RAG 用の非構造化データパイプラインの構築
この記事では、生成AI アプリケーション用の非構造化データパイプラインを構築する方法について説明します。 非構造化パイプラインは、Retrieval-Augmented Generation (RAG) アプリケーションに特に役立ちます。
テキストファイルやPDFなどの非構造化コンテンツを、AIエージェントや他のレトリーバーがクエリできるベクトルインデックスに変換する方法を学びます。さらに、チャンキング、インデックス作成、データ解析を最適化するためにパイプラインをエクスペリメントおよび調整する方法も学びます。これにより、パイプラインのトラブルシューティングとエクスペリメントを行い、より良い結果を達成することができます。
非構造化 データパイプライン ノートブック
このノートブックでは、この記事の情報を実装して、非構造化データパイプラインを作成する方法を示します。
Databricks 非構造化 データパイプライン
データパイプラインの主要コンポーネント
非構造化データを使用するRAGアプリケーションの基盤は、データパイプラインです。このパイプラインは、非構造化データをキュレーションおよび準備し、RAGアプリケーションが効果的に使用できる形式にする役割を担います。

このデータパイプラインはユースケースによって複雑になる場合がありますが、RAGアプリケーションを最初に構築する際に考慮すべき主要なコンポーネントは次のとおりです。
-
コーパスの構成と取り込み:特定のユースケースに基づいて適切なデータソースとコンテンツを選択してください。
-
データの前処理:生データを、埋め込みと取得に適したクリーンで一貫性のある形式に変換します。
-
チャンク化:解析されたデータをより小さく、管理しやすいチャンクに分割し、効率的な取得を実現します。
-
エンベディング:チャンク化されたテキストデータを、その意味的意味を捉える数値ベクトル表現に変換します。
-
「インデックス作成とストレージ」:検索パフォーマンスを最適化するために効率的なベクトルインデックスを作成します。
コーパスの構成と取り込み
RAGアプリケーションは、適切なデータコーパスがなければ、ユーザークエリに応答するために必要な情報を取得できません。正しいデータは、アプリケーション固有の要件と目標に完全に依存するため、利用可能なデータのニュアンスを理解するために時間を費やすことが重要です。詳細情報については、エージェント開発ライフサイクルを参照してください。
例えば、顧客サポートボットを構築する際に、以下のものを含めることを検討できます。
- ナレッジベース ドキュメント
- よくある質問(FAQ)
- 製品マニュアルと仕様書
- トラブルシューティングガイド
プロジェクトの最初からドメインエキスパートや関係者と協力し、データコーパスの品質と網羅性を向上させる可能性のある関連コンテンツの特定とキュレーションを支援します。これらは、ユーザーが送信する可能性のあるクエリの種類に関する知見を提供し、含めるべき最も重要な情報に優先順位を付けるのに役立ちます。
Databricks では、スケーラブルで増分的な方法でデータを取り込むことをお勧めします。Databricks は、 SaaS アプリケーションや API 統合用のフルマネージド コネクタなど、データ取り込みのためのさまざまな方法を提供しています。 ベスト プラクティスとして、生のソース データを取り込んでターゲット テーブルに格納する必要があります。このアプローチにより、データの保存、トレーサビリティ、監査が保証されます。Lakeflow Connectの標準コネクタを参照してください。
データの前処理
データが取り込まれたら、生データをクリーンアップして、埋め込みと取得に適した一貫性のある形式にフォーマットすることが不可欠です。
解析
リトリーバーアプリケーションに適したデータソースを特定した後、次のステップは、生データから必要な情報を抽出することです。解析として知られるこのプロセスには、非構造化データをRAGアプリケーションが効果的に使用できる形式に変換することが含まれます。
使用する特定の解析手法とツールは、作業しているデータの種類によって異なります。例えば:
- テキストドキュメント(PDF、Wordドキュメント): unstructuredやPyPDF2などの既製のライブラリは、さまざまなファイル形式を処理でき、解析プロセスをカスタマイズするためのオプションを提供します。
- HTMLドキュメント: BeautifulSoupやlxmlのようなHTML解析ライブラリを使用して、ウェブページから関連コンテンツを抽出できます。これらのライブラリは、HTML構造をナビゲートし、特定の要素を選択し、目的のテキストまたは属性を抽出するのに役立ちます。
- 画像とスキャンされたドキュメント: 画像からテキストを抽出するには、通常、光学文字認識 (OCR) テクニックが必要です。一般的な OCR ライブラリには、Tesseract などのオープンソースライブラリや、Amazon Textract、Azure AI Vision OCR、Google クラウド Vision API などの SaaS 版があります。
データ解析のベストプラクティス
解析により、データがクリーンで構造化され、埋め込み生成とAI Searchの準備ができています。データを解析する際は、以下のベストプラクティスを考慮してください:
- データクレンジング: 抽出されたテキストを前処理して、ヘッダー、フッター、特殊文字などの不要な情報やノイズのある情報を削除します。RAGチェーンが処理する必要がある不要な、または不正な形式の情報の量を削減します。
- エラーと例外の処理: 解析プロセス中に発生する問題を特定し解決するために、エラー処理とログメカニズムを実装します。これにより、問題を迅速に特定し、修正するのに役立ちます。そうすることで、ソースデータの品質に関する上流の問題が明らかになることがよくあります。
- 解析ロジックのカスタマイズ: データの構造と形式に応じて、最も関連性の高い情報を抽出するために、解析ロジックをカスタマイズする必要がある場合があります。事前の追加作業が必要になる場合がありますが、必要に応じて時間をかけてこれを行ってください。そうすることで、多くの場合、下流での品質上の問題を未然に防ぐことができます。
- パース品質の評価: 出力サンプルを手動で確認することにより、パースされたデータの品質を定期的に評価してください。これにより、パースプロセスにおける問題や改善点を見つけることができます。
エンリッチメント
追加のメタデータでエンリッチデータを補完し、ノイズを削除します。エンリッチはオプションですが、アプリケーション全体のパフォーマンスを大幅に向上させることができます。
メタデータ抽出
ドキュメントのコンテンツ、コンテキスト、構造に関する重要な情報を取り込むメタデータを生成および抽出することで、RAG アプリケーションの検索品質とパフォーマンスを大幅に向上させることができます。メタデータは、関連性を向上させ、高度なフィルタリングを可能にし、ドメイン固有の検索要件をサポートする追加のシグナルを提供します。
LangChain や LlamaIndex のようなライブラリは、関連付けられた標準メタデータを自動的に抽出できる組み込みパーサーを提供していますが、特定のユースケースに合わせて調整されたカスタムメタデータでこれを補完することが役立つことがよくあります。このアプローチにより、重要なドメイン固有の情報が確実に捕捉され、ダウンストリームの検索と生成が向上します。メタデータ強化の自動化に、大規模言語モデル(LLM)も使用できます。
メタデータの種類は次のとおりです。
- ドキュメントレベルのメタデータ: ファイル名、URL、作成者情報、作成および変更タイムスタンプ、GPS座標、ドキュメントのバージョン管理。
- コンテンツベースのメタデータ: 抽出されたキーワード、要約、トピック、固有表現、およびドメイン固有のタグ(製品名やPIIまたはHIPPAなどのカテゴリ)。
- 構造メタデータ: セクションヘッダー、目次、ページ番号、および意味的なコンテンツの境界(章またはセクション)。
- コンテキストメタデータ: ソースシステム、取り込み日、データ機密性レベル、オリジナル言語、または国際的な指示。
チャンク化されたドキュメントまたはそれに対応するエンベディングと一緒にメタデータを保存することは、最適なパフォーマンスにとって不可欠です。これにより、取得される情報を絞り込み、アプリケーションの精度とスケーラビリティを向上させることもできます。さらに、メタデータをハイブリッド検索パイプラインに統合することで、ベクトル類似性検索とキーワードベースのフィルタリングを組み合わせることができ、特に大規模なデータセットや特定の検索条件のシナリオにおいて、関連性を高めることができます。
重複排除
ソースによっては、重複ドキュメントやほぼ重複したドキュメントが発生する場合があります。たとえば、1 つ以上の共有ドライブから取得すると、同じドキュメントの複数のコピーが複数の場所に存在する可能性があります。それらのコピーの一部には、微妙な変更が含まれている場合があります。同様に、ナレッジベースには、製品ドキュメントやブログ記事の下書きのコピーが含まれている場合があります。これらの重複がコーパスに残っている場合、最終インデックスに非常に冗長なチャンクが発生し、アプリケーションのパフォーマンスが低下する可能性があります。
メタデータのみを使用して一部の重複を排除できます。たとえば、項目に同じタイトルと作成日があっても、異なるソースまたは場所からの複数のエントリがある場合、メタデータに基づいてそれらをフィルタリングできます。
ただし、これだけでは不十分な場合があります。 ドキュメントの内容に基づいて重複を特定して排除するために、ローカリティセンシティ ハッシュと呼ばれる手法を使用できます。 具体的には、ここでは MinHash と呼ばれる手法がうまく機能し、 Spark ML では Spark の実装が既に利用可能です。 これは、ドキュメントに含まれる単語に基づいてドキュメントのハッシュを作成することで機能し、それらのハッシュを結合することで重複または重複の近くを効率的に識別できます。 大まかに言うと、これは4つのステップからなるプロセスです。
- 各ドキュメントの特徴量ベクトルを作成します。必要に応じて、ストップワードの削除、ステミング、レマタイゼーションなどの技術を適用して結果を改善することを検討し、その後 n-gram にトークン化します。
- MinHashモデルを適合させ、Jaccard距離用MinHashを使用してベクトルをハッシュ化します。
- これらのハッシュを使用して類似結合を実行し、重複またはほぼ重複する各ドキュメントの結果セットを生成します。
- 保持したくない重複をフィルターで除外します。
ベースラインの重複排除ステップでは、保持するドキュメントを任意に選択できます (たとえば、各重複の結果で最初のもの、または重複の中からランダムに選択するなど)。潜在的な改善策としては、他のロジック (たとえば、最終更新、公開ステータス、最も信頼できるソースなど) を使用して、重複する「最適」なバージョンを選択することです。また、マッチング結果を改善するために、フィーチャ化のステップとMinHashモデルで使用されるハッシュテーブルの数をエクスペリメントする必要があることに注意してください。
詳細については、 locality-sensitive ハッシュ に関するSparkドキュメントを参照してください。
フィルタリング
コーパスに取り込むドキュメントの中には、その目的に関連がないため、古すぎるか信頼できないため、または有害な表現のような問題のあるコンテンツが含まれているため、エージェントにとって有用でないものがあるかもしれません。しかし、他のドキュメントには、エージェントを通じて公開したくない機密情報が含まれている可能性もあります。
したがって、ドキュメントに毒性分類器を適用してフィルターとして使用できる予測を生成するなど、メタデータを使用してこれらのドキュメントを除外するステップをパイプラインに含めることを検討してください。もう1つの例は、ドキュメントをフィルター処理するために、ドキュメントに個人識別情報(PII)検出アルゴリズムを適用することです。
最後に、エージェントに供給するドキュメントソースはすべて、悪意のあるアクターがデータポイズニング攻撃を仕掛ける潜在的な攻撃ベクトルとなります。それらを特定して排除するのに役立つ検出およびフィルタリングメカニズムを追加することも検討できます。
チャンク化
生データをより構造化された形式に解析し、重複を削除して不要な情報を除外すると、次のステップは、それをチャンクと呼ばれるより小さく管理しやすい単位に分割することです。大規模なドキュメントをより小さく意味的に集中したチャンクにセグメント化することで、取得したデータがLLMのコンテキストに収まるようにし、注意散漫になったり無関係な情報を含めたりすることを最小限に抑えます。チャンク化に関する選択は、LLMが提供する取得データに直接影響を与え、RAGアプリケーションにおける最適化の最初のレイヤーの1つとなります。
データをチャンクに分割する際は、以下の要素を考慮してください。
- チャンキング戦略: 元のテキストをチャンクに分割する手法です。これには、文、段落、特定の文字数/トークン数による分割といった基本的な手法や、より高度なドキュメント固有の分割戦略が含まれます。
- チャンクサイズ:より小さいチャンクは特定の詳細に焦点を当てる可能性がありますが、周囲のコンテキスト情報の一部が失われる可能性があります。 より大きなチャンクはより多くのコンテキストを捉える可能性がありますが、無関係な情報が含まれる場合や、計算コストが高くなる場合があります。
- チャンク間の重複: データをチャンクに分割する際に、重要な情報が失われないように、隣接するチャンク間にある程度の重複を含めることを検討してください。重複により、チャンク間の連続性とコンテキストの保持が保証され、取得結果が向上します。
- セマンティックの一貫性: 可能であれば、関連する情報を含みながらも、意味のあるテキスト単位として独立できる、意味的に一貫性のあるチャンクを作成することを目指します。 これは、段落、セクション、トピックの境界など、元のデータの構造を考慮することで実現できます。
- **メタデータ:** ソースドキュメント名、セクション見出し、または製品名などの関連するメタデータ は、取得を改善できます。この追加情報は、取得クエリをチャンクに一致させるのに役立ちます。
データのチャンク化戦略
適切なチャンキング方法を見つけることは、反復的であり、コンテキストに依存します。万能なアプローチはありません。最適なチャンクサイズと方法は、特定のユースケースと処理されるデータの性質によって異なります。概して、チャンキング戦略は次のように見なすことができます。
- 固定サイズチャンク: テキストを、固定数の文字やトークンなどの所定のサイズのチャンクに分割します(例えば、LangChain CharacterTextSplitter )。任意の数の文字/トークンで分割する方法はすばやく簡単に設定できますが、通常、一貫性のある意味的に整合性のとれたチャンクにはなりません。このアプローチは、本番運用レベルのアプリケーションではほとんど機能しません。
- **段落ベースのチャンク分割:**テキスト内の自然な段落境界を使用してチャンクを定義します。この方法は、段落が関連情報を含むことが多いため、チャンクのセマンティックの一貫性を維持するのに役立ちます(例:LangChain RecursiveCharacterTextSplitter)。
- 形式固有のチャンク分割: Markdown や HTML などの形式には、チャンク境界を定義できる固有の構造があります(たとえば、Markdown の見出し)。LangChain の MarkdownHeaderTextSplitter や HTML の header/section ベースのスプリッターをこの目的に使用できます。
- セマンティックチャンク分割: トピックモデリングなどの技術を適用して、テキスト内の意味的に一貫性のあるセクションを特定できます。これらのアプローチは、各ドキュメントのコンテンツまたは構造を分析し、トピックの変更に基づいて最も適切なチャンク境界を決定します。基本的なアプローチよりも複雑ですが、セマンティックチャンク分割は、テキスト内の自然な意味区切りにより合致するチャンクを作成するのに役立ちます(例: LangChain SemanticChunkerを参照)。
例:固定サイズのチャンク化
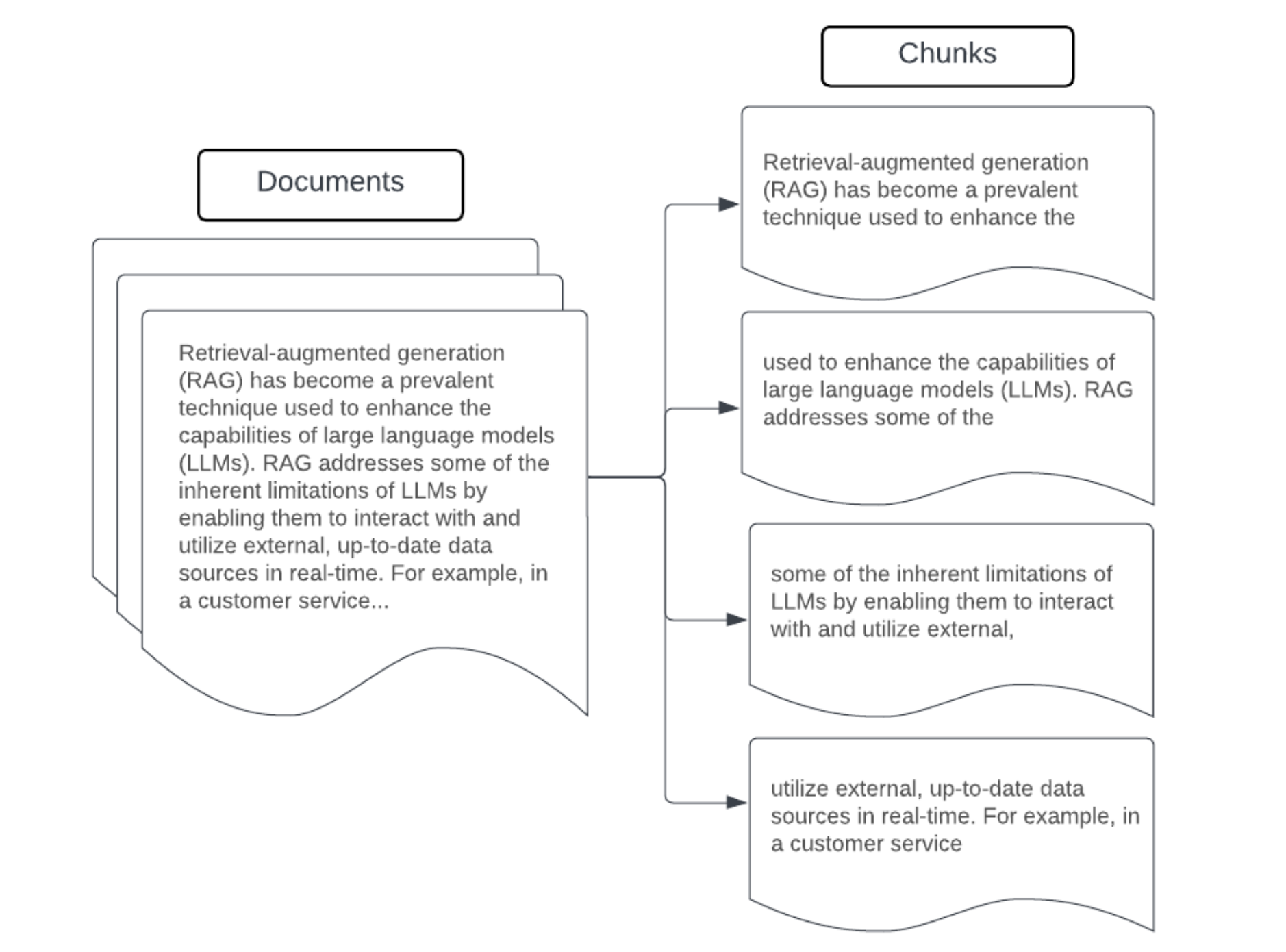
LangChainのRecursiveCharacterTextSplitterをchunk_size=100、chunk_overlap=20で使用する固定サイズチャンク化の例。ChunkVizは、Langchainの文字スプリッターと組み合わせて、さまざまなチャンクサイズとチャンクの重複値が結果のチャンクにどのように影響するかを視覚化するためのインタラクティブな方法を提供します。
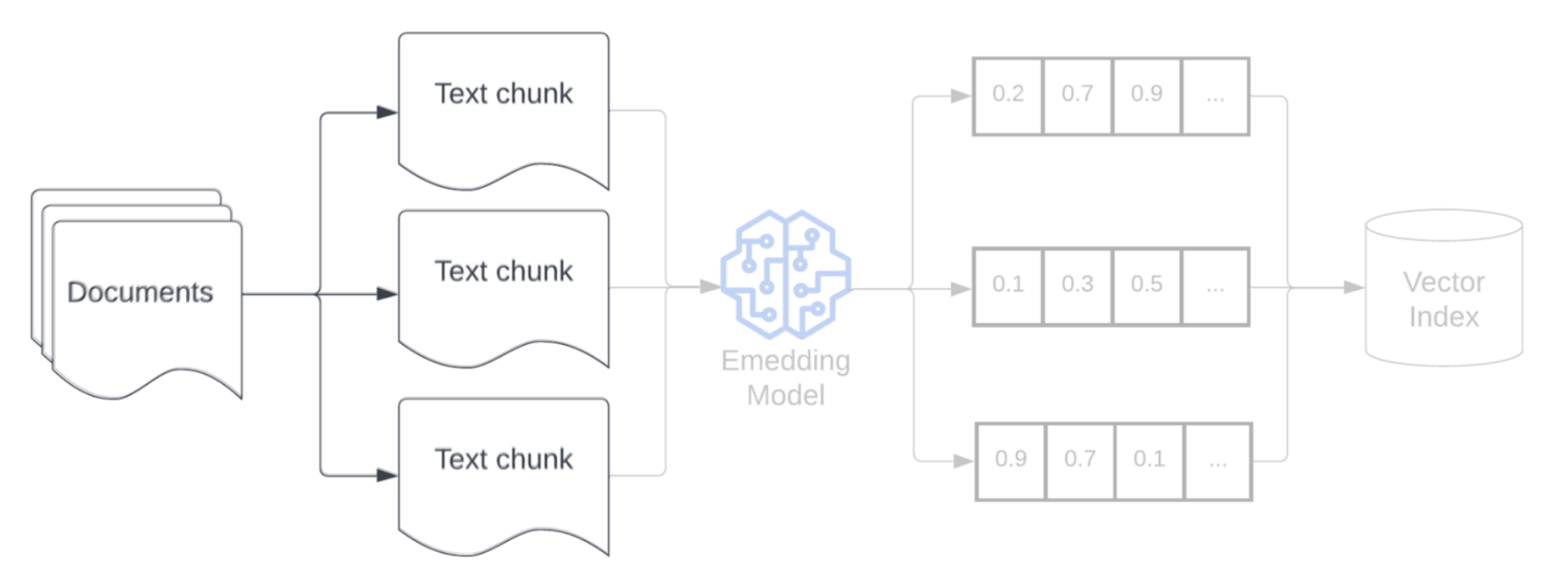
エンベディング
データをチャンク化した後、次のステップは、エンベディングモデルを使用してテキストチャンクをベクトル表現に変換することです。 埋め込みモデルは、各テキスト チャンクを、そのセマンティックな意味をキャプチャするベクトル表現に変換します。 エンベディングでは、チャンクを密なベクトルとして表現することで、検索クエリとの意味的類似性に基づいて、最も関連性の高いチャンクを迅速かつ正確に取得できます。 取得クエリは、データ パイプラインにチャンクを埋め込むために使用されるのと同じエンベディングモデルを使用して、クエリ時に変換されます。
エンベディングモデルを選択するときは、次の要素を考慮してください。
-
モデルの選択: 各エンベディングモデルには微妙な違いがあり、使用可能なベンチマークではデータの特定の特性を捉えていない可能性があります。類似のデータでトレーニングされたモデルを選択することが重要です。また、特定のタスク用に設計された使用可能なエンベディングモデルを調べることも有益です。MTEBのような標準的なリーダーボードで順位が低いものも含め、さまざまな既製のエンベディングモデルをエクスペリメントします。検討すべき例をいくつか示します。
-
最大トークン数: 選択した埋め込みモデルの最大トークン制限を把握します。この制限を超えるチャンクを渡すと、それらは切り捨てられ、重要な情報が失われる可能性があります。たとえば、bge-large-en-v1.5 は最大512トークンの制限があります。
-
**モデルサイズ:** 大規模な埋め込みモデルは一般的に性能は優れていますが、より多くのコンピューティングリソースが必要です。特定のユースケースと利用可能なリソースに基づいて、パフォーマンスと効率のバランスを取る必要があります。
-
ファインチューニング: RAG アプリケーションが、社内の略語や用語などのドメイン固有の言語を扱う場合は、ドメイン固有のデータで埋め込みモデルをファインチューニングすることを検討してください。これにより、モデルは特定のドメインのニュアンスや用語をより適切に捉えられるようになり、検索パフォーマンスの向上につながることがよくあります。
インデックスとストレージ
パイプラインの次の手順では、前の手順で生成されたエンベディングとメタデータにインデックスを作成します。 この段階では、高次元ベクトルのエンベディングを効率的なデータ構造に整理し、高速で正確な類似検索を可能にします。
AI Searchエンドポイントとインデックスをデプロイすると、AI Searchは、クエリの高速かつ効率的なルックアップを保証します。最適なインデックス作成手法のテストや選択について心配する必要はありません。
本番運用RAGパイプラインには、DatabricksはAI Searchを推奨します。チャンクとメタデータは、Databricksが管理するエンべディングを使用し、低レイテンシーの類似性クエリを提供するAI Searchインデックスを支えるDeltaテーブルに保存されます。メタデータをエンべディングと一緒に同じDeltaテーブルに保存することで、取得時の効率的なフィルタリングが可能になります。