メトリクス ビューのマテリアライゼーション
メトリクスビューのマテリアライゼーションは、マテリアライズドビューを使用して集計を事前計算することで、クエリを高速化します。Lakeflow pipelines は、特定のメトリクスビューのユーザー定義のマテリアライズドビューをオーケストレーションします。クエリー実行時、クエリー最適化機能は、自動集計対応クエリーマッチング (クエリー書き換え) を使用して、最適なマテリアライズドビューへクエリーをルーティングします。メトリックビューは、追加の手動作業なしで、通常どおりクエリーを実行できます。Databricks は、マテリアライゼーションを最新の状態に保つために更新します。また、より高速なクエリーを低コストで実行するために、どのマテリアライゼーションをクエリーするかも選択します。
マテリアライズの仕組み
メトリクス ビューのマテリアライゼーションには、マテリアライゼーションの定義と、それに対するクエリーの実行という2つのフェーズがあります。
定義フェーズ
マテリアライゼーションを使用してメトリクスビューを定義する場合、メトリクスビューYAMLでフィールド、メジャー、および更新スケジュールを指定します。その定義から、Databricksはマテリアライズドビューを構築および維持する、管理されたLakeFlow Pipelinesを作成します。
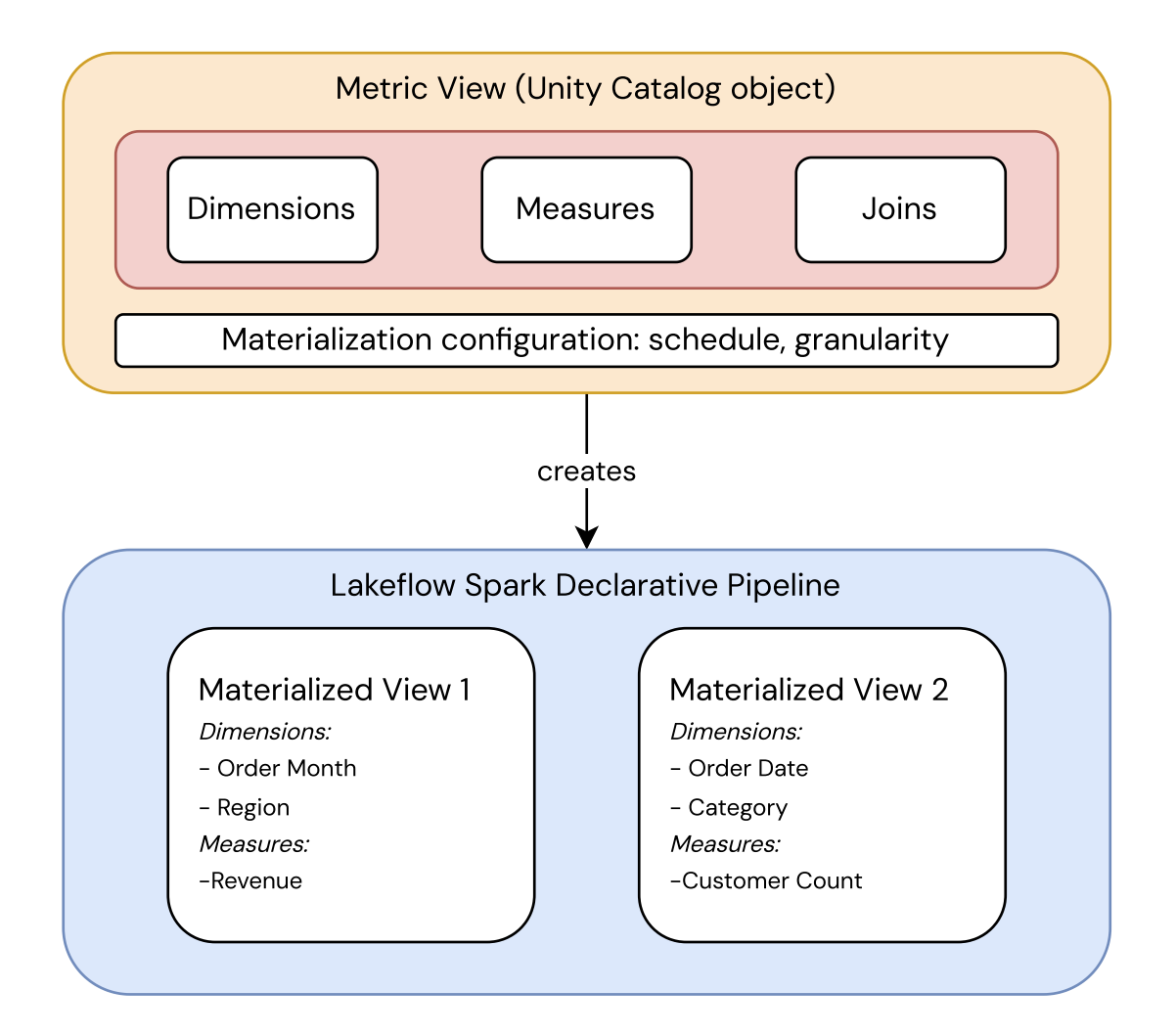
これにより、メトリクス定義は保存方法とは別に保たれます。
- メトリクスビュー は、Unity Catalogのオブジェクトであり、メトリクスのフィールド、メジャー、結合、およびマテリアライズの設定 (スケジュールと粒度) を定義します。メトリクスが何を意味するかの信頼できる唯一のソースです。
- パイプライン は、その定義を、それぞれ特定の粒度で事前計算される1つ以上のマテリアライズドビューとして実体化します。Databricksはクエリ実行時にどちらを読み込むかを選択します。
クエリーの実行
SELECT ... FROM <metric_view>をランすると、クエリー最適化機能は集計対応クエリー書き換えを使用してパフォーマンスを最適化します:
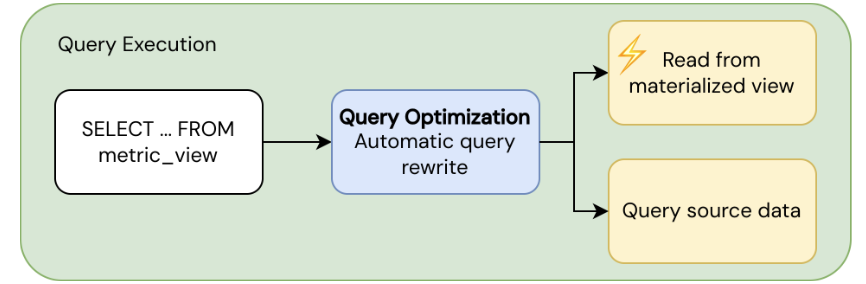
- 高速パス :適切なマテリアライゼーションが存在する場合、事前計算されたマテリアライズドビューから読み取ります。
- Fallback path : 適切なマテリアライズドビューがない場合、ソースデータから直接読み取ります。
クエリー最適化機能は、マテリアライズドデータとソースデータのどちらかを選択することで、パフォーマンスと鮮度のバランスを自動的に取ります。オプティマイザがどのパスを使用するかに関係なく、結果は透過的に受け取られます。メトリクスビューに対するクエリーの実行の詳細については、「メトリクスビューのクエリー」を参照してください。
要件
メトリクス ビューでマテリアライゼーションを使用するには:
- ワークスペースでServerless コンピュートが有効になっている必要があります。This is required to run Lakeflow pipelines.
- Databricks Runtime 17.3 以降を実行するSQL Warehouseまたはコンピュートリソース。
マテリアライズには、Databricks Runtime 17.3 以上が必要です。マテリアライズなしでメトリクスビューを作成することは、Databricks Runtime 16.4 以上でサポートされています。各機能の最小ランタイムについては、メトリクス ビューの機能可用性をご覧ください。
構成リファレンス
メトリクスビュー YAML 定義のトップレベル materialization フィールドで、マテリアライゼーションを構成します。このフィールドは、クエリー書き換え mode(常に relaxed)、オプションの更新 schedule、および維持する materialized_views のリストを設定します。各マテリアライズドビューは、特定のディメンションとメジャーを事前計算する aggregated であるか、完全なデータモデルを実体化する unaggregated のいずれかです。
必須フィールドとオプションフィールド、許可される値、およびschedule句の制限を含む、完全なフィールドごとの仕様については、Materializationを参照してください。
定義例
次の例では、1つの未集計と2つの集計されたマテリアライゼーションを持つメトリクスビューを定義します。
version: 1.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
fields:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
cluster_by:
cols:
- category
- color
partition_by:
- category
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
トップレベルの定義がfields:を使用している場合でも、materializationブロックはdimensions:キーワードを使用してマテリアライズするフィールドをリストします。2つのキーワードは同等です。「フィールド」を参照してください。
revenue_breakdownマテリアライゼーションは、マテリアライズドビューのCLUSTER BYおよびPARTITION BY句と同じ方法で、cluster_byとpartition_byを使用してマテリアライズドデータの物理的なレイアウトを制御します。完全なフィールド仕様については、「マテリアライゼーション」を参照してください。
SQL を使用してメトリクスビューを作成します
Catalog Explorer の外部でこのメトリクスビューを作成するには、YAMLをCREATE OR REPLACE VIEW ... WITH METRICS LANGUAGE YAML ASで囲み、定義を$$デリミターの間に配置します。
CREATE OR REPLACE VIEW catalog.schema.orders_materialized WITH METRICS LANGUAGE YAML AS
$$
version: 1.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
$$
クエリー書き換えモード
relaxedモードでは、自動クエリー書き換えは、候補となるマテリアライズドビューがクエリーに対応するために必要なフィールドとメジャーを持っているかどうかのみを検証します。
以下のチェックはスキップされています:
- 鮮度 :マテリアライゼーションが最新であることを検証しません。
- SQL設定 :
TIMEZONEやANSI_MODEなどの設定が一致していることは検証されません。 - 決定性 :マテリアライズの結果が完全に決定的であることを検証しません。
マテリアライゼーションに一致するクエリーは、最後の更新を使用します。一致しないクエリーはソースにフォールバックし、ライブデータを返します。結果として、データの鮮度は、クエリーが書き換えの対象となるかどうかに応じて異なります。一貫性を確認するには、マテリアライゼーションの更新スケジュールをソースパイプラインと合わせてください。たとえば、ソースがバッチパイプラインで毎日更新される場合、マテリアライゼーションの更新は、そのパイプラインの完了後に実行されるようにスケジュールしてください。あるいは、集計されていないマテリアライゼーションを使用して、すべてのクエリーが同じスナップショットから読み取られることを保証してください。
メトリクスビューまたはそのいずれかのソーステーブルが以下を使用している場合、マテリアライゼーションを作成することはできません。
- 行レベルセキュリティ(RLS)、列レベルマスキング(CLM)、またはABACポリシー。事前計算された結果は、クエリー実行時に適用されるべきユーザーごとのアクセス制御を回避する可能性があります。
- クエリーを実行するユーザーによって結果が変わる、インボーカーに依存する式(例えば、
current_user()またはis_member())。マテリアライゼーションは一度事前計算されて共有されるため、別のユーザーに提供すると不正または安全でない結果が返されます。
Databricksは、マテリアライゼーションを作成、変更、または更新するときにこの制限を検証します。これらの操作は、エラー条件METRIC_VIEW_MATERIALIZATION_WITH_INVOKER_DEPENDENT_EXPRESSIONS_NOT_SUPPORTED(SQLSTATE 42K0E)で失敗します。「METRIC_VIEW_MATERIALIZATION_WITH_INVOKER_DEPENDENT_EXPRESSIONS_NOT_SUPPORTED」を参照してください。
メトリクスビューのマテリアライゼーションのタイプ
以下のセクションでは、メトリクスビューで利用可能なマテリアライズドビューの種類について説明し、データソースとクエリーパターンに合わせた適切な構成を選択するためのガイダンスを提供します。
集約型
このタイプは、対象とするカバレッジに対応するため、指定されたメジャーとフィールドの組み合わせについて集計を事前計算します。
特定のディメンションとメジャーの組み合わせが頻繁にクエリーされる場合は、集約型を使用します。集約されたマテリアライゼーションでは、完全一致とロールアップ一致の両方の戦略が適用され、これらのパターンに最適なクエリーパフォーマンスを提供します。
最適な集計のため :
-
最も一般的に使用されるディメンションを
GROUP BY句に含めます。 -
潜在的なフィルター列 (
WHEREでクエリー時に使用される列) を含めます。 -
クエリが必要とする最も詳細なレベルでマテリアライズします。たとえば、
(region, sku, event_day)でのマテリアライゼーションは、以下のすべてを提供できます。GROUP BY regionGROUP BY region, event_monthGROUP BY skuとWHERE region = 'US'
-
ほとんど単一行のグループ(たとえば、ミリ秒単位の精度を持つ生のTimestamp)を生成するほど粒度の細かいディメンションは避けてください。これには利点がなく、ストレージを肥大化させます。
-
非加法メジャーに注意してください。非加法メジャーは、部分的な結果から再集計することはできません(たとえば、
COUNT(DISTINCT)、MEDIAN、パーセンタイルなど)、およびマテリアライゼーションとの完全一致が必要です。
単一の集計処理は、その特定のディメンション(完全一致)に一致するクエリー、またはそのディメンションのサブセット(ロールアップ一致)にのみ対応できます。Databricks では、異なるクエリパターンに対して複数の集計マテリアライズドビューを作成することをお勧めします。
未集計タイプ
このタイプは、集約型と比較して、パフォーマンスへの影響を軽減しつつ、より広範なカバレッジを実現するために、非集約データモデル全体(source、joins、filter、およびfieldsの各フィールド)をマテリアライズします。
以下のいずれかに該当する場合は、非集計タイプを使用します:
- メトリクスビューには、コストのかかるソース変換や結合が含まれています。
- クエリーパターンは予測不能または多様です。
- メトリクスビューをクエリするすべてのユーザーは、データ内で一貫性を確認できる必要があります。
未集計のマテリアライゼーションを使用すると、コストの高いソースビューと結合は、すべてのクエリーごとではなく、更新時に1回コンピュートされます。集計されたマテリアライゼーションと未集計のマテリアライゼーションの両方が存在する場合、Databricksは、未集計のマテリアライゼーションから集計されたマテリアライゼーションをコンピュートします。これにより、一貫性のあるスナップショットが提供され、ソースの冗長な再計算が回避されます。未集計の一致は、クエリー書き換えモードに記載されている制限に従い、クエリーの形状に関係なく常に適格です。
選択的なフィルターなしでソースが直接のテーブル参照である場合、集計されていないマテリアライゼーションは役に立ちません。その場合、ソースを直接クエリーすることと比べて利点はありません。
これらのマテリアライゼーション タイプをいつ、どのように使用するかについての追加ガイダンスについては、メトリクス ビューのマテリアライゼーション タイプを選択するを参照してください。
自動クエリー書き換え
メトリクスビューをクエリーすると、クエリーの書き換えにより、利用可能な最適なマテリアライゼーションにクエリーが自動的にルーティングされます。これは、完全一致、ロールアップマッチ、未集計マッチの3つのクエリー書き換え戦略を使用します。
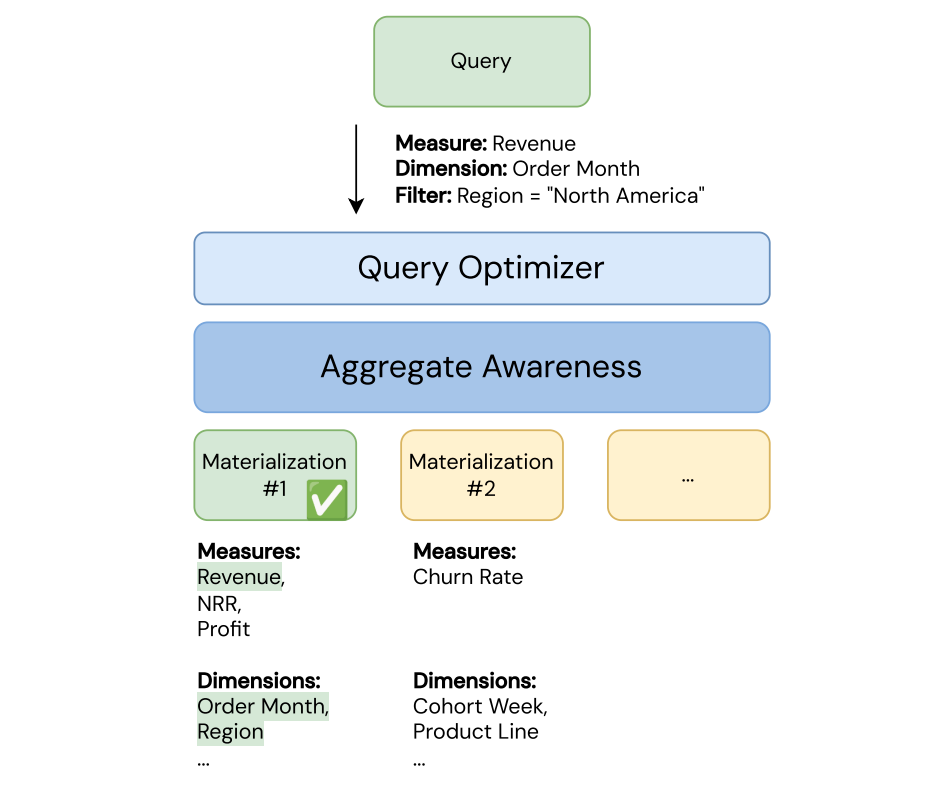
このアルゴリズムを使用すると、クエリーはベーステーブルの代わりに最適なマテリアライズで自動的に実行されます。
- まず、クエリーオプティマイザーは完全一致を試行します。
- 完全一致がない場合、クエリー最適化機能はロールアップ一致を試みます。
- ロールアップ一致がなく、集計されていないマテリアライゼーションが存在する場合、クエリー オプティマイザーは集計されていない一致を試みます。
- 集計されていない一致がない場合、クエリーはソース テーブルから直接読み取ります。
以下のセクションでは、各戦略のしくみについて説明します。
マテリアライゼーションは、クエリー書き換えが有効になる前にマテリアライズを完了する必要があります。
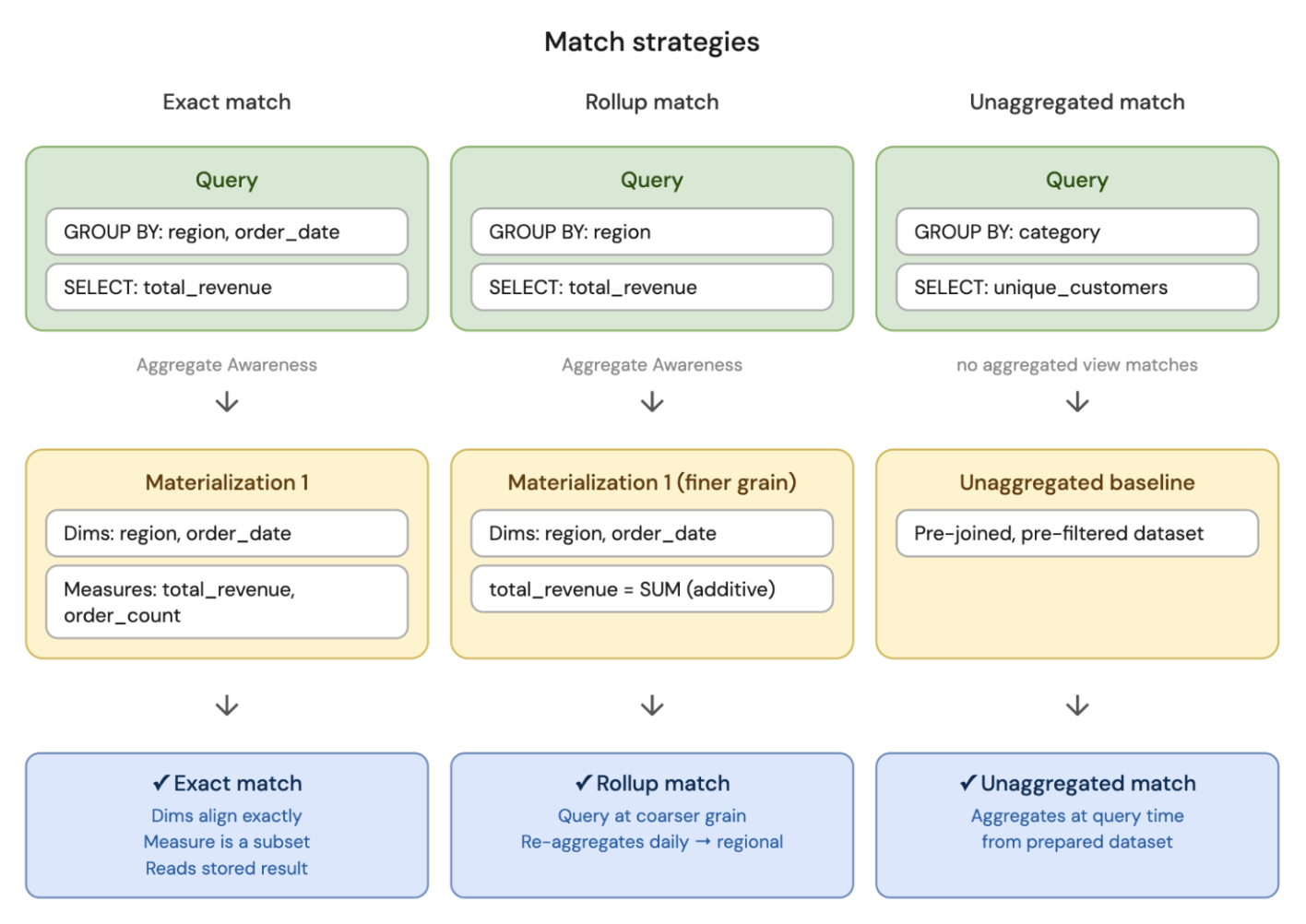
完全一致
クエリーは、実体化において事前に計算されたものを正確に要求します。クエリーの書き換えは、余分な作業なしに保存された結果を読み取り、高速な結果を可能にします。
完全一致の条件:
- クエリーの
GROUP BY式は、マテリアライゼーションのディメンションと正確に一致する必要があります。 - クエリーのメジャーは、マテリアライズされたメジャーのサブセットである必要があります。
たとえば、マテリアライゼーションにはディメンション [region, order_date] とメジャー [total_revenue, order_count] があります。region と order_date でグループ化され、total_revenue を要求するクエリーは、ディメンションが同じでメジャーが事前計算されているため、正確に一致します。
ロールアップ照合
クエリーは、事前に計算されたレベルよりも粗いレベルでのサマリーを要求しています。オプティマイザーは、事前に計算された結果を読み取り、クエリーが必要とするレベルに再集計します。
ロールアップマッチの対象となるには:
- 粗い粒度 : クエリーは、マテリアライゼーションよりも少ないディメンション、またはより広い時間粒度でグループ化されます。
- すべてのメジャーは加算可能です :クエリで要求される各メジャーは、部分的な結果を組み合わせて正しく再計算できるものでなければなりません(たとえば、
SUMのSUM、またはMAXのMAX)。MEDIANはグループディストリビューションに依存しているため、集約できません。 - 関与するフィルターは決定論的な式である必要があります :クエリーに
WHERE句がある場合、フィルターは常に同じ入力に対して同じ結果を生成する必要があります。たとえば、WHERE region = 'US'は決定論的ですが、rand()やuuid()などの式は決定論的ではありません。
非加算メジャーは、部分的な結果から正しく再集計できないため、ロールアップマッチの対象にはなりません。「加算メジャー」を参照してください。
例えば、ディメンション [region, order_date] とメジャー [total_revenue, order_count] を持つ同じマテリアライズドビューを使用する場合、region でのみグループ化され、total_revenue を要求するクエリーはロールアップの一致となります。クエリーはマテリアライズされたものよりも少ないディメンションしか必要としないため、エンジンは日次合計を地域レベルの合計に集約します。
加算メジャー
メジャーは、既存の集計済みマテリアライゼーションから再集計することによってその集計結果を正しく再計算できる場合に 加法性 を持ちます。これはロールアップのマッチングにおける主要な要件です。
DISTINCT を使用する集計 (たとえば、COUNT(DISTINCT)、SUM(DISTINCT)) は非加算であり、ロールアップできません。
以下の関数は加算可能です:
SUMCOUNTMINMAXBIT_ANDBIT_ORBIT_XORBOOL_ANDBOOL_OR
加法メジャーには追加の制限が適用されます。
- メジャーの定義には、集計関数をちょうど1つ含める必要があります。複数の集計(例:
sum(cost) + min(revenue))を組み合わせた定義を持つメジャーは、ロールアップマッチングの対象ではありません。 - メジャー定義に
FILTER句が含まれる場合、それは決定論的でなければなりません。 - このメジャーはウィンドウメジャー(たとえば、ローリング7日間の合計や、ウィンドウブロックで定義された前年比の比較)にはできません。
次の表は、一般的なメジャーパターンがマッチタイプにどのようにマップされるかをまとめたものです。
パターンを測定します。 | タイプの一致 | 理由: |
|---|---|---|
単一の加算集計( | ロールアップ対象 | 部分的な結果から再集計できます |
| 完全一致のみ | 再集計できません。 |
1つの式における複数の集計( | 完全一致のみ | ロールアップでは個別の集計を分離できません。 |
確定的加算集計 | ロールアップ対象 | フィルターは決定的で、集計は加法的です。 |
ウィンドウメジャー | 完全一致のみ | ウィンドウフレームは正確な粒度によって異なります。 |
未集計のマッチ
クエリーは事前計算された集計と一致しませんが、負荷の高い準備作業 (結合とフィルター) はすでに完了しています。クエリーの書き換えは、ソーステーブルに戻ることなく、非集計のマテリアライゼーションの準備されたデータセットから開始されます。
未集計のマテリアライゼーションが存在する場合、この戦略はソースに移行する前に常にfallbackとして適格です。クエリー書き換えモードで説明されている制限に従い、任意のクエリー形状でこれを使用できます。
たとえば、クエリーはcategoryでグループ化され、unique_customersを要求しますが、集約された実体化にはそれらのフィールドとメジャーは含まれていません。ただし、集約されていない実体化が存在し、結合され、フィルタリングされたデータセットが準備されています。クエリーオプティマイザーは、準備されたデータセットから読み取り、生のテーブルを最初から再結合するのではなく、クエリー時にGROUP BY category, COUNT(DISTINCT customer_id)を実行します。
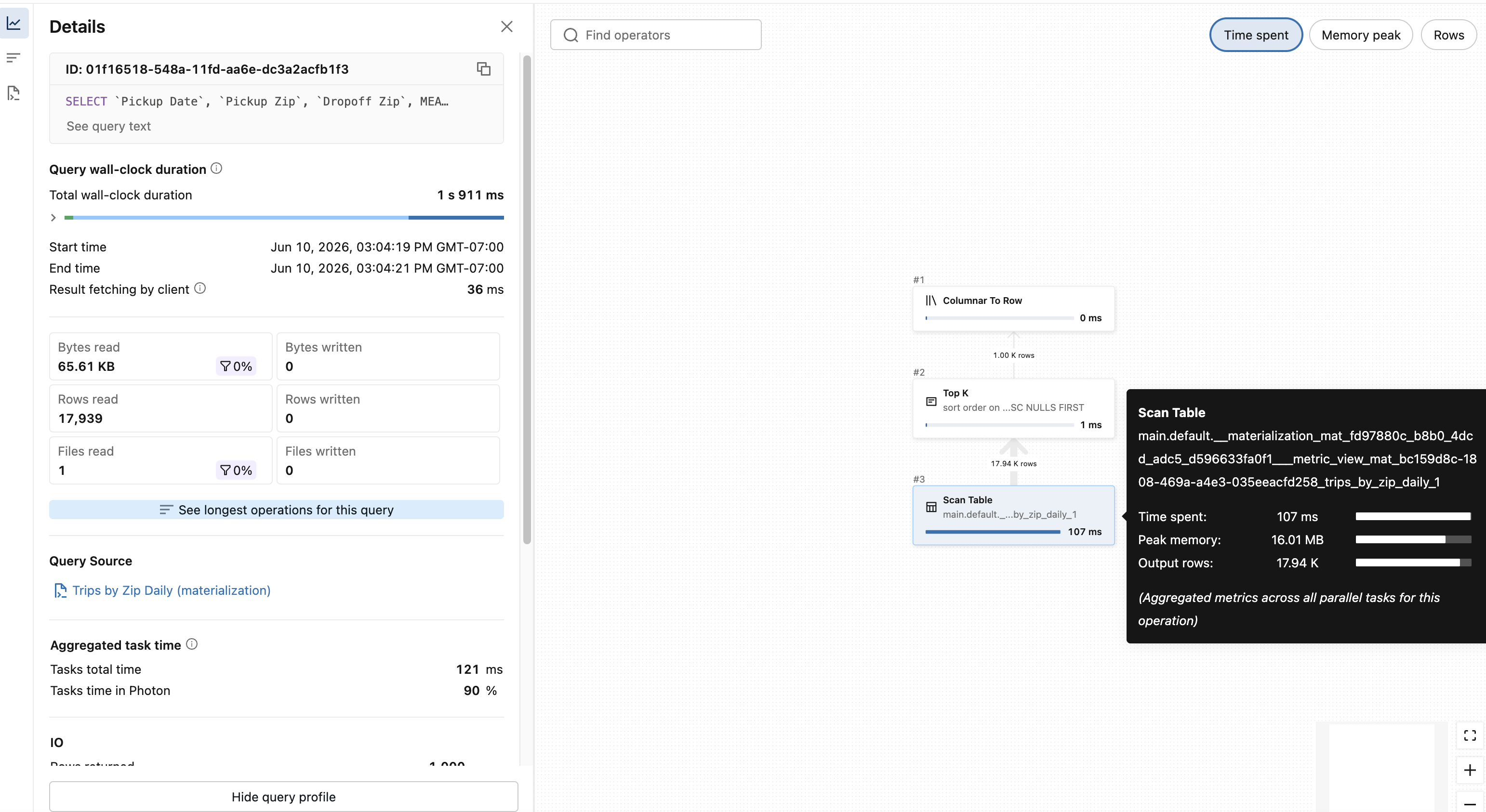
クエリがマテリアライズドビューを使用していることを確認する
クエリーがマテリアライズドビューを使用しているかを確認するには、2つの方法があります。
- クエリープランを表示するには、クエリーで
EXPLAIN EXTENDEDを実行します。マテリアライゼーションが使用された場合、リーフノードには__materialization_mat_<pipeline ID>___metric_view_mat_とYAMLファイルからのマテリアライゼーション名が含まれます。 - 以下に示すように、クエリープロファイルを確認してください。
マテリアライゼーションのライフサイクル
このセクションでは、マテリアライゼーションがそのライフサイクル全体でどのように作成、管理、更新されるかについて説明します。
作成と変更
メトリクスビューを作成または変更すると(CREATE、ALTER、またはカタログエクスプローラを使用して)、メトリクスビューの定義は直ちに更新されます。マテリアライズドビューは、マネージドパイプラインを使用してバックグラウンドで非同期に更新されます。
カタログエクスプローラーエディターで新しいマテリアライゼーションを定義するには:
- マテリアリゼーション をクリックします。
- スケジュール をクリックしてスケジュールを設定します。間隔期間を選択するか、特定の時間にマテリアライゼーションを実行するように設定できます。
- タイプ を選択します。メトリクスビューごとに許可されている非集計のマテリアライゼーションは1つのみです。詳細については、メトリクスビューのマテリアライゼーションのタイプを参照してください。
- フィールド ドロップダウンを使用して、マテリアライゼーションに含めるフィールドを選択します。
- 含めるメジャーを選択するには、**メジャー**ドロップダウンを使用します。
メトリクスビューを作成すると、Databricks は LakeFlow Pipelines を作成し、マテリアライズドビューが指定されている場合はすぐに初期更新をスケジュールします。メトリクスビューは、ソースデータからのクエリにフォールバックすることで、マテリアライゼーションなしでクエリ可能です。
メトリクスビューを変更しても、Databricks は新しい更新をスケジュールしません。ただし、初めて具体化を有効にする場合は除きます。マテリアライズドビューは、次のスケジュールされた更新が完了するまで、自動的なクエリーの書き換えには使用されません。
マテリアライズのスケジュールを変更しても、更新はトリガーされません。
スケジュールがない場合、パイプラインは作成時に最初の更新を実行しますが、その後の更新は手動でTriggerする必要があります。そうしないとデータが古くなります。Databricksは、テストまたはプロトタイプ作成を行っていない限り、データを最新の状態に保つために、スケジュールを常に定義することをお勧めします。
更新動作のより詳細な制御については、手動更新を参照してください。
基盤となるパイプラインを検査する
メトリクスビューのマテリアライズは、Lakeflow pipelines を使用して実装されています。パイプラインには、次の2つの方法でアクセスできます。
- カタログエクスプローラ内 :メトリクスビューの 概要 タブには、 更新スケジュール の見出しの下に直接リンクが含まれています。カタログ エクスプローラーへのアクセス方法については、カタログ エクスプローラーとはを参照してください。
- SQLを使用 :
DESCRIBE EXTENDEDを実行します。「 更新情報 」セクションには、パイプラインリンクと現在の更新ステータスが含まれています。
DESCRIBE EXTENDED my_metric_view;
出力例:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE EXTENDED my_metric_view;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh Information
Latest Refresh Status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 6 HOURS
手動更新
From the Link to the Lakeflow パイプライン page, you can manually 起動 a パイプライン update to update the materializations.次の SQL コマンドを使用して、手動更新を Trigger することもできます。
REFRESH MATERIALIZED VIEW <metric-view-name>
増分更新
マテリアライズドビューは、可能な限り増分更新を使用し、データソースおよび計画構造に関して標準のマテリアライズドビューと同じ制限があります。
前提条件と制限の詳細については、 「マテリアライズドビューの増分更新」を参照してください。
課金
マテリアライズドビューの更新には、Lakeflow Pipelinesの使用料が発生します。パイプラインのDBU消費量を調べるには、ServerlessパイプラインのDBU消費量とは何ですか?をご覧ください。
既知の制限事項
メトリクス ビューのマテリアライゼーションには次の制限が適用されます。
- パラメーターを定義するメトリクスビューをマテリアライズすることはできません。
- メトリクス ビューのマテリアライゼーションが作成された後は、所有者を変更できません。
- Databricksは、実体化されたメトリクスビューのグループ所有権をサポートしていません。
- 一対多結合を持つメトリクスビューには、厳密な一致戦略のみが適用可能です。
scheduleのマテリアライゼーションは、TRIGGER ON UPDATE句をサポートしていません。