AI Search検索品質を評価
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。Databricksのプレビューを管理するを参照してください。
AI Search は、データに対するさまざまな検索戦略の関連性を測定・比較する組み込みの検索品質評価を提供します。ドキュメントから評価クエリを自動的に生成し、複数の検索戦略を実行し、詳細なレポートを生成できます。
要件
マネージド Delta Sync AI Searchインデックス「AI Searchエンドポイントとインデックスの作成」を参照してください。
権限
評価ジョブおよび結果ダッシュボードは、AI Search インデックスから Unity Catalog の権限を継承します。インデックスへのクエリアクセス権を持つ任意のユーザーは、評価実行を開始し、結果ダッシュボードを表示できます。評価の実行を開始したユーザーは、ジョブのオーナーであり、インデックスのオーナーではありません。
AI Searchの検索品質評価のしくみ
評価はデータに対して4段階のパイプラインを実行します:
- クエリーの生成 :システムはソーステーブルからドキュメントをサンプリングし、LLM を使用して現実的な検索クエリーを生成します。自然言語クエリーとキーワードクエリーが混在するクエリーを生成します。
- 複数の戦略を横断して検索 : 生成された各クエリは、ANN、ハイブリッド、全文検索など、複数の取得戦略を用いてインデックスに対して実行されます。各戦略は、リランカーありとなしでも評価されます。このアプローチは、同じクエリセットで戦略を横に並べて比較します。各取得戦略の詳細については、取得アルゴリズムを参照してください。
- 関連性スコア :LLMジャッジが、すべてのクエリと取得されたドキュメントのペアを4段階の関連度スケールで評価します。
- コンピュート メトリクスおよび分析 :システムは信頼区間付きで検索品質メトリクスを計算します。結果は保持されるため、後で確認したり、評価実行間で比較したりできます。
検索品質評価実行を開始
手順を開始するには、AI Searchインデックスページで「検索品質評価」をクリックしてください。インデックスメタデータに基づいてデフォルト値があらかじめ入力されているため、設定は不要です。
実行が完了したら、「結果を表示」をクリックして結果ダッシュボードを表示します。ダッシュボードの概要については、「結果ダッシュボード」を参照してください。
いつでも新しい評価を始めるには、「新しい評価を開始」をクリックしてください。
ダッシュボードの結果
ダッシュボードには評価実行の結果が表示されます。 実行を選択 ドロップダウン メニューを使用して、表示する実行を選択します。
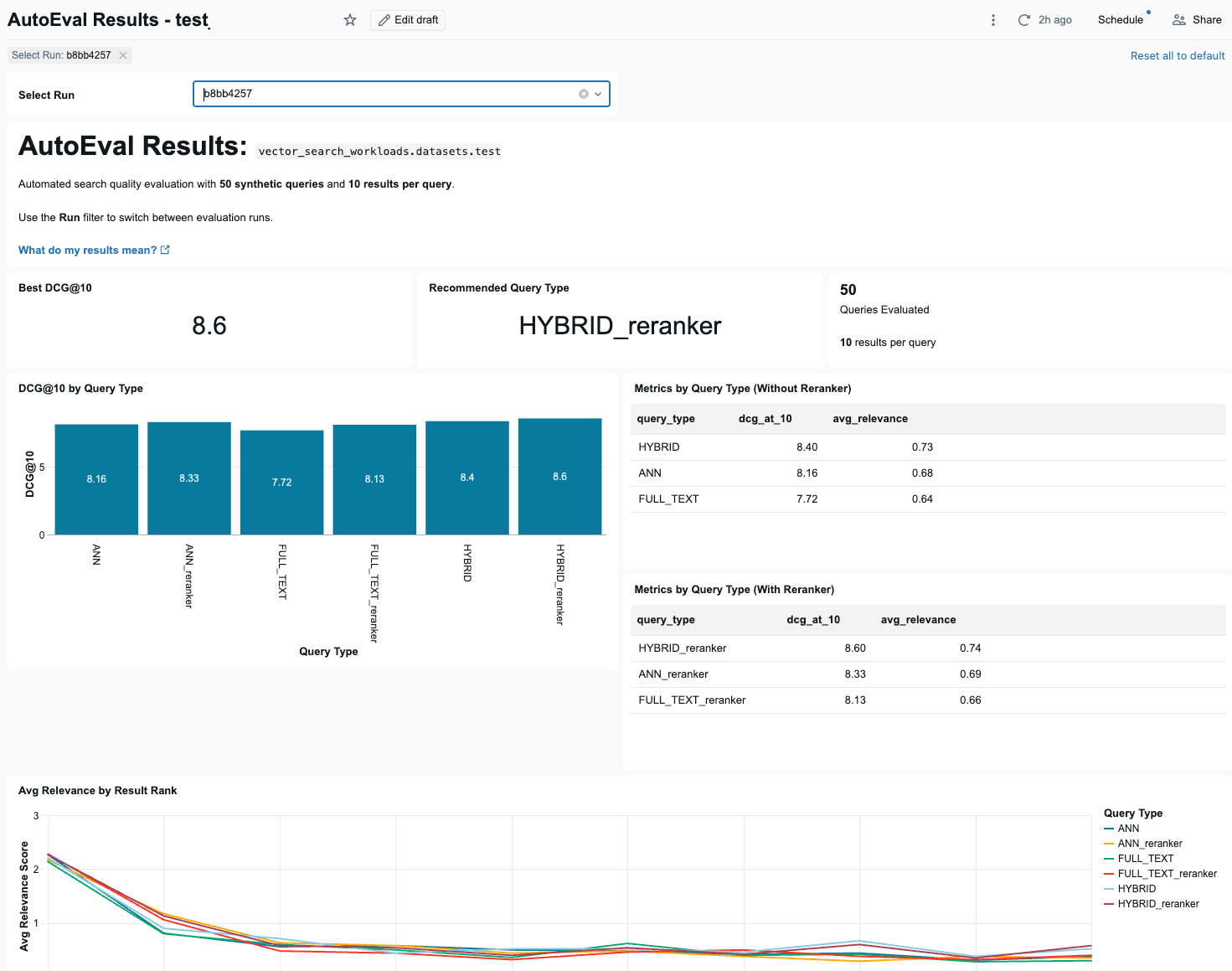
ダッシュボードの上部には、3つのサマリーインジケーターがあります。すべてのクエリータイプにおける最も優れたDCG@10スコア、それを達成した推奨されるクエリータイプ、および評価されたクエリーの数です。
「DatabricksがDCG@10を推奨する理由」を参照してください。
サマリーインジケーターの下に、ダッシュボードには各クエリタイプのDCG@10スコアを、リランカーを使用した場合と使用しない場合で比較する棒グラフが表示されます。棒グラフの隣には、DCG@10 と各クエリタイプの平均関連性 (リランカーの有無) を示す2つのテーブルがあります。
次に、クエリータイプごとに結果のポジション全体で平均関連度がどのように変化するかを、折れ線グラフが示しています。
ダッシュボードには、平均関連性スコア別に最もパフォーマンスの高いクエリーと最も低いクエリー、クエリータイプごとのベースとリランカーのパフォーマンスを比較したテーブル、失敗したクエリーのテーブル(最上位の結果のスコアが0(関連なし)だったクエリー)、およびクエリーメトリクスごとに、時間の経過とともに評価実行全体で選択したメトリクスを示す折れ線グラフも表示されます。
関連性スコアリング
検索品質の評価では、LLMジャッジを使用して、各クエリと取得されたドキュメントのペアを4段階の関連性尺度でスコアリングします。
スコア | ラベル | 説明 | 例 |
|---|---|---|---|
3 | 関連性の高い | ドキュメントがクエリーに直接回答するか、または求められる情報を正確に提供します。 | クエリー: "長方形の面積を計算する方法を教えてください?"ドキュメントでは、長さ×幅の公式について説明します。 |
2 | 関連性 | ドキュメントは関連しており、役に立つ情報を提供しますが、クエリに完全には回答できない可能性があります。 | クエリー:「小切手のルーティングナンバーはどこですか?」 ドキュメントには「小切手の下部に印刷されている」とあります(一部未完成)。 |
1 | 部分的に関連する | ドキュメントはトピックに言及していますが、クエリに関する有益な情報を提供していません。 | クエリ:「長方形の面積を計算する方法は?」 ドキュメントでは、長方形の面積について一般的な事柄のみを述べています。 |
0 | 関連性なし | ドキュメントがクエリーに関連がありません、またはドキュメントの言語がクエリー言語と一致しません。 | 英語でクエリする 文書内の回答は正しいですが、フランス語です。 |
関連あり/なしの二値スケールと比較して、段階的スケールは重要な違いを捉えます。例えば、質問に直接回答するドキュメント(スコア 3)は、単にトピックに触れているだけのドキュメント(スコア 1)とは大きく異なります。この粒度はメトリクスにまで及び、特にDCGにおいては、より質の高い結果がより重く評価されます。
すべてのメトリクスには、クエリごとの値全体でコンピュートされた95%信頼区間が含まれています。そのため、戦略間の差異が統計的に有意であるかどうかを評価できます。
取得メトリクス
ダッシュボードの下部で、選択したメトリクスを時間の経過とともにご覧いただけます。「 Select Metric 」ドロップダウンメニューから、表示するメトリクスを選択します。
このセクションでは、利用可能なメトリクスについて説明します。
DCG@k:割引累積ゲイン
DCG@10 は、関連性の高い結果がどの程度存在するか、またランキング内のどこに表示されるかの両方を、0~3 の完全な関連度スケールを使用して捉えます。Databricksは、全体的な検索品質を評価するためのプライマリ メトリクスとしてDCG@10の使用を推奨しています。
- 測定内容:順位に基づいて重み付けされた、上位10件の結果の合計ユーティリティです。上位ランクの結果は、下位ランクのものよりも、より大きく寄与します。
- 仕組み :各結果は、その位置に基づく対数割引によって重み付けされ、
2^relevance - 1の利益をもたらします。2^relevance - 1を使用すると(生の関連性スコアではなく)、関連性の高い結果が強調されます。スコア3の結果は7に貢献し、スコア1の結果は1に貢献します。最初の結果は最大の貢献をし、下位の結果は徐々に貢献度が低くなります。 - 範囲 :0~以下の表に示されている理論上の最大値です。高いほど良いです。
すべての結果が3点を獲得する場合:理論上の最大DCG値
K | 理論上の最大DCG |
|---|---|
1 | 7.00 |
3 | 14.92 |
5 | 20.64 |
10 | 31.80 |
20 | 49.28 |
これらの数値を分かりやすく説明すると、すべての10件の結果の関連性が2(0~3のスケールで)である場合、DCG@10は13.63になります。このシナリオでは、1ポイントのDCG@10の向上は、意味のある(相対的に7%の)改善です。ページ上のおよそ1つの結果が、上部に向かって重み付けされ、目立って改善されると考えることができます。
NDCG@k:正規化割引累積ゲイン
- 測定項目 :結果が最適な順序と比較してどれだけ適切に順序付けされているかを示します。NDCG は、理想的な DCG (結果が関連性の降順で並べ替えられた場合の DCG) で割ることによって、DCG を正規化します。
- 範囲: 0~1。スコアが1.0の場合、結果は完全に整然としています。
- システムが、利用可能な関連ドキュメントの総数に関係なく、結果を正しくランク付けしているかを知りたい場合に利用できます。詳細な比較については、「DCG@10が推奨される主要メトリクスである理由」を参照してください。
リコール@k
- 何を測定するか :トップ-k の結果に現れる既知の関連文書の割合。
- 範囲: 0~1。スコアが1.0の場合、既知の関連文書がすべて取得されたことを意味します。
- 利用場面 :関連ドキュメントの欠落が LLM による不完全な回答の生成につながる RAG アプリケーションのように、完全性が重要な場合です。
精度@k
- 評価指標 : 上位k件の結果のうち、関連性の高いもの(関連度スコアが2以上)の割合。
- 範囲: 0~1。スコア1.0は、上位k件のすべての結果が関連していることを意味します。
- 「利用場面」 : 結果の品質が完全性よりも重要である場合。たとえば、関連性のない結果がユーザーの信頼に悪影響を及ぼす可能性がある検索インターフェースなど。
関連度スコアの平均
- 測定内容 :すべてのクエリと結果のペア全体における、LLMジャッジによる関連性スコアの平均です。
- 範囲 :0~3。高いほど優位。
- 用途 :簡単な品質スナップショットとして使用されます。
関連度分布
-
測定内容 :各関連性カテゴリにおける結果の割合
- 関連性の高い % : スコアが 3 (直接の回答) の結果です。
- 関連性プラス% :スコアが2以上の結果(役立つ)。
- 関連性なし% :スコアが0または1の結果(有用ではありません)。
-
使用場面: 品質分布の形状を把握する際に使用します。2つの戦略は、同じ平均スコアを持つことができますが、分布は大きく異なります。例えば、二峰性分布(3が多く、0も多い)は、クエリパターンがうまく取得されておらず、対処が必要であることを示唆している場合があります。
MRR:平均逆数ランキング
- 測定内容 :ユーザーが最初の関連性の高い結果をどれだけ迅速に見つけられるか。MRRは、クエリー全体における1/rankの平均です。rankは、最初の関連結果(score >= 2)の位置です。
- 範囲: 0~1。スコアが1.0の場合、最初の結果は常に高い関連性があります。
- 使用場面:質問応答システムなど、最上位の結果が最も重要視される場合。
MAP@k:平均平均精度
- 測定内容 :最初の1つだけでなく、すべての関連する結果全体でのランキングの品質。MAP は各関連する結果の位置で精度をコンピュートし、平均を算出します。
- 範囲: 0~1。値が高いほど、関連性の高いドキュメントが常に上位にランク付けされることを示します。
- 使用場面 : すべての関連ドキュメントにおいて、全体的なランキング品質を把握できる単一の数値が必要な場合に使用します。
DCG@10 が推奨される主なメトリクスである理由
DCG@10は、ほとんどのアプリケーションにおいて、検索品質の最も完全な全体像を提供します:
- 段階的関連性はニュアンスを捉えます:精度のようなバイナリメトリクスは、すべての関連ドキュメントを同等に扱います。クエリに完全に一致するドキュメント(スコア3)は、トピックに漠然と触れているドキュメント(スコア1)と同じように扱われます。DCGは、0から3までの完全な関連度スケールを使用しているため、スコアが3の結果は、スコアが1の結果よりもはるかに大きく貢献します。
- 位置は重要です :ユーザーは最初に上位の結果を見ます。DCG は対数割引を適用するため、1番目の結果は10番目の結果よりもはるかに重みがあります。最初の結果は完全な関連性スコアに寄与し、10番目の結果の貢献度は(log₂(11) ≈ 3.46)で割られます。
- 絶対的なユーティリティが、正規化されたメトリクスでは見落とされがちな点を明らかにします:次の表に示す例を考慮してください。両方の結果セットは、それぞれが理想的な降順で結果を有しているため、NDCG 1.00という完璧な値を達成しています。ただし、結果セットBは、すべての結果が有用であるため、ほぼ2倍の総価値(DCG 8.02対4.26)をもたらします。NDCGは、「関連性のない3つの結果を含む中で、2つの良い結果が完璧に順位付けされたランキング」と「5つの良い結果が完璧に順位付けされたランキング」を区別できません。DCGは質問に答えます:「ユーザーは実際にどれほどの役立つ情報を得られましたか?」
DCGとNDCGの詳細については、「Discounted cumulative gain」を参照してください。
結果 | 1番目の位置 | 位置2番目 | 位置 3 | 位置4 | 位置5 | NDCG@5 | DCG@5 |
|---|---|---|---|---|---|---|---|
結果セットA | 3 | 2 | 0 | 0 | 0 | 1.00 | 4.26 |
結果一式 B | 3 | 3 | 3 | 2 | 2 | 1.00 | 8.02 |
単一のメトリクスだけでは、全てを物語ることはできません。全体像を把握するために、すべてのメトリクススイートを利用し、アプリケーションの品質要件に最も合致するメトリクスを選択してください。
一般的なシナリオ
次の表に、一般的な評価結果のパターン、その意味、および対処方法を示します:
パターン | 意味 | 推奨アクション |
|---|---|---|
ハイブリッドはANNよりも大幅に優れています。 | クエリはキーワードマッチングによって効果が高まります。 | 本番運用でハイブリッド検索を使用します。 |
ANNはハイブリッドとほぼ等しいです。 | キーワードはデータに価値を付加していません。 | どちらの戦略も機能します。ANNはよりシンプルです。 |
全文はANNより大幅に優れています。 | 埋め込みは、お使いのドメインを適切に表現できない可能性があります。 | 埋め込みモデルのファインチューニング、または全文検索の利用をご検討ください。 |
リランカーにより、メトリクスが大幅に改善されます。 | クロスエンコーダーは有意な品質向上をもたらします。 | レイテンシーの許容範囲内であれば、再ランク付けを有効にしてください。 |
広い信頼間隔 | 信頼できる比較には、十分なクエリがありません。 | 評価クエリーの数を増やしてください。 |
すべての戦略のスコアは低いです | データ品質または関連性の問題。 | 検索品質を改善するためのステップバイステップガイドについては、AI Search検索品質ガイドをご覧ください。 |