分類
AIを使用して、ドキュメントを事前定義されたカテゴリに分類できます。
分類の例は次のとおりです:
- 顧客の通話記録を意図別に分類する
- コンテンツタイプによるドキュメントの分類
- センチメントによる製品レビューの分類
分類は、AI関数であるai_classifyを基盤としています。「 エージェント 」ページには、ドキュメントや非構造化テキストを迅速に分類し、分類フィールドで反復処理を行って、より良い結果を得るためのUIインターフェースが用意されています。
要件
-
以下を含むワークスペースです。
- サーバレス コンピュートが有効になっていること。 サーバレス コンピュートの要件を参照してください。
- Unity Catalogが有効です。「Unity Catalog のワークスペースを有効にする」を参照してください。
- ゼロ以外の予算を持つサーバレス利用ポリシーへのアクセス。
-
この機能は一部のリージョンでのみ利用可能です。AI 機能の利用可能性を参照してください。
-
強化されたセキュリティとコンプライアンスアドオンがあるワークスペースの場合、
ai_classifyの地域サポートで、適切なコンプライアンス標準を参照してください。- ワークスペースで有効にする方法については、Databricksプレビューを管理を参照してください。
-
ai_classifySQL関数を使用できます。 -
分類する非構造化データ。データは Unity Catalog ボリュームまたはテーブルにある必要があります。
- エージェントを構築するには、Unity Catalogボリュームに少なくとも1つのラベルなしドキュメント、またはテーブルに1つの行が必要です。
分類エージェントを作成
ワークスペースの左側のナビゲーションペインで、![]() エージェント に移動します。 エージェントの作成 をクリックし、 テキスト分類 を選択します。
エージェント に移動します。 エージェントの作成 をクリックし、 テキスト分類 を選択します。
ステップ1. ソースデータを選択します。
分類機能を使用してドキュメントを分類します。
-
ソースデータを選択してください。ドキュメントを含むボリュームまたはテキストデータを含むテーブルを選択できます。
-
エージェントの作成 をクリックします。
ステップ2. 分類ラベルを構成します
分類によってデータが処理された後、分類ラベルを構成および調整します。
分類ラベルを手動で追加するには:
- 分類ラベルを追加するには、 + ラベルを追加 をクリックしてください。
- ラベル名とオプションの説明を入力し、 [ラベルを追加] をクリックします。
- 追加したい各ラベルに対して、手順1~2を繰り返します。
- (オプション)エージェントに複数のラベルを返させたい場合は、**「複数のラベル」**を有効にします。
テーブルからラベルをインポートするには:
- テーブルからインポート をクリックします。
- テーブルを選択し、**次へ**をクリックします。
- ラベル列、説明列、およびSQLウェアハウスを選択します。
- インポートされたラベルを確認するには、**プレビュー**をクリックします。
- ラベルの内容にご満足いただけましたら、「ラベルのインポートと置き換え」をクリックしてください。
分類を実行するには、少なくとも2つのラベルが定義されている必要があります。ラベルの追加が完了したら、 [分類を保存して実行] をクリックします。
分類は、最大5つのドキュメントと行を分類し、結果を表示します。さらに追加することもできます。
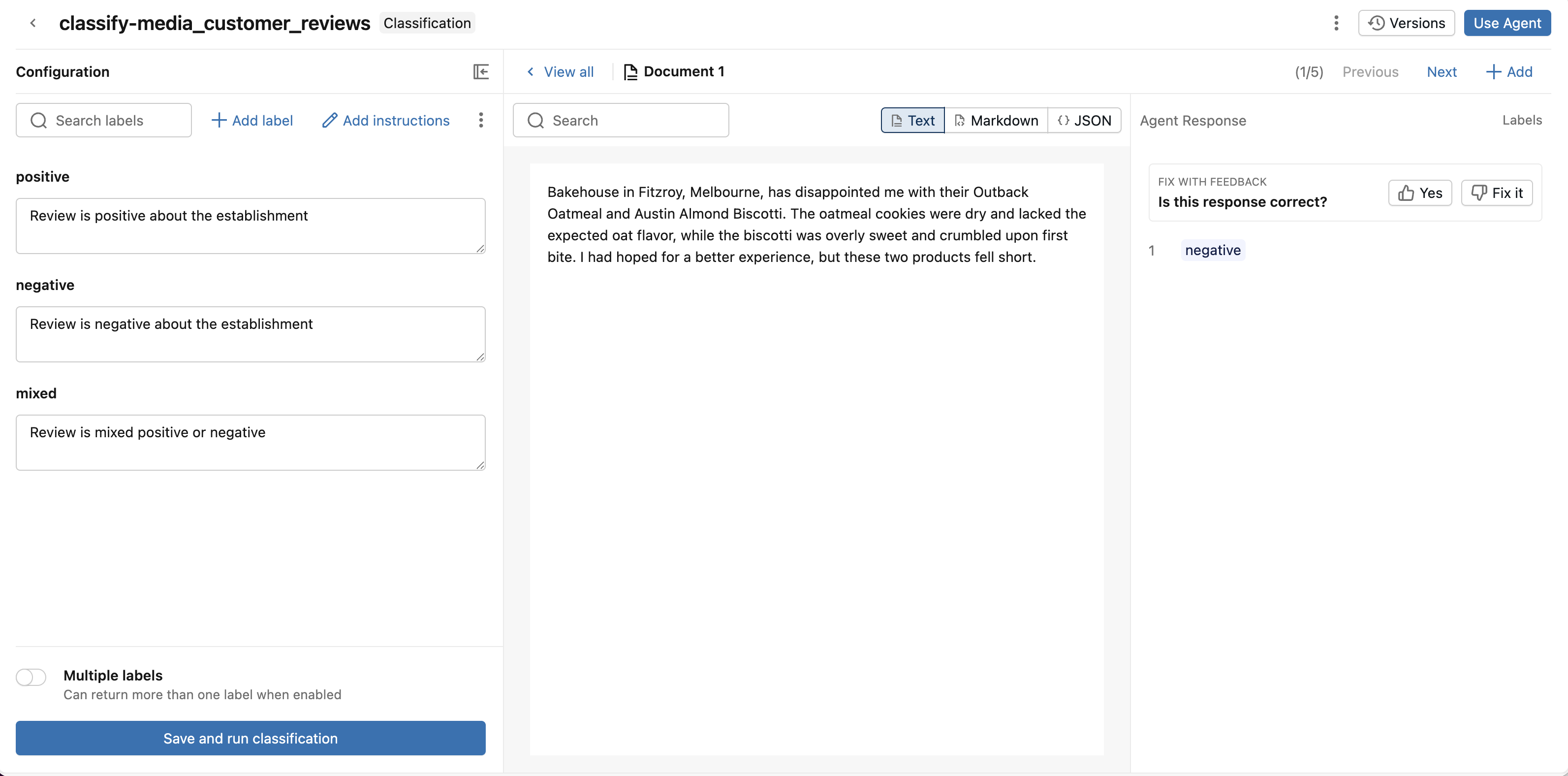
ステップ 3. 分類レスポンスのレビューと改善。
分類レスポンスを確認し、エージェント改善のためのフィードバックを提供してください。
-
ドキュメントと分類応答を確認します:
- 回答が正しい場合は、高評価してください。
- 応答が正しくない場合は、低評価を付けます。正しいラベルを選択して、分類が応答を修正できるようにします。 保存 をクリックします。
-
エージェントの応答を改善するには、分類ラベルの説明を調整してください。
-
エージェントのパフォーマンスを最適化するために、バージョンを比較します。 **「バージョン」** をクリックします。以前のバージョンの横にある**「比較」**をクリックして、以前のバージョンと現在のバージョンの分類ラベルの説明を比較します。以前のバージョンを復元するには、**「復元」** をクリックします。
ステップ 4: 分類エージェントを使用する
応答にご満足いただけた場合、大規模分類にエージェントをご利用ください。
右上の Use Agent をクリックします。次のいずれかを選択できます。
- ボリュームまたはテーブル全体をエージェントで分類するには、**SQL で実行**します。これにより、定義した分類ラベルを使用して
ai_classifyを利用するSQLクエリが開きます。SQLクエリでai_classifyを使用する方法の情報の詳細については、ai_classify関数を参照してください。 - 新しいデータでエージェントを呼び出すため、スケジュールされた間隔で実行される Lakeflow Pipelinesを作成します 。これにより、分類されたデータでストリーミングテーブルを更新するLakeFlow Pipelines が作成されます。新しいデータが到着したときに実行されるように、パイプラインのスケジュールを構成できます。LakeFlow Pipelinesに関する詳細情報については、Spark宣言型パイプラインを参照してください。
制限事項
制限事項を参照してください。