AIエージェントを作成してModel Servingにデプロイする。
新しいユースケースの場合、Databricksは、エージェントのコード、サーバー設定、およびデプロイワークフローを完全に制御するために、Databricks Appsへのエージェントのデプロイを推奨しています。AIエージェントを作成してDatabricks Appsにデプロイするを参照してください。既存のエージェントを移行するには、Model ServingからDatabricks Appsにエージェントを移行するを参照してください。
このページでは、カスタム エージェント、および LangGraph や OpenAI などの一般的なエージェント作成ライブラリを使用して、Python で AI エージェントを作成する方法について説明します。
要件
Databricksでは、エージェントを開発する際に、MLflow Pythonクライアントの最新バージョンをインストールすることをお勧めします。
このページのアプローチを使用してエージェントを作成してデプロイするには、以下をインストールしてください。
databricks-agents1.2.0 以降mlflow3.1.3以上- Python 3.10 以降。
- この要件を満たすには、サーバレスコンピュートまたはDatabricks Runtime 13.3 LTS以降を使用してください。
%pip install -U -qqqq databricks-agents mlflow
Databricksは、エージェントを作成するために Databricks AI Bridge 統合パッケージをインストールすることも推奨しています。これらの統合パッケージは、エージェント作成フレームワークとSDK全体で、Genie エージェントやAI SearchなどのDatabricks AI機能と対話するAPIの共有レイヤーを提供します。
- OpenAI
- LangChain/LangGraph
- DSPy
- Pure Python agents
%pip install -U -qqqq databricks-openai
%pip install -U -qqqq databricks-langchain
%pip install -U -qqqq databricks-dspy
%pip install -U -qqqq databricks-ai-bridge
ResponsesAgentを使用してエージェントを作成します
Databricks では、本番運用グレードのエージェントを作成するために、MLflow インターフェース ResponsesAgent をお勧めします。ResponsesAgentを使用すると、任意のサードパーティ製フレームワークでエージェントを構築し、Databricks AI機能と統合して、堅牢なログ記録、トレース、評価、デプロイ、およびモニタリング機能を実現できます。
ResponsesAgent スキーマは OpenAI Responses スキーマと互換性があります。OpenAI Responses の詳細については、OpenAI: Responses vs. ChatCompletion を参照してください。
古いChatAgentインターフェースはDatabricksで引き続きサポートされています。ただし、新しいエージェントの場合は、DatabricksはMLflowの最新バージョンとResponsesAgentインターフェースの使用をお勧めします。
レガシー入力および出力エージェントスキーマ (Model Serving)を参照してください。

ResponsesAgent 以下の利点があります:
-
高度なエージェント機能
- マルチエージェントのサポート
- ストリーミング出力 : 出力を小さなチャンクでストリームします。
- **包括的なツール呼び出しメッセージ履歴**: 品質と会話管理を向上させるため、中間ツール呼び出しメッセージを含む複数のメッセージを返します。
- ツール呼び出し確認のサポート
- 長時間実行ツールのサポート。
-
効率化された開発、デプロイ、モニタリング
- あらゆるフレームワークを使用してエージェントを作成する :
ResponsesAgentインターフェースを使用して既存のエージェントをラップすると、AI Playground、Agent Evaluation、およびAgentモニタリングとのすぐに利用できる互換性が得られます。 - タイプ付きオーサリングインターフェース :IDEおよびノートブックのオートコンプリートを活用しながら、タイプ付きPythonクラスを使用してエージェントコードを記述します。
- 自動署名推論 : MLflow は、エージェントをログ記録する際に
ResponsesAgent署名を自動的に推論し、登録とデプロイを簡素化します。ログ記録中のモデルシグネチャの推論を参照してください。 - 自動トレース : MLflow は、
predictおよびpredict_stream関数を自動的にトレースし、ストリームされた応答を集約して、評価と表示を容易にします。 - AI Gatewayで強化された推論テーブル : AI Gateway推論テーブルは、デプロイされたエージェントに対して自動的に有効になり、詳細なリクエストログメタデータへのアクセスを提供します。
- あらゆるフレームワークを使用してエージェントを作成する :
ResponsesAgent の作成方法については、次のセクションの例とMLflow ドキュメント - Model Serving の ResponsesAgent を参照してください。
ResponsesAgentの例
次のノートブックでは、一般的なライブラリを使用してストリーミングおよび非ストリーミングの ResponsesAgent を作成する方法を説明しています。これらのエージェントの機能を拡張する方法については、「エージェントをツールに接続する」を参照してください。
- OpenAI
- LangGraph
- DSPy
Databricksでホストされているモデルを使用するOpenAIシンプルなチャットエージェント
OpenAI MCPツール呼び出しエージェント
Databricksホスト型モデルを使用するOpenAIツール呼び出しエージェント
OpenAI ホスト型モデルを使用する OpenAI ツール呼び出しエージェント
LangGraph MCP ツール呼び出しエージェント
DSPy シングルターン ツールコールエージェント
マルチエージェントの例
マルチエージェントシステムを作成する方法を学ぶには、マルチエージェントシステムでGenieを使用する (Model Serving)を参照してください。
ステートフルエージェントの例
Lakebase をメモリストアとして使用して、短期および長期メモリを持つステートフルエージェントを作成する方法については、AI エージェントメモリ(Model Serving)を参照してください。
非会話型エージェントの例
複数ターンの対話を管理する会話型エージェントとは異なり、非会話型エージェントは明確に定義されたタスクを効率的に実行することに重点を置いています。この合理化されたアーキテクチャは、独立したリクエストに対してより高いスループットを可能にします。
非会話型エージェントを作成する方法については、MLflowを使用した非会話型AIエージェントを参照してください。
すでにエージェントがある場合はどうなりますか?
LangChain、LangGraph、または同様のフレームワークで構築されたエージェントをすでにお持ちの場合、Databricks で使用するためにエージェントを書き直す必要はありません。代わりに、既存のエージェントをMLflow ResponsesAgentインターフェイスでラップするだけです。
-
mlflow.pyfunc.ResponsesAgentを継承するPythonラッパークラスを記述します。ラッパークラス内で、既存のエージェントを属性
self.agent = your_existing_agentとして参照します。 -
ResponsesAgentpredictクラスは、非ストリーミングリクエストを処理するためにResponsesAgentResponseを返す メソッドを実装する必要があります。以下は、ResponsesAgentResponsesスキーマの例です。Pythonimport uuid
# input as a dict
{"input": [{"role": "user", "content": "What did the data scientist say when their Spark job finally completed?"}]}
# output example
ResponsesAgentResponse(
output=[
{
"type": "message",
"id": str(uuid.uuid4()),
"content": [{"type": "output_text", "text": "Well, that really sparked joy!"}],
"role": "assistant",
},
]
) -
predict関数で、ResponsesAgentRequestからの受信メッセージをエージェントが想定する形式に変換します。エージェントが応答を生成した後、その出力をResponsesAgentResponseオブジェクトに変換します。
既存のエージェントを ResponsesAgent に変換する方法については、次のコード例を参照してください:
- Basic conversion
- Streaming with code re-use
- Migrate from ChatCompletions
非ストリーミングエージェントの場合は、predict関数で入力と出力を変換します。
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
)
class MyWrappedAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Call your existing agent (non-streaming)
agent_response = self.agent.invoke(messages)
# Convert your agent's output to ResponsesAgent format, assuming agent_response is a str
output_item = (self.create_text_output_item(text=agent_response, id=str(uuid4())),)
# Return the response
return ResponsesAgentResponse(output=[output_item])
ストリーミングエージェントの場合、メッセージを変換するコードの重複を避けるために、ロジックを賢く再利用できます。
from typing import Generator
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages, included in full examples linked below
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Stream from your existing agent
item_id = str(uuid4())
aggregated_stream = ""
for chunk in self.agent.stream(messages):
# Convert each chunk to ResponsesAgent format
yield self.create_text_delta(delta=chunk, item_id=item_id)
aggregated_stream += chunk
# Emit an aggregated output_item for all the text deltas with id=item_id
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(text=aggregated_stream, id=item_id),
)
既存のエージェントがOpenAI ChatCompletions APIを使用している場合、そのコアロジックを書き直すことなく、ResponsesAgentに移行できます。ラッパーを追加する対象:
- 受信した
ResponsesAgentRequestメッセージを、エージェントが期待するChatCompletions形式に変換します。 ChatCompletions出力をResponsesAgentResponseスキーマに変換します。- オプションで、
ChatCompletionsから増分デルタをResponsesAgentStreamEventオブジェクトにマッピングすることで、ストリーミングに対応します。
from typing import Generator
from uuid import uuid4
from databricks.sdk import WorkspaceClient
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
# Legacy agent that outputs ChatCompletions objects
class LegacyAgent:
def __init__(self):
self.w = WorkspaceClient()
self.OpenAI = self.w.serving_endpoints.get_open_ai_client()
def stream(self, messages):
for chunk in self.OpenAI.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=messages,
stream=True,
):
yield chunk.to_dict()
# Wrapper that converts the legacy agent to a ResponsesAgent
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# `agent` is your existing ChatCompletions agent
self.agent = agent
def prep_msgs_for_llm(self, messages):
# dummy example of prep_msgs_for_llm
# real example of prep_msgs_for_llm included in full examples linked below
return [{"role": "user", "content": "Hello, how are you?"}]
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# process the ChatCompletion output stream
agent_content = ""
tool_calls = []
msg_id = None
for chunk in self.agent.stream(messages): # call the underlying agent's stream method
delta = chunk["choices"][0]["delta"]
msg_id = chunk.get("id", None)
content = delta.get("content", None)
if tc := delta.get("tool_calls"):
if not tool_calls: # only accommodate for single tool call right now
tool_calls = tc
else:
tool_calls[0]["function"]["arguments"] += tc[0]["function"]["arguments"]
elif content is not None:
agent_content += content
yield ResponsesAgentStreamEvent(**self.create_text_delta(content, item_id=msg_id))
# aggregate the streamed text content
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(agent_content, msg_id),
)
for tool_call in tool_calls:
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_function_call_item(
str(uuid4()),
tool_call["id"],
tool_call["function"]["name"],
tool_call["function"]["arguments"],
),
)
agent = MyWrappedStreamingAgent(LegacyAgent())
for chunk in agent.predict_stream(
ResponsesAgentRequest(input=[{"role": "user", "content": "Hello, how are you?"}])
):
print(chunk)
完全な例については、ResponsesAgentの例を参照してください。
ストリーミング応答
ストリーミングを使用すると、エージェントは完全な応答を待たずに、リアルタイムのチャンクで応答を送信できます。ResponsesAgentでストリーミングを実装するには、一連のデルタイベントを発行し、その後に最終完了イベントを発行します。
- デルタイベントの出力 :同じ
item_idを使用して複数のoutput_text.deltaイベントを送信し、リアルタイムでテキストチャンクをストリーム配信します。 - **完了イベントで終了**:完全な最終出力テキストを含むデルタイベントと同じ を持つ最終的な
response.output_item.doneイベントを送信します。item_id
各Deltaイベントは、テキストのチャンクをクライアントにストリームします。最終的な完了イベントには完全な応答テキストが含まれており、Databricksに次の処理を行うよう指示します。
- MLflowトレースを使用してエージェントの出力をトレースする
- AI Gateway 推論テーブルでのストリーム応答の集約
- AI Playground UI ですべての出力を表示する
ストリーミングエラー伝播
Databricksは、databricks_output.errorの下で最後のトークンを使用してストリーミング中に発生したエラーを伝播します。このエラーを適切に処理し、表示するかどうかは、呼び出し元のクライアント次第です。
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
高度な機能
カスタム入力と出力
一部のシナリオでは、client_typeやsession_idなどの追加のエージェント入力、あるいは今後のやり取りのチャット履歴に含めるべきではないソースリンクのような出力が必要となる場合があります。
これらのシナリオの場合、MLflow ResponsesAgentはフィールドcustom_inputsとcustom_outputsをネイティブにサポートします。ResponsesAgent の例で上記のすべてのリンクされた例で、request.custom_inputsを介してカスタム入力にアクセスできます。
Agent Evaluationレビューアプリは、追加の入力フィールドを持つエージェントのトレースのレンダリングをサポートしていません。
カスタムの入力と出力を設定する方法を学ぶには、以下のノートブックを参照してください。
AI Playgroundとレビューアプリでcustom_inputsを提供する
エージェントが custom_inputs フィールドを使用して追加の入力を受け入れる場合は、AI Playground と レビューアプリの両方でこれらの入力を手動で提供できます。
-
AI PlaygroundまたはAgent Review Appで、歯車アイコン
 を選択します。
を選択します。 -
custom_inputs を有効にします。
-
エージェントに定義されている入力スキーマに一致する JSON オブジェクトを指定します。
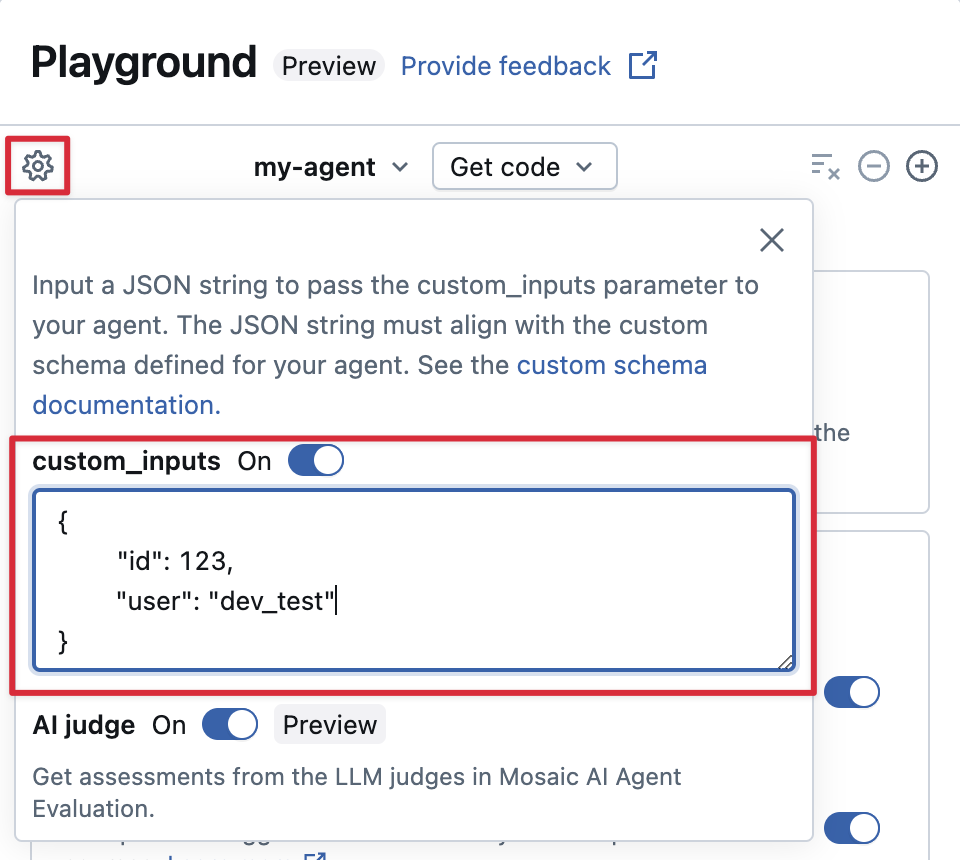
カスタムレトリーバースキーマを指定する
AIエージェントは一般的に、レトリーバーを使用して、AI Searchインデックスから非構造化データを検索およびクエリします。たとえば、レトリーバーツールについては、エージェントを非構造化データに接続する を参照してください。
Databricks製品機能(以下を含む)を有効にするために、MLflow RETRIEVERスパンを使用してエージェント内でこれらのレトリーバーをトレースします:
- AI Playground UIに取得したソースドキュメントへのリンクを自動的に表示する
- Agent Evaluationで取得根拠と関連性ジャッジを自動的に実行します。
Databricksは、databricks_langchain.VectorSearchRetrieverToolやdatabricks_openai.VectorSearchRetrieverToolなどのDatabricks AI Bridgeパッケージによって提供されるレトリーバーツールを使用することをお勧めします。これらはすでにMLflowレトリーバースキーマに準拠しているためです。AI Bridgeを使用してレトリーバーをローカルで開発するを参照してください。
エージェントにカスタムスキーマを持つレトリーバースパンが含まれている場合は、コードでエージェントを定義する際にmlflow.models.set_retriever_schemaを呼び出します。これにより、レトリーバーの出力列がMLflowの想定フィールド(primary_key、text_column、doc_uri)にマップされます。
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: The Largest Open Source AI Engineering Platform'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
doc_uri 列は、リトリーバーのパフォーマンスを評価する上で特に重要です。doc_uri は、リトリーバーによって返されたドキュメントの主要な識別子であり、グラウンドトゥルース評価セットと比較できます。評価セット (MLflow 2) を参照してください。
デプロイメントの考慮事項
Databricks Model Serving の準備をする
Databricks は、Databricks Model Serving 上の分散環境に ResponsesAgent をデプロイします。これは、マルチターン会話中に、同じサービングレプリカがすべてのリクエストを処理しない場合があることを意味します。エージェントの状態管理における以下の影響に留意してください。
-
ローカルキャッシュを避ける :
ResponsesAgentをデプロイする際、マルチターン会話ですべてのリクエストを同じレプリカが処理すると想定しないでください。各ターンについて、ディクショナリのResponsesAgentRequestスキーマを使用して内部状態を再構築します。 -
スレッドセーフな状態 : マルチスレッド環境での競合を防ぐため、エージェントの状態をスレッドセーフにするように設計します。
-
predict関数で状態を初期化します:predictの初期化中ではなく、ResponsesAgent関数が呼び出されるたびに状態を初期化します。ResponsesAgentレベルで状態を保存すると、単一のResponsesAgentレプリカが複数の会話からのリクエストを処理できるため、会話間で情報が漏洩し、競合が発生する可能性があります。
複数の環境にわたるデプロイのコードをパラメータ化します。
異なる環境で同じエージェントコードを再利用するために、エージェントコードをパラメータ化します。
パラメータは、Pythonディクショナリーまたは.yamlファイルで定義するキーと値のペアです。
コードを構成するには、Python辞書または.yamlファイルを使用してModelConfigを作成します。ModelConfigは、柔軟な構成管理を可能にするキーと値のパラメーターのセットです。たとえば、開発中に辞書を使用し、その後、本番運用デプロイメントとCI/CDのために.yamlファイルに変換できます。
以下にModelConfigの例を示します:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-meta-llama-3-3-70b-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
エージェントコードでは、.yamlファイルまたはディクショナリからデフォルト(開発)設定を参照できます:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-meta-llama-3-3-70b-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
次に、エージェントをログに記録する際に、ログに記録されたエージェントをロードするときに使用するパラメーターのカスタムセットを指定するために、log_model の model_config パラメーターを指定します。MLflow のドキュメント - ModelConfigをご覧ください。
同期コードまたはコールバックパターンを使用します。
安定性と互換性を確保するために、エージェントの実装では同期コードまたはコールバックベースのパターンを使用してください。
Databricksは、エージェントをデプロイする際、最適な同時実行性とパフォーマンスを提供するために非同期通信を自動的に管理します。カスタムイベントループや非同期フレームワークを導入すると、RuntimeError: This event loop is already running and caused unpredictable behaviorのようなエラーが発生する可能性があります。
Databricks は、エージェントを開発する際に、asyncio の使用やカスタムイベントループの作成などの非同期プログラミングを避けることを推奨します。