エージェントメモリ
メモリを使用すると、AI エージェントは会話の早い段階や以前の会話からの情報を記憶できます。メモリを使用すると、エージェントはコンテキストを認識した応答を提供し、時間の経過とともにパーソナライズされたエクスペリエンスを構築します。
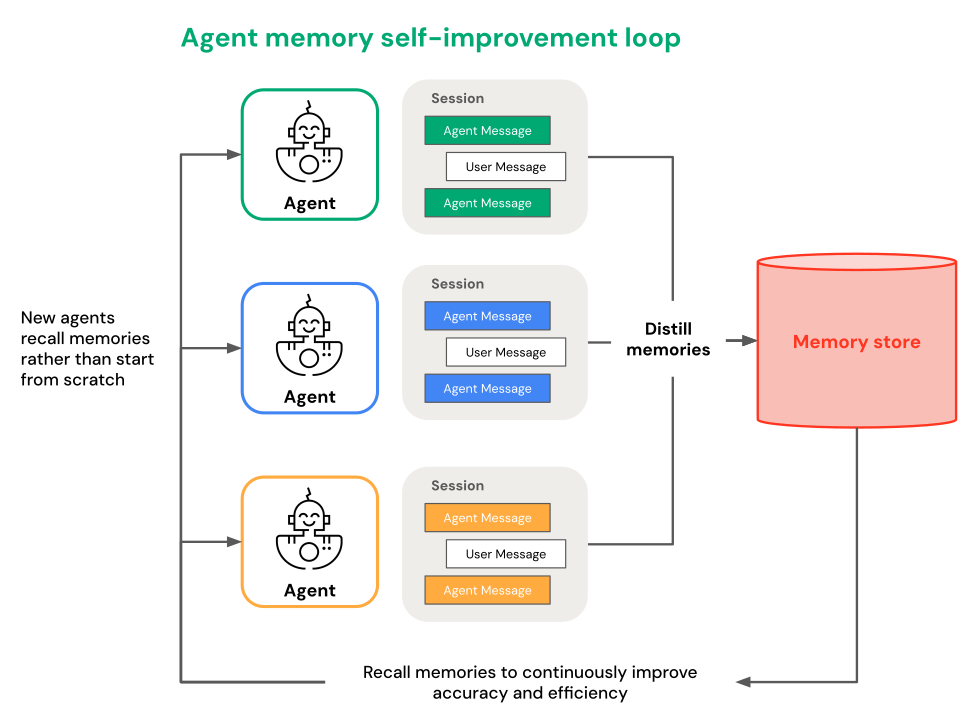
エージェントに次のことを実行させたい場合は、エージェントのメモリを使用します。
- ユーザー設定、過去の決定、またはセッションをまたいで蓄積されたコンテキストを記憶します。
- 複数のエージェントとプロジェクト間で知識と設定を共有します。
- 時間の経過とともに精度と効率が向上します。
メモリオプションを選択
Databricks にはエージェントのメモリに 2 つのアプローチがあります。
-
- マネージドエージェントメモリ(ベータ版)
- Databricksは、Unity Catalog ガバナンスで保護されたメモリインフラストラクチャを管理します。ユーザーごとのクロスセッションメモリを必要とする、任意のフレームワークで構築されたエージェントをサポートします。
-
- セルフマネージド型エージェントメモリ(Lakebase)
- Lakebaseを使用して、基盤となるメモリストアを管理します。LangGraphまたはOpenAI Agents SDKで構築され、短期および長期の会話状態への直接SQLアクセスを必要とするカスタムエージェントをサポートします。
エージェントのメモリスケーリング
メモリはさまざまな形式で提供されます。エピソード記憶は、会話ログやユーザーフィードバックなどの生のインタラクションをキャプチャし、一方、セマンティック記憶は、それらのインタラクションを再利用可能な事実とルールに蒸留します。また、メモリを個々のユーザーにスコープしたり、チーム全体で組織の知識として共有したりすることもできます。
エージェントがこのコンテキストをさらに蓄積するにつれて、その精度と効率が向上する可能性があります。Databricksのリサーチでは、このパターンをメモリスケーリングと呼んでいます。これらの調査結果については、DatabricksのリサーチによるAIエージェントのメモリスケーリングを参照してください。