情報抽出
このページでは、情報抽出の新しいバージョンについて説明します。以前のバージョンの詳細については、「情報抽出の使用(レガシー)」を参照してください。
情報抽出は、定義されたスキーマを使用して、非構造化ドキュメントとテキストを重要な構造化された知見に変換します。これにより、非構造化テキスト、PDF、画像、またはテーブルに埋め込まれた情報を、分析、レポート作成、またはダウンストリームのエージェントやアプリケーションに直接使用できます。
情報抽出の例は次のとおりです:
- 契約から契約当事者と条件を抽出します。
- 請求書から明細項目と支払い条件を抽出します。
- 医療記録およびメモから主要な詳細を抽出します。
情報抽出は、AI 関数 ai_extract の上に構築されています。情報抽出には、定義された抽出スキーマで機能をカスタマイズおよび最適化するための視覚的な UI があります。
情報抽出は、各エージェントを動かす一時的なデータ変換、モデルチェックポイント、および内部メタデータを保存するために、デフォルトストレージを使用します。エージェントを削除すると、Databricks はエージェントに関連付けられているすべてのデータをデフォルトのストレージから削除します。
要件
-
以下を含むワークスペースです。
- サーバレス コンピュートが有効になっていること。 サーバレス コンピュートの要件を参照してください。
- Unity Catalogが有効です。「Unity Catalog のワークスペースを有効にする」を参照してください。
- ゼロ以外の予算を持つサーバレス利用ポリシーへのアクセス。
-
この機能は一部のリージョンでのみ利用可能です。AI 機能の利用可能性を参照してください。
-
強化されたセキュリティとコンプライアンスアドオンがあるワークスペースの場合、
- 適切なコンプライアンス標準については、
ai_extractの地域サポートを参照してください。 - ワークスペースで有効にする方法については、Databricksプレビューを管理を参照してください。
- 適切なコンプライアンス標準については、
-
ai_extractSQL関数を使用できます。 -
情報を抽出したい非構造化データ。データは Unity Catalog ボリュームまたはテーブルにある必要があります。
- エージェントを構築するには、Unity Catalogボリュームに少なくとも1つのファイル、またはテーブルに1行存在する必要があります。
情報の抽出エージェントを作成
ワークスペースの左側のナビゲーションペインで、![]() エージェント に移動します。 Create Agent > 情報抽出 をクリックします。
エージェント に移動します。 Create Agent > 情報抽出 をクリックします。
ステップ1: 情報を抽出するデータを選択します。
-
**データから開始**ページで、情報を抽出したいファイルまたはデータを選択します。次のいずれかを実行できます。
- 1つ以上のファイルをアップロードエリアにドラッグアンドドロップするか、クリックしてアップロードするファイルを参照します。
- サポートされているファイルタイプを持つUnity Catalogボリュームを選択するには、**[ボリュームの選択]**をクリックしてください。
- テーブルを選択 をクリックして、テキストデータを含む Unity Catalog のテーブルを選択してください。
-
テーブルを選択した場合、抽出するデータを含む列を選択してください。続行するには、文字列またはVARIANTなどのサポートされている型の列を選択する必要があります。テーブルにサポートされている列がない場合、別のテーブルを選択してください。
-
**エージェントの作成**をクリックします。このボタンは、有効なデータソースと、テーブルの場合はサポートされている列が選択された後にのみ有効になります。
ステップ2:抽出スキーマを構成して絞り込みます。
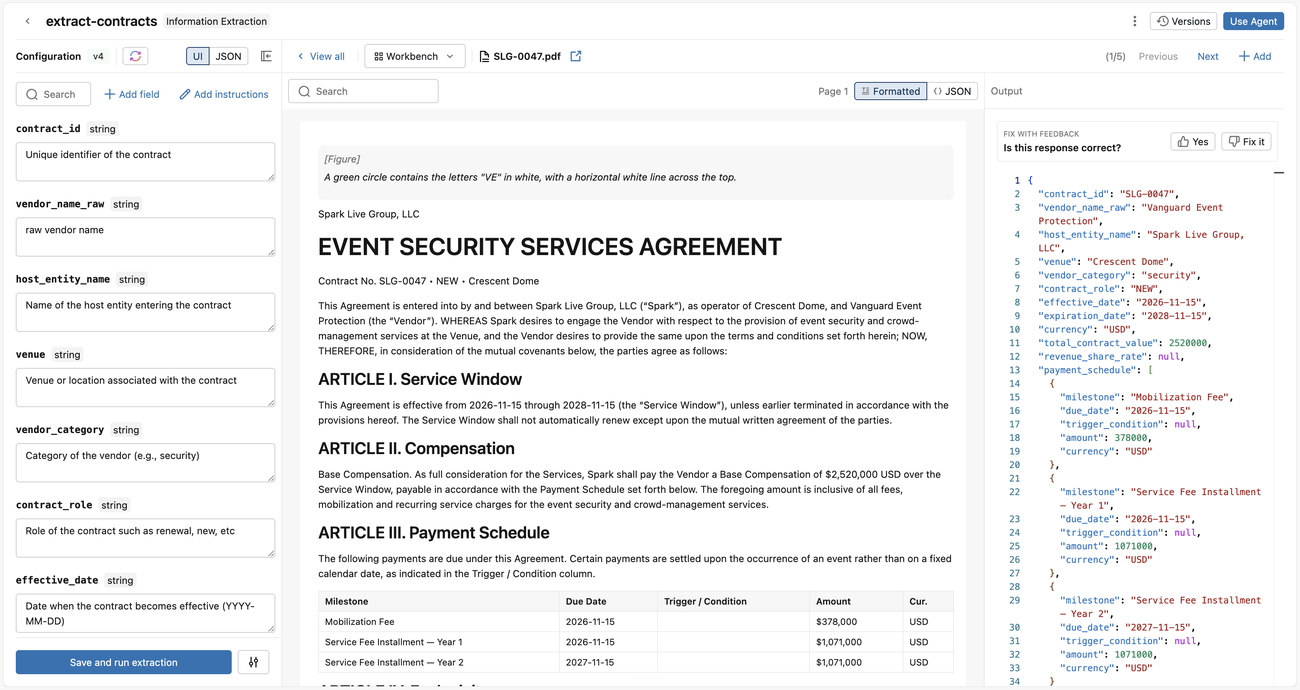
情報抽出でデータが処理された後、ドキュメントから抽出するデータを構成し、調整します。
-
構成で、抽出スキーマを定義します。これを行うにはいくつかの方法があります:
-
抽出したい情報を説明する自然言語を入力し、 スキーマの生成 をクリックしてください。情報抽出は、フィールド名と定義を含むJSONスキーマを自動的に生成します。必要に応じてこれらの説明を編集してください。
-
または、 Or, Define manually をクリックして、スキーマを手動で定義してください:
- [フィールドを追加] をクリックします。
- フィールド名、タイプ、説明を入力してください。
- 確認 をクリックします。
- 抽出したい各フィールドについて繰り返します。
- 「 抽出を保存して実行 」をクリックします。
-
JSON をクリックして、JSONスキーマを直接編集することもできます。完了したら、 変更を適用 をクリックしてください。
スキーマを更新して [抽出を保存して実行] をクリックするたびに、情報抽出は抽出エージェントを更新し、抽出を実行して、各入力の結果を表示します。
-
-
左側で、解析されたドキュメントとエージェントの抽出を確認します。抽出結果を2つの方法で反復します。まず、 保存して抽出を実行 を押すと説明が自動調整される、1つまたは複数の入力について自然言語のフィードバックを提供します。次に、 保存して抽出を実行 を押すと適用されるスキーマの説明を手動で修正します。
-
バージョンを使用して、以前の設定と比較または復元します。 [バージョン] をクリックし、次に [比較] をクリックして、以前のバージョンのスキーマ定義と現在のバージョンを比較します。以前のバージョンを復元するには、 [復元] をクリックします。
ステップ3。抽出品質を評価して改善します。
エージェントのパフォーマンスを測定し、体系的に改善するためには、ラベル付けされたデータセットに対してエージェントを評価してください。評価では、既知の正解(グラウンドトゥルース)に対して各抽出がスコアリングされるため、バージョン全体のフィールドレベルの精度を追跡し、修正が必要なフィールドを特定できます。
評価データセットを追加
評価を実行する前に、Unity Catalogに評価データセットが必要です。データセットは、2つの列を持つUnity Catalogテーブルである必要があります。
- 抽出元のテキストまたはドキュメントを含む「**入力列**」。これは
STRINGテキスト、またはai_parse_documentのVARIANT出力である場合があります。 - 期待される抽出結果をJSON文字列として含む「**正解データ列**」。各値は、エージェントの抽出スキーマに準拠し、
ai_extractの高度なスキーマと一致する必要があります。
評価を実行します。
抽出エージェントの評価を実行するには:
- ワークベンチで評価ドロップダウンを開き、 [評価を実行] をクリックします。これにより、 [評価ランの作成] ダイアログが開きます。
- **評価データセットテーブル**で、ラベル付きの例を保持するUnity Catalogテーブルを選択します。
- **列マッピング**で、エージェントの入力を含む**入力列**と、期待される応答を含む**正解の列**を選択します。
- 「**評価を実行**」をクリックします。情報抽出は現在の構成を新しいバージョンとして保存し、各行をその真値に対してスコアリングします。
評価結果を確認します。
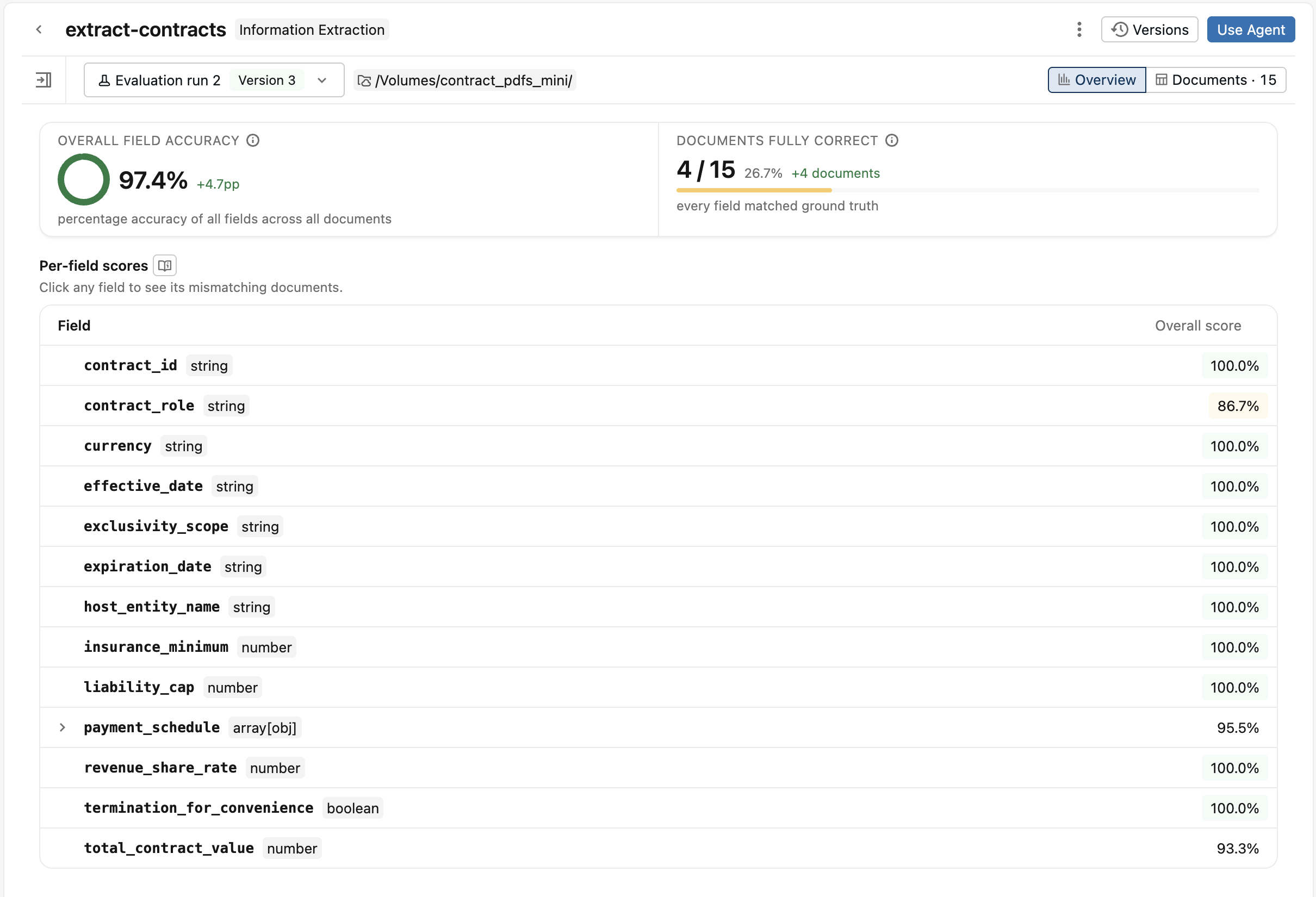
ランの進行に伴い、ドキュメントが**ドキュメント**tabにストリームされ、不一致のフィールドはドキュメントごとに表示されます。ランが完了すると、情報抽出に**概要**tabが表示され、以下が含まれます。
- **全体的なフィールド精度**と**完全に正しいドキュメント**を含むスコアカード。以前の評価ランが存在する場合、スコアカードにはそのランからの変更が表示されます。
- **フィールドごとのスコア**テーブル。任意のフィールドをクリックすると、そのドリルダウンが開き、正確性、精度、再現率、F1が表示されます。**失敗したドキュメントを表示**をクリックして、そのフィールドの抽出に失敗した各ドキュメントとその抽出された出力結果を確認してください。
[Documents] tabに切り替えて、個々のドキュメントを調べます。各行には、一致したフィールドの比率と一致しなかったフィールドが表示されます。特定の一致しないフィールドを含むドキュメントをフィルターするには、 [フィールド] ドロップダウンを使用します。ドキュメントをクリックして、エージェントの応答を正解データと並べて比較します。
スキーマを改善して繰り返し、 評価をラン を再度クリックして、変更がスコアにどのように影響したかを確認してください。
ステップ 4. 抽出エージェントを使用します。
エージェントの性能に満足したら、エージェントを使用して情報を抽出してください。
右上の Use Agent をクリックします。次のいずれかを選択できます。
- エージェントを使用してすべてのデータから情報を抽出するには、**SQL で実行**してください。これにより、定義されたスキーマに従い、ボリュームまたはテーブルから情報を抽出する
ai_extractを使用した SQL クエリが開きます。SQLクエリでai_extractを使用する方法の情報の詳細については、ai_extract関数を参照してください。 - 新しいデータでエージェントを呼び出すため、スケジュールされた間隔で実行される Lakeflow Pipelinesを作成します 。これにより、抽出されたデータでストリーミングテーブルを更新するLakeFlow Pipelinesが作成されます。新しいデータが到着したときに実行されるように、パイプラインのスケジュールを設定できます。LakeFlow Pipelinesに関する詳細情報については、Spark宣言型パイプラインを参照してください。
制限事項
-
制限事項を参照してください。
-
情報抽出エージェントの最大コンテキスト長は128kトークンです。
-
共用スキーマタイプはサポートされていません。