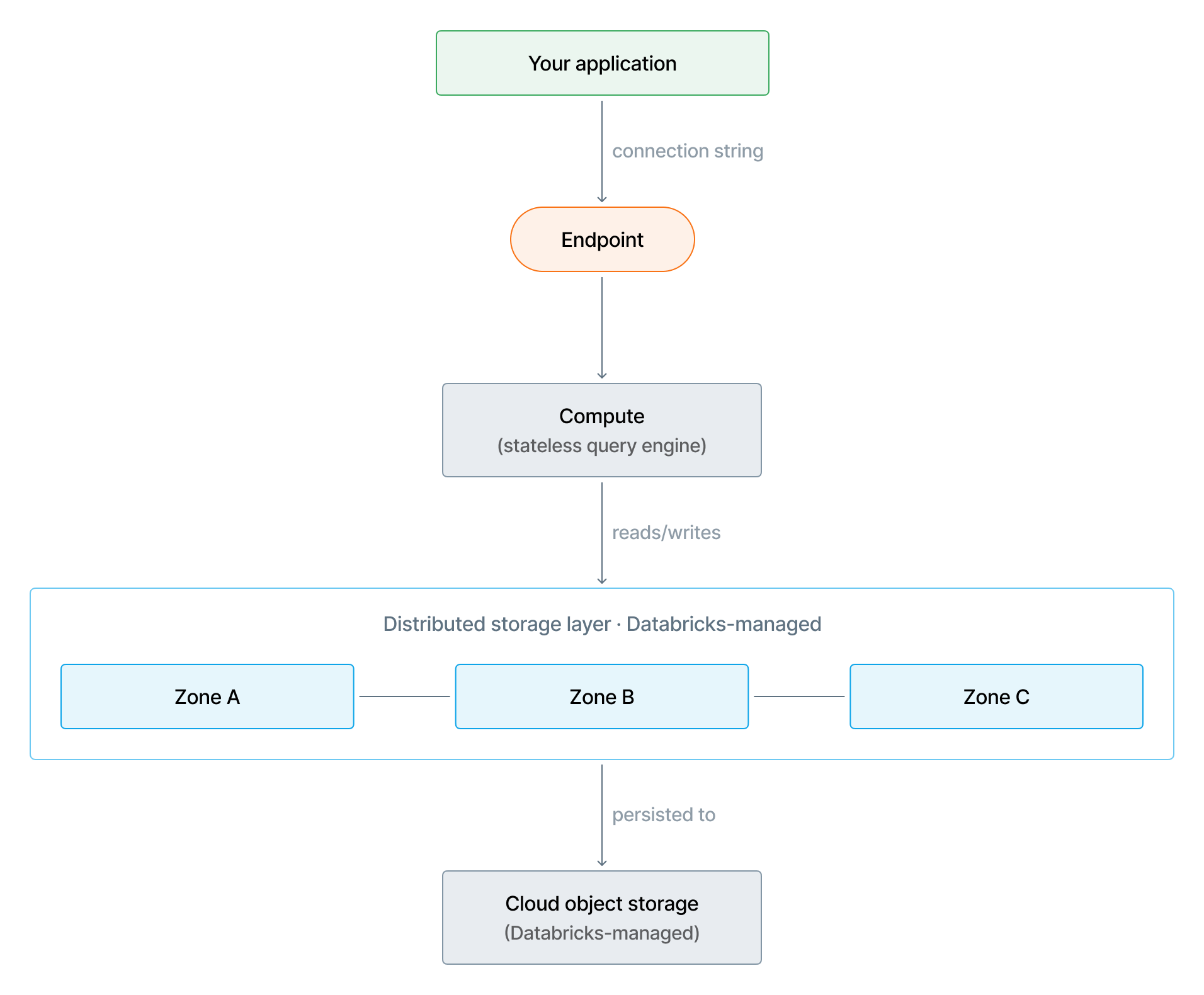
Storage layer
Lakebase uses a distributed storage architecture. No single machine holds the authoritative state of your database. Data is also persisted to Databricks-managed cloud object storage, the durability foundation for the entire storage layer. Cloud object storage is designed for extremely high durability and doesn't rely on asynchronous replication, so durability isn't affected by replication lag. Databricks manages storage redundancy configuration.
On AWS, Lakebase persists data to Amazon S3 as the cloud object storage layer.
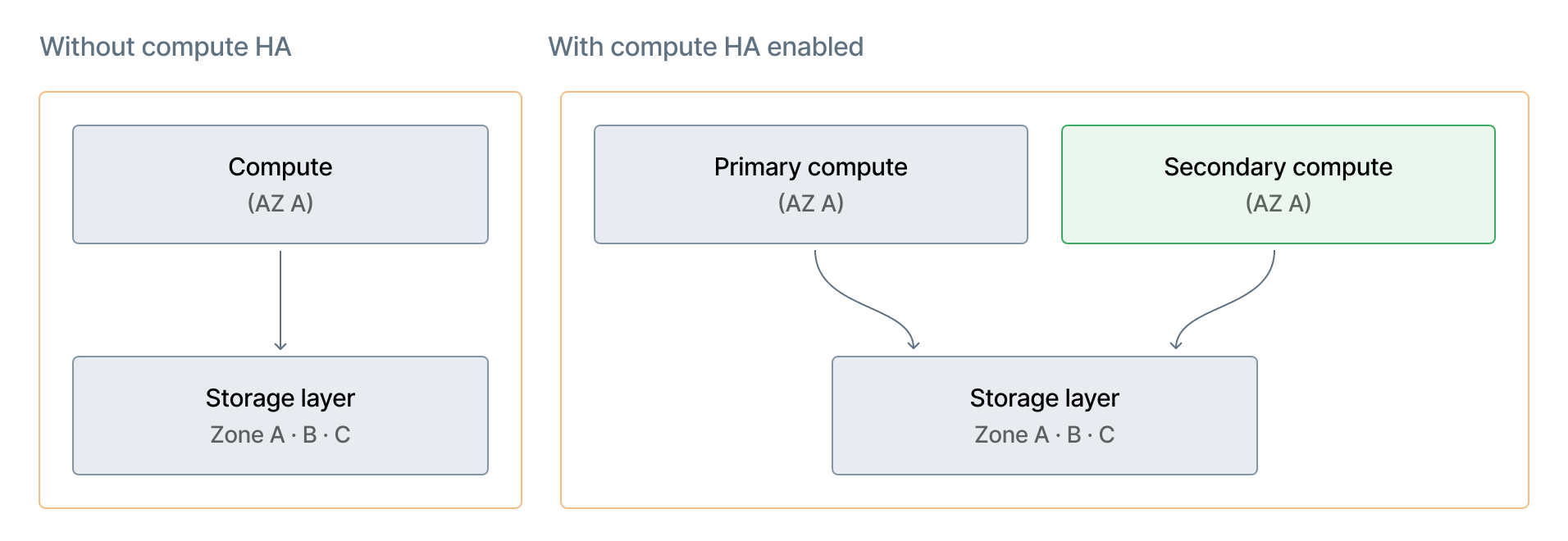
Storage redundancy is independent of compute HA
Lakebase storage redundancy and availability is managed by Databricks and is independent of the high availability (HA) compute setting. Enabling or disabling HA doesn't affect storage redundancy.
High availability is a compute-layer feature. It pre-provisions a secondary compute instance in a separate availability zone for automatic failover. Storage redundancy and compute HA are independent layers.
Characteristic | Storage redundancy | Compute high availability (HA) |
|---|---|---|
Mandatory | Yes | No |
Customer-configurable | No | Yes |
What it protects | Data durability and availability | Ability to execute queries |
How storage separation enables other features
The separation of storage from compute enables several Lakebase features:
- Zero data loss (RPO = 0): Because every committed transaction is durably persisted to cloud object storage before it is acknowledged, no committed data is lost when compute fails, restarts, scales to zero, or fails over.
- Instant branches: Lakebase creates branches using copy-on-write against shared storage. The process duplicates no data.
- Read replicas: Multiple compute instances read from the same shared storage layer. This approach requires no data replication.
- Scale-to-zero: Compute pauses, but storage persists. Data is immediately available when compute resumes.
- Fast failover: Because storage is separate from compute, failover doesn't involve moving data. Lakebase promotes a secondary compute instance, which connects to the existing storage.
Related information
- High availability: Configure compute-level redundancy for automatic failover across availability zones. See High availability.
- Manage high availability: Enable and configure the HA compute setting on your endpoint. See Manage high availability.
- Database branches: Learn how branches use copy-on-write storage to create instant isolated environments. See Branches.
- Read replicas: Add read-only compute instances that read from the same storage layer without data replication. See Read replicas.