コンピュート 構成 リファレンス
この記事の構成は、単純な形式のコンピュート UI を使用していることを前提としています。 簡易フォームの更新の概要については、「 簡易フォームを使用してコンピュートを管理する」を参照してください。
この記事では、新しい 汎用 リソースまたはジョブ コンピュート リソースを作成するときに使用できる構成設定について説明します。 ほとんどのユーザーは、割り当てられたポリシーを使用してコンピュート リソースを作成するため、構成可能な設定が制限されます。 UI に特定の設定が表示されない場合は、選択したポリシーでその設定を構成できないためです。
ワークロードのコンピュート構成に関する推奨事項については、「クラシック コンピュート構成のベストプラクティス」を参照してください。
この記事で説明する構成と管理ツールは、汎用 とジョブ コンピュートの両方に適用されます。 ジョブ コンピュートの構成に関する考慮事項の詳細については、「 ジョブのコンピュートを構成する」を参照してください。
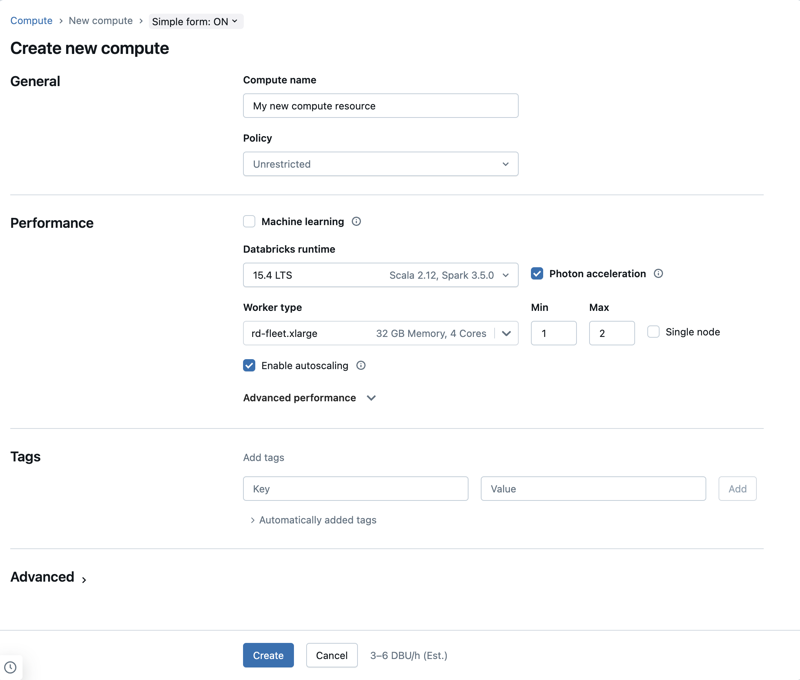
新しい汎用コンピュート リソースを作成する
新しい汎用コンピュートリソースを作成するには、次の手順を実行します。
- ワークスペースのサイドバーで、 [コンピュート] をクリックします。
- [コンピュートを作成] ボタンをクリックします。
- コンピュートリソースを構成します。
- 作成 をクリックします。
新しいコンピュートリソースは自動的にスピンアップを開始し、すぐに使用できるようになります。
コンピュート ポリシー
ポリシーは、ユーザーがコンピュート リソースを作成するときに使用できる構成オプションを制限するために使用される一連のルールです。 ユーザーが Unrestricted クラスター作成 資格を持っていない場合、付与されたポリシーを使用してのみコンピュート リソースを作成できます。
ポリシーに従ってコンピュートリソースを作成するには、[ ポリシー ] ドロップダウンメニューから目的のポリシーを選択します。
デフォルトでは、すべてのユーザーが パーソナルコンピュート ポリシーにアクセスでき、単一マシンのコンピュートリソースを作成できます。パーソナルコンピュートまたはその他のポリシーへのアクセスが必要な場合は、ワークスペース管理者にお問い合わせください。
パフォーマンス設定
次の設定は、シンプルフォームのコンピュートUIの パフォーマンス セクションに表示されます。
Databricks Runtime のバージョン
Databricks Runtime は、コンピュートで実行されるコアコンポーネントのセットです。 Databricks Runtimeバージョン ドロップダウンメニューを使用してランタイムを選択します。特定の Databricks Runtime バージョンの詳細については、 Databricks Runtime リリースノートのバージョンと互換性をご覧ください。 すべてのバージョンに Apache Spark が含まれています。 Databricks では、次のことを推奨しています。
- 汎用コンピュートの場合は、コードとプリロードされたパッケージ間の最新の互換性を確保するために、最新の最適化と、最新バージョンを使用してください。
- 運用ワークロードを実行しているジョブ コンピュートの場合は、Long Term Support (LTS) Databricks Runtime バージョンの使用を検討してください。 LTSバージョンを使用すると、互換性の問題に遭遇することがなくなり、アップグレード前にワークロードを徹底的にテストできます。
- データサイエンスと機械学習のユースケースでは、Databricks Runtime MLバージョンを検討してください。
Photonアクセラレーションを使用する
Databricks Runtime 9.1 LTS以降を実行しているコンピュートでは、Photonはデフォルトで有効になっています。
Photon アクセラレーションを有効または無効にするには、 Photonのアクセラレーション チェックボックスを選択します。 Photonの詳細については、 Photonとはを参照してください。
ワーカーノードタイプ
コンピュート リソースは、1 つのドライバー ノードと 0 個以上のワーカー ノードで構成されます。 ドライバーノードとワーカーノードに別々のクラウドプロバイダーインスタンスタイプを選択できますが、デフォルトでは、ドライバーノードはワーカーノードと同じインスタンスタイプを使用します。 ドライバー ノードの設定は、[ 高度なパフォーマンス ] セクションの下にあります。
インスタンスタイプのファミリーが異なれば、メモリ集約型またはコンピュート集約型のワークロードなど、さまざまなユースケースに適合します。 ワーカーノードまたはドライバーノードとして使用するプールを選択することもできます。
ドライバータイプとしてスポットインスタンスを含むプールは使用しないでください。 オンデマンド ドライバーの種類を選択して、ドライバーが再利用されないようにします。 「プールへの接続」を参照してください。
マルチノードのコンピュートでは、コンピュートリソースが正しく機能するために必要な Spark エグゼキューターやその他のサービスをワーカーノードは実行します。Spark を使用してワークロードを分散すると、すべての分散処理がワーカーノードで行われます。Databricks では、ワーカーノードごとに 1 つのエグゼキューターを実行します。そのため、エグゼキューターとワーカーという用語は、Databricks アーキテクチャのコンテキストでは同じ意味で使用されます。
Spark ジョブを実行するには、少なくとも 1 つのワーカーノードが必要です。コンピュートリソースのワーカーがゼロの場合、ドライバーノードで Spark 以外のコマンドは実行できますが、Spark コマンドは失敗します。
柔軟なノードタイプ
ワークスペースでフレキシブル ノード タイプが有効になっている場合は、コンピュート リソースにフレキシブル ノード タイプを使用できます。 柔軟なノード タイプを使用すると、指定したインスタンス タイプが使用できない場合に、コンピュート リソースを代替の互換性のあるインスタンス タイプにフォールバックできます。 この動作により、コンピュート起動中の容量障害が減少し、コンピュート起動の信頼性が向上します。 「柔軟なノード タイプを使用したコンピュート起動の信頼性の向上」を参照してください。
ワーカー ノードの IP アドレス
Databricks は、それぞれ 2 つのプライベート IP アドレスを持つワーカー ノードを起動します。ノードのプライマリ プライベート IP アドレスは、Databricks 内部トラフィックをホストします。セカンダリ プライベート IP アドレスは、 Spark コンテナーによってクラスター内通信に使用されます。 このモデルにより、 Databricks は同じワークスペース内の複数のコンピュート リソース間で分離を提供できます。
GPU インスタンスタイプ
ディープラーニングに関連するタスクのように、高いパフォーマンスが求められる計算難易度の高いタスクの場合、 Databricks はグラフィックス プロセッシング ユニット (GPU) で高速化されるコンピュート リソースをサポートしています。 詳細については、「 GPU 対応コンピュート」を参照してください。
Databricksは、Amazon EC2 P2インスタンスを使用したコンピュートのスピンアップをサポートしなくなりました。
AWS Graviton インスタンスタイプ
Databricks は AWS Gravitonのインスタンスをサポートしています。AWS Graviton インスタンスは、Arm64 命令セットアーキテクチャに基づいて構築された AWS 設計の Graviton プロセッサを使用しています。AWS によると、これらのプロセッサを搭載したインスタンスタイプは、Amazon EC2 のどのインスタンスタイプのなかで最も優れた価格性能比を提供します。Graviton インスタンスタイプを使用するには、 ワーカータイプ 、 ドライバータイプ 、またはその両方で使用可能な AWS Graviton インスタンスタイプのいずれかを選択します。
Databricksは、以下のAWS Graviton対応のコンピュートをサポートします:
- Photon以外の場合はDatabricks Runtime 9.1 LTS以降、Photonの場合はDatabricks Runtime 10.2以降が必要です。
- Databricks Runtime 15.4 LTS for Machine Learning以降に対応しています。
- すべてのAWSリージョン。ただし、すべてのインスタンスタイプがすべてのリージョンで利用できるわけではないことに注意してください。リージョンでは利用できないインスタンスタイプをワークスペースに選択すると、コンピュート作成が失敗します。
- AWS Graviton2およびGraviton3プロセッサ対応。
ARM64 ISA の制限事項
- 浮動小数点の精度の変更:加算、減算、乗算、除算などの一般的な演算では精度は変更されません。
sinやcosなどの単一の三角形関数の場合、Intelインスタンスとの精度の差の上限は1.11e-16です。 - サードパーティのサポート:ISAの変更は、サードパーティのツールやライブラリのサポートに何らかの影響を与える可能性があります。
- 混合インスタンスコンピュート:Databricksでは、AWS Gravitonインスタンスタイプと非AWS Gravitonインスタンスタイプの混在はサポートされていません。各タイプには異なるDatabricks Runtimeが必要であるためです。
Gravitonの制限
次の機能はAWS Gravitonインスタンスタイプをサポートしていません。
- Python UDF(Python UDFはDatabricks Runtime 15.2以降で使用できます)
- Databricks Container Services
- Databricks SQL
- AWS GovCloud上のDatabricks
- WebターミナルからGitフォルダ内のファイルを含むワークスペースファイルへのアクセス
AWS Fleet インスタンスタイプ
ワークスペースが 2023 年 5 月より前に作成された場合、フリートインスタンスタイプへのアクセスを許可するには、その IAMロールのアクセス許可を更新する必要がある場合があります。 詳細については、「 フリートインスタンスタイプを有効にする」を参照してください。
フリートインスタンスタイプは、同じサイズの利用可能な最適なインスタンスタイプに自動的に解決される可変インスタンスタイプです。
たとえば、フリートインスタンスタイプ m-fleet.xlarge を選択した場合、ノードは、その時点でスポット容量と価格が最も優れた汎用インスタンスタイプの .xlarge に割り当てられます。コンピュートリソースが解決されるインスタンスタイプは、常に選択したフリートインスタンスタイプと同じメモリとコア数を持ちます。
フリートインスタンスタイプは AWSの スポット配置スコア API を使用して、起動時にコンピュートリソースの最適で成功の可能性が最も高いアベイラビリティーゾーンを選択します。
フリートインスタンスタイプとそのバックエンドとなるAWSインスタンスファミリーの完全なリストについては、 「フリートインスタンスタイプのリファレンス」を参照してください。
フリートの制限
- スポットインスタンスの入札率を API または JSON を使用して更新しても、ワーカーノードタイプがフリートインスタンスタイプに設定されている場合は効果がありません。 これは、スポット価格の参照ポイントとして使用するオンデマンドインスタンスが 1 つも存在しないためです。
- フリートインスタンスは GPU インスタンスをサポートしていません。
- 古いワークスペースのごく一部は、フリートインスタンスタイプをまだサポートしていません。ワークスペースにこれに当てはまる場合、フリートインスタンスタイプを使用してコンピュートまたはインスタンスプールを作成しようとすると、これを示すエラーが表示されます。 これらの残りのワークスペースにサポートを提供できるように取り組んでいます。
シングルノードコンピュート
シングルノード チェック・ボックスを使用すると、シングルノード・コンピュート・リソースを作成できます。
シングルノードコンピュートは、少量のデータまたはシングルノードの機械学習ライブラリなどの非分散ワークロードを使用するジョブを対象としています。マルチノードコンピュートは、作業負荷が分散された大規模なジョブに使用する必要があります。
単一ノードのプロパティ
シングルノードのコンピュートリソースには次のプロパティが含まれます。
- Sparkをローカルで実行します。
- ドライバーはマスターとワーカーの両方の役割を果たし、ワーカーノードはありません。
- コンピュートリソースの論理コアごとに 1 つのエグゼキュータースレッドを生成し、ドライバー用に 1 コアを引いたものです。
- すべての
stderr、stdout、およびlog4jログ出力をドライバーログに保存します。 - マルチノード コンピュート リソースに変換することはできません。
シングルノードまたはマルチノードの選択
シングルノードとマルチノードのコンピュートのどちらを使用するかは、ユースケースに応じて決定してください。
-
大規模なデータ処理では、シングルノードのコンピュートリソースのリソースが枯渇してしまいます。このようなワークロードの場合、Databricks ではマルチノードのコンピュートの使用を推奨しています。
-
マルチノード コンピュート リソースを 0 ワーカーにスケーリングすることはできません。 代わりに single node コンピュートを使用してください。
-
GPUスケジューリングはシングルノードコンピュートでは有効になっていません。
-
シングルノードコンピュートの場合、SparkはUDT列を含むParquetファイルを読み取ることができません。次のエラーメッセージが表示されます。
ConsoleThe Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.この問題を回避するには、ネイティブのParquetリーダーを無効にします。
Pythonspark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
オートスケールの有効化
「 オートスケールを有効にする 」をチェックすると、コンピュートリソースのワーカーの最小値と最大値を指定できます。その後で、ジョブの実行に必要な適切な数のワーカーを Databricks は選択します。
コンピュートリソースがオートスケールするワーカーの最小数と最大数を設定するには、 ワーカータイプ ドロップダウンの横にある 最小 フィールドと 最大 フィールドを使用します。
オートスケールを有効にしない場合は、 ワーカー タイプ ドロップダウンの横の ワーカー フィールドに固定数のワーカーを入力する必要があります。
コンピュートリソースが実行中の場合、コンピュートの詳細ページに割り当てられたワーカーの数が表示されます。割り当てられたワーカーの数をワーカーの設定と比較し、必要に応じて調整を行うことができます。
オートスケールのメリット
オートスケールを使用すると、 Databricks はジョブの特性に応じてワーカーをアカウントに動的に再割り当てします。 パイプラインの特定の部分は、他の部分よりも計算負荷が高い場合があり、Databricks はジョブのこれらのフェーズで追加のワーカーを自動的に追加します (不要になったら削除します)。
オートスケールを使用すると、ワークロードに合わせてコンピュートをプロビジョニングする必要がないため、高い使用率を簡単に実現できます。 これは、要件が時間の経過と共に変化するワークロード (1 日の間にデータセットを探索するなど) に特に当てはまりますが、プロビジョニング要件が不明な 1 回限りの短いワークロードにも適用できます。したがって、オートスケールには2つの利点があります。
- ワークロードは、固定サイズのプロビジョニング不足のコンピュートリソースと比較して高速に実行できます。
- オートスケールを使うことで、静的にサイズ調整されたコンピュートリソースと比較して全体的なコストを削減できます。
コンピュートリソースの固定サイズとワークロードに応じて、オートスケールでは、これらの利点の一方または両方が同時に実現されます。コンピュートのサイズは、クラウドプロバイダーがインスタンスを終了するときに選択されたワーカーの最小数を下回る可能性があります。この場合、Databricks は、ワーカーの最小数を維持するために、インスタンスの再プロビジョニングを継続的に再試行します。
オートスケールはspark-submitジョブでは使用できません。
コンピュートのオートスケーリングには、Structured Streamingワークロードのクラスターサイズをスケールダウンする際の制限があります。Databricksは、ストリーミングワークロード向けに、Lakeflow上のSpark宣言型パイプラインと強化されたオートスケールを使用することをお勧めします。オートスケーリングによるLakeFlow Pipelinesクラスターの利用率の最適化を参照してください。
オートスケールの動作
プレミアムプラン以上のワークスペースでは、最適化された自動スケーリングが使用されます。スタンダードプランのワークスペースでは、標準の自動スケーリングが使用されます。
最適化されたオートスケールには、次の特性があります。
- 最小値から最大値まで、最大2回のスケーリングイベントでスケールアップします。
- コンピュートリソースがアイドル状態になくても、シャッフルファイルの状態を調べることでスケールダウンできます。
- 現在のノードの割合に基づいてスケールダウンします。
- ジョブコンピュートでは、コンピュートリソースが過去 40 秒間に十分に活用されていない場合はスケールダウンします。
- 汎用 コンピュートは、過去 150 秒間にコンピュートリソースが十分に活用されていない場合にスケールダウンします。
spark.databricks.aggressiveWindowDownSSpark 構成プロパティは、コンピュートがダウンスケーリングの決定を行う頻度を秒単位で指定します。値を大きくすると、コンピュートのスケールダウンが遅くなります。最大値は600です。
標準プランのワークスペースでは標準のオートスケールが使用されます。標準のオートスケールには次の特性があります。
- まず8ノードを追加します。その後、指数関数的にスケールアップし、最大値に達するまでに必要なステップ数を踏みます。
- ノードの90%が10分間ビジー状態でなく、コンピュートも30秒以上アイドル状態である場合にスケールダウンします。
- 1 ノードから指数関数的にスケールダウンします。
Databricksオートスケールを使用するコンピュート リソースでは、 Apache Spark動的割り当て ( spark.dynamicAllocation.enabled ) を有効にしないでください。 Databricksオートスケールは、ワーカーノードとエグゼキューターのライフサイクルをプラットフォームレベルで管理します。 Spark Dynamic Allocation を並行して有効にすると、スケーリング決定の競合が発生し、エグゼキューターのチャーン、 NODES_LOSTエラー、および決して取得されないタスクが発生する可能性があります。
プールによるオートスケール
コンピュートリソースをプールに接続する場合は、次の点を考慮してください。
-
要求されたコンピュート サイズが、プール内の アイドル インスタンスの最小数 以下であることを確認してください。 それより大きい場合、コンピュートの起動時間はプールを使わないコンピュートと同等になります。
-
コンピュートの最大サイズがプール の最大容量 以下であることを確認してください。 大きいとコンピュートの作成に失敗します。
オートスケール の例
静的コンピュートリソースをオートスケールするように再構成すると、Databricks はすぐにコンピュートリソースのサイズを最小値と最大値の範囲内で変更し、オートスケールを開始します。例として、次の表は、5~10 ノードの間でオートスケールするようにコンピュートリソースを再構成した場合に、特定の初期サイズのコンピュートリソースに何が起こるかを示しています。
初期サイズ | 再構成後のサイズ |
|---|---|
6 | 6 |
12 | 10 |
3 | 5 |
パフォーマンスの詳細設定
次の設定は、単純な形式のコンピュートUIの[ 高度なパフォーマンス ]セクションの下に表示されます。
スポットインスタンス
スポットインスタンスを使用するかどうかを指定するには、[ Advanced performance] (アドバンストパフォーマンス ) の [ Use spot instance] (スポットインスタンスを使用 ) チェックボックスをオンにします。スポット価格AWSを参照してください。
最初のインスタンスは常にオンデマンド (ドライバー ノードは常にオンデマンド) になり、後続のインスタンスはスポット インスタンスになります。
自動終了
コンピュート作成フォームの**パフォーマンス**セクションで、コンピュートの自動終了を設定できます。コンピュートの作成時に、コンピュート リソースを終了する非アクティブ期間を分単位で指定します。
コンピュート リソースで現在時刻と最後に実行されたコマンドの差が、指定した非アクティブ期間よりも大きい場合、 Databricks はそのコンピュート リソースを自動的に終了します。 コンピュートの終了の詳細については、「 コンピュートの終了」を参照してください。
ドライバーの種類
高度なパフォーマンス セクションでドライバーの種類を選択できます。ドライバー ノードは、コンピュート リソースに接続されているすべてのノートブックの状態情報を保持します。 ドライバー ノードは、SparkContext も保持し、コンピュート リソース上のノートブックまたはライブラリから実行するすべてのコマンドを解釈し、Apache Spark Sparkエグゼキューターと調整する マスターを実行します。
ドライバーノードタイプのデフォルト値は、ワーカーノードタイプと同じです。Sparkワーカーから大量のデータをcollect()により収集してノートブックで分析する場合は、より多くのメモリを備えたより大きなドライバーノードの種類を選択できます。
ドライバーノードは、アタッチされているノートブックのすべての状態情報を保持するため、未使用のノートブックは必ずドライバーノードからデタッチしてください。
タグ
タグを使用すると、組織内のさまざまなグループで使用されるコンピュート リソースのコストを簡単に監視できます。 コンピュートを作成するときにキーと値のペアとしてタグを指定すると、 Databricks はこれらのタグを VM やディスク ボリュームなどのクラウド リソース、および Databricks 使用状況ログに適用します。
プールから起動されたコンピュートの場合、カスタムタグはDBU使用状況レポートにのみ適用され、クラウドリソースには伝わりません。
プールとコンピュートのタグタイプがどのように連携するかについての詳細な情報については、「タグを使用して使用状況を属性付けおよび追跡する」を参照してください
コンピュートリソースにタグを追加する方法は次のとおりです。
- [ タグ ] セクションで、各カスタムタグのキーと値のペアを追加します。
- [ 追加 ] をクリックします。
詳細設定
次の設定は、シンプル フォーム コンピュート UI の Advanced セクションの下に表示されます。
- アクセスモード
- インスタンスプロファイル
- アベイラビリティゾーン
- AWS キャパシティーブロック
- ローカルストレージのオートスケールを有効化
- EBS ボリューム
- ローカルディスクの暗号化
- Spark構成
- コンピュートログのデリバリー
- 環境変数
アクセスモード
アクセス モードは、コンピュート リソースを使用できるユーザーと、コンピュート リソースを使用してアクセスできるデータを決定するセキュリティ機能です。 Databricks内のすべてのコンピュート リソースにはアクセス モードがあります。アクセスモードの設定は、シンプルフォームのコンピュートUIの Advanced セクションにあります。
アクセスモードの選択はデフォルトで 自動 です。これは、選択した Databricks Runtime に基づいてアクセスモードが自動的に選択されることを意味します。機械学習ランタイム、GPUインスタンスタイプ、またはバージョンが14.3より低いDatabricks Runtimeが選択されていない限り、自動でデフォルトは**Standard**になります。選択されている場合は**Dedicated**が使用されます。
Databricks では、必要な機能がサポートされていない限り、標準アクセス モードを使用することをお勧めします。
アクセスモード | 説明 | 対応言語 |
|---|---|---|
Standard | ユーザー間でデータを分離することにより、複数のユーザーが使用できます。 | Python、SQL、Scala |
専用 | 1 人のユーザーまたはグループに割り当てて使用できます。 | Python、SQL、Scala、R |
これらの各アクセス モードの機能サポートの詳細については、「 標準コンピュートの要件と制限 」および 「専用コンピュートの要件と制限」を参照してください。
Databricks Runtime 13.3 LTS以降では、initスクリプトとライブラリはすべてのアクセスモードでサポートされています。要件とサポートのレベルは異なります。 initスクリプトはどこでインストールできますか? および コンピュートスコープのライブラリを参照してください。
インスタンスプロファイル
DatabricksUnity Catalogに接続するにはS3 インスタンスプロファイルの代わりに外部ロケーションを使用することをお勧めします。Unity Catalog は、アカウント内の複数のワークスペースにわたるデータアクセスを一元的に管理および監査するための場所を提供することで、データのセキュリティとガバナンスを簡素化します。「Unity Catalog を使用してクラウド オブジェクト ストレージに接続する」を参照してください。
AWSキーを使用せずにAWSリソースに安全にアクセスするには、インスタンスプロファイルを使用してDatabricksコンピュートを起動できます。インスタンスプロファイルの作成および設定方法については、 チュートリアル: インスタンスプロファイルを使用して S3 アクセスを設定する を参照してください。 インスタンスプロファイルを作成したら、 インスタンスプロファイル ドロップダウンリストで選択します。
コンピュートリソースを起動したら、次のコマンドを使用して S3 バケットにアクセスできることを確認してください。コマンドが成功すると、そのコンピュートリソースは S3 バケットにアクセスできるようになります。
dbutils.fs.ls("s3a://<s3-bucket-name>/")
コンピュート リソースがインスタンスプロファイルを使用して起動すると、このコンピュート リソースへのアタッチ アクセス許可を持つすべてのユーザーが、このロールによって制御される基になるリソースにアクセスできます。 不要なアクセスを防ぐには、 コンピュート パーミッション を使用して、コンピュート リソースへのパーミッションを制限します。
可用性ゾーン
アベイラビリティーゾーンの設定を見つけるには、「 Advanced 」セクションを開き、「 Instances」 タブをクリックします。 この設定では、コンピュート リソースで使用するアベイラビリティーゾーン (AZ) を指定できます。 デフォルトでは、この設定は auto に設定されており、ワークスペースサブネットで使用可能な IP に基づいて AZ が自動的に選択されます。 自動 AZ は、AWS が容量不足エラーを返した場合、他のアベイラビリティーゾーンで再試行します。
Auto-AZ はコンピュート起動時にのみ動作します。コンピュートリソースが起動した後、コンピュートリソースが終了または再起動されるまで、すべてのノードは元のアベイラビリティーゾーンに残ります。
コンピュート リソースに特定の AZ を選択することは、主に組織が特定のアベイラビリティーゾーンでリザーブドインスタンスを購入した場合に便利です。 AWS アベイラビリティーゾーンの詳細については、AWS のドキュメントを参照してください。
HA (高可用性ゾーン) は非推奨の AZ 設定です。HA はバックグラウンドで auto に解決されます。
AWS キャパシティーブロック
AWSキャパシティ ブロックを使用すると、特定の AZ で特定の時間のコンピュート キャパシティを予約できます。 Databricksコンピュートで Capacity Blocks を使用するには、特定のタグと可用性ゾーンを使用してコンピュート リソースを構成します。
-
AWS ポータルでキャパシティーブロックを購入します。詳細については、キャパシティーブロックの購入に関する AWS ドキュメントを参照してください。
- インスタンスの合計数が予想される使用量に対して十分であることを確認します。
- AWS がキャパシティーブロック予約に割り当てるアベイラビリティーゾーンに注意してください。
- ワークスペースに、キャパシティー ブロックと同じアベイラビリティー ゾーンのサブネットがあることを確認します。
- Databricks 構成で使用するために、AWS から容量ブロック ID をコピーします。
-
容量ブロック予約のアクティブ化時刻が来たら、次の設定でDatabricksコンピュート リソースを作成します。
-
次のタグを追加します。
- 鍵 :
X-Databricks-AwsCapacityBlockId - 値 : AWS からの容量ブロック ID すべてのノードをオンデマンドインスタンスを使用するように構成します。
- 鍵 :
-
[高度なパフォーマンス] で、 [スポットインスタンスを使用する] チェックボックスをオフにします。
-
[詳細] > [インスタンス] で、キャパシティー ブロックに割り当てられた特定のアベイラビリティー ゾーンを選択します。
-
-
コンピュート構成を完了し、 「作成」 をクリックします。
キャパシティ ブロックを使用してコンピュート リソースを起動するには、キャパシティ ブロックをアクティブにする必要があります。 AWS ポータルでキャパシティーブロック予約の有効化時間を確認します。
オートスケール ローカル ストレージを有効にする
ローカルストレージのオートスケールを有効にする を構成するには、 Advanced セクションを開き、 インスタンス タブをクリックします。
コンピュート作成時に一定数の EBS ボリュームを割り当てたくない場合は、オートスケールのローカルストレージを使用してください。 オートスケール ローカル ストレージを使用すると、 Databricks はコンピュートの Spark ワーカーの空きディスク容量を監視します。 ワーカーがディスク上で実行を開始したディスクが少なすぎる場合、 Databricks は、ディスク領域から実行する前に、新しい EBS ボリュームをワーカーに自動的にアタッチします。 EBS ボリュームは、インスタンスあたり合計ディスク容量 (インスタンスのローカルストレージを含む) の上限 5 TB までアタッチされます。
インスタンスにアタッチされた EBS ボリュームは、インスタンスが AWS に返されたときにのみデタッチされます。 つまり、EBS ボリュームは、実行中のコンピュートの一部である限り、インスタンスから切り離されることはありません。 EBS の使用量をスケールダウンするには、Databricksオートスケール コンピュートまたは自動終了で構成されたコンピュートでこの機能を使用することをお勧めします。
Databricks は Amazon EBS GP3 ボリュームを使用して、インスタンスのローカルストレージを拡張します。 これらのボリュームの デフォルトの AWS 容量制限 は 50 TiB です。 この制限に達しないようにするには、管理者は使用要件に基づいてこの制限の引き上げをリクエストする必要があります。
EBS ボリューム
このセクションでは、ワーカーノードのデフォルトのEBSボリューム設定、シャッフルボリュームの追加方法、およびDatabricksがEBSボリュームを自動的に割り当てるようにコンピュートを構成する方法について説明します。
EBS ボリュームを設定するには、コンピュートをオートスケールローカルストレージで有効にしないでください。 コンピュート構成の 「詳細 」の下にある 「インスタンス 」タブをクリックし、「 EBS ボリュームタイプ 」ドロップダウンリストでオプションを選択します。
デフォルトの EBS ボリューム
Databricksは、次のようにすべてのワーカーノードに対してEBSボリュームをプロビジョニングします。
- ホストオペレーティングシステムとDatabricks内部サービスによって使用される、30 GBの暗号化されたEBSインスタンスルートボリューム。
- Sparkワーカーが使用する150 GBの暗号化されたEBSコンテナルートボリューム。これは、Sparkサービスとログをホストします。
- (HIPAAのみ)Databricks内部サービスのログを保存する75 GBの暗号化されたEBSワーカーログボリューム。
EBS シャッフルボリュームの追加
シャッフルボリュームを追加するには、[ EBSボリュームタイプ ] ドロップダウンリストで [ 汎用SSDボリューム ] を選択します。
デフォルトでは、Sparkシャッフルの出力内容はインスタンスのローカルディスクに送信されます。インスタンスがローカルディスクを持たないタイプである場合や、Sparkシャッフルのストレージ容量を増やしたい場合は、追加のEBSボリュームを指定できます。 この措置は、大きなシャッフル出力を生成するSparkジョブの実行において、ディスク容量不足エラーが発生する事態を回避したい場合に、特に有効です。
Databricksは、オンデマンドインスタンスとスポットインスタンスの両方でこれらのEBSボリュームを暗号化します。AWS EBSボリュームの詳細についてお読みください。
オプションで、 Databricks EBS ボリュームを顧客管理のキーで暗号化します
オプションとして、カスタマが管理するキーでコンピュートEBSボリュームを暗号化することができます。
暗号化については、顧客管理のキーを参照してください。
AWS EBS の制限
AWS EBSの上限が、デプロイされたすべてのコンピュートですべてのワーカーのランタイム要件を満たすのに十分であることを確認してください。 デフォルトのEBS制限とその変更方法については、「Amazon Elastic Block Store(EBS)の制限」を参照してください。
AWS EBS SSD ボリュームタイプ
AWS EBS SSD ボリュームタイプとして gp2 または gp3 を選択します。 これを行うには、「 SSD ストレージの管理」を参照してください。 Databricks では、gp2 と比較してコストを節約できるため、gp3 に切り替えることをお勧めします。
デフォルトでは、Databricks 構成は gp3 ボリュームの IOPS とスループット IOPS を、同じボリュームサイズの gp2 ボリュームの最大パフォーマンスと一致するように設定します。
gp2およびgp3の技術情報については、「Amazon EBSボリュームタイプ」を参照してください。
ローカルディスクの暗号化
プレビュー
この機能は パブリック プレビュー段階です。
コンピュートの実行に使用する一部のインスタンスタイプには、ローカルにアタッチされたディスクがある場合があります。 Databricks は、これらのローカルにアタッチされたディスクにシャッフル データまたはエフェメラル データを格納する場合があります。コンピュート リソースのローカル ディスクに一時的に保存されるシャッフル データを含め、すべてのストレージの種類で保存されているすべてのデータが暗号化されるようにするには、ローカル ディスクの暗号化を有効にすることができます。
ローカルボリュームとの間で暗号化されたデータを読み書きするとパフォーマンスに影響を与え、ワークロードの実行が遅くなる可能性があります。
ローカルディスクの暗号化が有効な場合、Databricksは各コンピュートノードに固有の暗号化キーをローカルに生成し、ローカルディスクに保存されたすべてのデータを暗号化するために使用します。キーのスコープは各コンピュートノードに対してローカルであり、コンピュートノード自体と共に破棄されます。鍵の有効期間中、鍵は暗号化と復号化のためにメモリに存在し、ディスクに暗号化されて保存されます。
ローカル ディスクの暗号化を有効にするには、クラスター の APIを使用する必要があります。コンピュートの作成または編集時には、 enable_local_disk_encryption を trueに設定します。
Spark の構成
Sparkジョブを微調整するために、カスタムSpark構成プロパティを指定できます。
標準アクセスモードでは、Databricks Runtime 19以降、特定のSpark構成プロパティが制限されます。制限されたプロパティを設定するクラスターを作成または編集すると、エラーが発生して失敗します。Spark構成の制限を参照してください。
-
コンピュートの設定ページで、[ 詳細設定 ] トグルをクリックします。
-
[ Spark ] タブをクリックします。
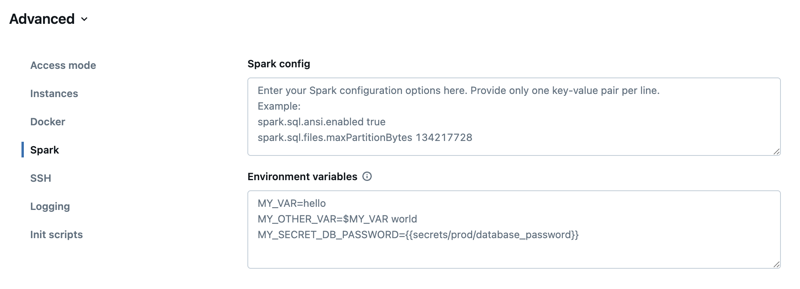
-
Spark構成 では、1行に1つのキーと値のペアとして設定プロパティを入力します。
Cluster APIを使用してコンピュートを設定する場合は、Create cluster APIまたはUpdate Cluster APIでspark_confフィールドでSparkプロパティを設定します。
コンピュートで Spark 構成を適用するために、ワークスペース管理者は コンピュート ポリシーを使用できます。
シークレットから Spark 構成プロパティを取得する
Databricks では、パスワードなどの機密情報をプレーンテキストではなく シークレット に格納することをお勧めします。 Spark 構成でシークレットを参照するには、次の構文を使用します。
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
たとえば、passwordというSpark構成プロパティをsecrets/acme_app/passwordに保存されているシークレットの値に設定するには、次のようにします。
spark.password {{secrets/acme-app/password}}
詳細については、「 シークレットの管理」を参照してください。
コンピュート ログのデリバリー
汎用またはジョブ コンピュートを作成する場合、 Sparkドライバー、ワーカー ノード、およびイベントからのログを含むクラスター ログの場所を指定できます。 ログは5分ごとに配信され、1時間ごとに指定された場所にアーカイブされます。Databricks 、コンピュート リソースが終了するまでログの配信を続けます。
ログは以下のいずれかの場所に保存できます。
-
ボリューム(推奨):ログをUnity Catalogボリュームパスに保存します。 これは、Unity カタログ対応のコンピュート リソースを使用する場合に推奨される最も安全なオプションです。
-
S3: ログをAmazon S3バケットパスに保存します。
-
DBFS(レガシー):ログをDatabricksファイルシステム(DBFS)パスに保存します。このオプションは、ワークスペースのDBFSルートとマウントが無効になっていない場合にのみ利用可能です。DBFSルートへのアクセスを無効にし、既存のDatabricksワークスペースにマウントする」を参照してください。
ログの配信場所を設定するには、以下の手順に従ってください。
- [コンピュート] ページで、[ 詳細設定 ] トグルをクリックします。
- [ ロギング ] タブをクリックします。
- 宛先タイプを選択します。
- ログパス を入力します。
ログを保存するために、 Databricks は選択したログ パスに、コンピュートのcluster_idにちなんで名付けられたサブフォルダを作成します。
たとえば、指定したログパスが /Volumes/catalog/schema/volumeの場合、 06308418893214 のログは
/Volumes/catalog/schema/volume/06308418893214。
ボリュームへのログの配信は、Unity Catalog が有効になっているコンピュートで、 標準 アクセス モードまたは 専用 アクセス モードがユーザーに割り当てられた場合にのみサポートされます。 グループに割り当てられた 専用 アクセスモードではサポートされていません。パスとしてボリュームを選択した場合は、コンピュートの所有者またはそれに割り当てられたユーザーが、そのボリュームに対してREAD VOLUMEおよびWRITE VOLUME権限を持っていることを確認してください。 Unity Catalogボリュームの権限」を参照してください。
S3 バケットの送信先
S3の送信先を選択する場合は、バケットにアクセスできるインスタンスプロファイルを使用してコンピュート リソースを設定する必要があります。このインスタンスプロファイルには、 PutObject と PutObjectAcl の両方のアクセス許可が必要です。 インスタンスプロファイルの例
あなたの便宜のために含まれています。 インスタンスプロファイルの設定方法については 、「チュートリアル: インスタンスプロファイルを使用した S3 アクセスの設定 」を参照してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<my-s3-bucket>"]
},
{
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:PutObjectAcl", "s3:GetObject", "s3:DeleteObject"],
"Resource": ["arn:aws:s3:::<my-s3-bucket>/*"]
}
]
}
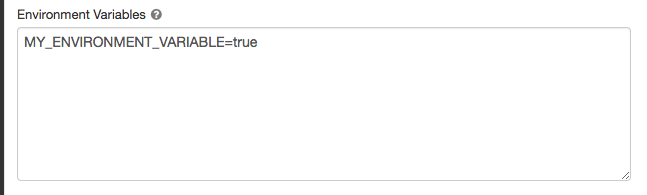
環境変数
コンピュート リソース上で実行されている initスクリプト からアクセスできるカスタム環境変数を設定します。 Databricks には、initスクリプトで使用できる定義済みの 環境変数 も用意されています。 これらの事前定義された環境変数を上書きすることはできません。
-
コンピュート構成ページで、 「詳細」 をクリックします。
-
[ Spark ] タブをクリックします。
-
[ 環境変数 ] フィールドで環境変数を設定します。
Create cluster APIまたはUpdate cluster APIのspark_env_varsフィールドを使用して環境変数を設定することもできます。