マルチGPUおよびマルチノードワークロード
サーバレスGPU Python APIを使用して、単一ノードあるいは複数ノードにおける複数のGPUに対して分散ワークロードを起動することができます。 このAPIは、GPU プロビジョニング、環境セットアップ、ワークロードの分散の詳細を抽象化したシンプルで統一されたインターフェイスを提供します。同じノートブックで、単一 GPU のトレーニングからリモート GPU 間の分散実行に最小限のコード変更でシームレスに移行できます。
マルチ GPU 分散トレーニングは、H100 と A10 の両方でサポートされています。マルチノード分散トレーニング A10 GPU でのみサポートされます。
クイックスタート
サーバレスGPUコンピュートには、Databricksノートブックの環境向けに分散トレーニング用のサーバレスGPU APIがプリインストールされています。GPU環境4以上を推奨します。分散トレーニングに使用するには、あなたのトレーニング関数を分散させるために、インポートを行い、distributedデコレータを使用します。
以下のコード スニペットは、 @distributedの基本的な使用方法を示しています。
# Import the distributed decorator
from serverless_gpu import distributed
# Decorate your training function with @distributed and specify the number of GPUs, the GPU type,
# and whether or not the GPUs are remote
@distributed(gpus=8, gpu_type='A10', remote=True)
def run_train():
...
以下は、ノートブックで8 つの A10 GPU ノードで多層パーセプトロン (MLP) モデルをトレーニングする完全な例です:
-
モデルを設定し、ユーティリティ関数を定義します。
Python
# Define the model
import os
import torch
import torch.distributed as dist
import torch.nn as nn
def setup():
dist.init_process_group("nccl")
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
def cleanup():
dist.destroy_process_group()
class SimpleMLP(nn.Module):
def __init__(self, input_dim=10, hidden_dim=64, output_dim=1):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
return self.net(x) -
serverless_gpu ライブラリと 分散 モジュールをインポートします。
Pythonimport serverless_gpu
from serverless_gpu import distributed -
モデルトレーニング コードを関数でラップし、その関数を
@distributedデコレータで装飾します。Python@distributed(gpus=8, gpu_type='A10', remote=True)
def run_train(num_epochs: int, batch_size: int) -> None:
import mlflow
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, DistributedSampler, TensorDataset
# 1. Set up multi node environment
setup()
device = torch.device(f"cuda:{int(os.environ['LOCAL_RANK'])}")
# 2. Apply the Torch distributed data parallel (DDP) library for data-parellel training.
model = SimpleMLP().to(device)
model = DDP(model, device_ids=[device])
# 3. Create and load dataset.
x = torch.randn(5000, 10)
y = torch.randn(5000, 1)
dataset = TensorDataset(x, y)
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size)
# 4. Define the training loop.
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()
for epoch in range(num_epochs):
sampler.set_epoch(epoch)
model.train()
total_loss = 0.0
for step, (xb, yb) in enumerate(dataloader):
xb, yb = xb.to(device), yb.to(device)
optimizer.zero_grad()
loss = loss_fn(model(xb), yb)
# Log loss to MLflow metric
mlflow.log_metric("loss", loss.item(), step=step)
loss.backward()
optimizer.step()
total_loss += loss.item() * xb.size(0)
mlflow.log_metric("total_loss", total_loss)
print(f"Total loss for epoch {epoch}: {total_loss}")
cleanup() -
ユーザー定義の引数を使用して分散関数を呼び出して、分散トレーニングを実行します。
Pythonrun_train.distributed(num_epochs=3, batch_size=1) -
実行すると、ノートブックのセルの出力に MLflow 実行リンクが生成されます。MLflow実行リンクをクリックするか、 エクスペリメント パネルでリンクを見つけて、実行結果を確認します。
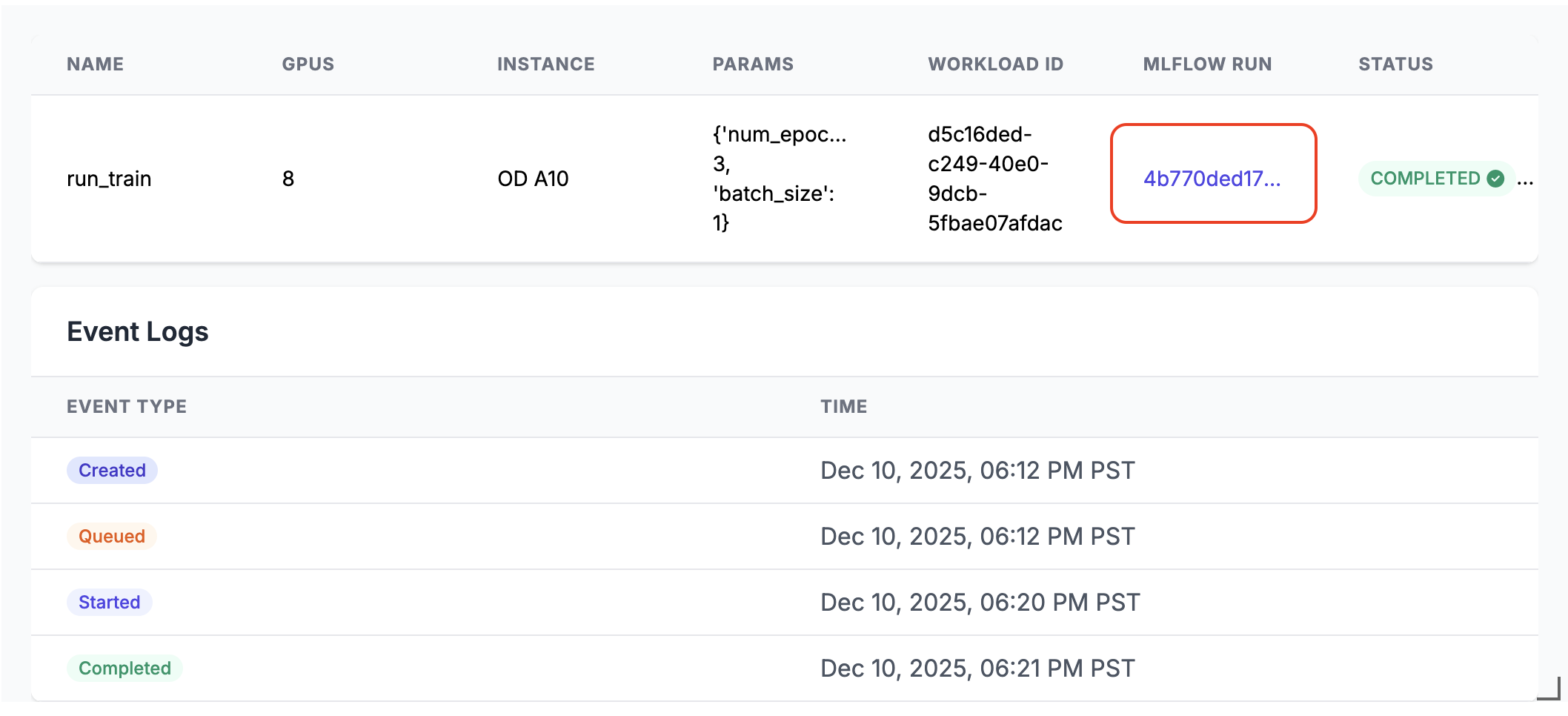
分散実行の詳細
サーバーレス GPU API 、いくつかの主要コンポーネントで構成されています。
- コンピュートマネージャー: リソースの割り当てと管理を処理します。
- Runtime環境: Python環境と依存関係を管理します
- ランチャー: ジョブの実行とモニタリングを調整します。
分散モードで実行する場合:
- 関数はシリアル化され、指定された数のGPUに分散されます。
- 各 GPU は同じ問題を持つ関数のコピーを実行します
- 環境はすべてのノード間で同期されます
- 結果はすべてのGPUから収集され返されます
remote Trueに設定されている場合、ワークロードはリモート GPU に分散されます。remoteが
False 、ワークロードは現在のノートブックに接続されている単一の GPU ノードで実行されます。ノードに複数の GPU チップがある場合、それらすべてが利用されます。
APIは、分散データ並列(DDP)完全シャーディングデータパラレル(FSDP) DeepSpeed、Ray などの一般的な並列トレーニングライブラリをサポートしています。
ノートブックの例にあるさまざまなライブラリを使用して、より実際の分散トレーニング シナリオを見つけることができます。
Rayによる起動
サーバレス GPU APIは、@distributedをベースとした@ray_launchデコレーターを使用した Ray を使用した分散トレーニングの起動もサポートしています。Rayヘッドワーカーを決定し、IP を収集するために、各ray_launchタスクは、まずtorch分散ランデブーをブートストラップします。ランク 0 はray start --headを開始し (有効な場合はメトリクス エクスポートを使用)、RAY_ADDRESSを設定し、デコレートした関数を Ray ドライバーとして実行します。 他のノードはray start --address経由で参加し、ドライバーが完了マーカーを書き込むまで待機します。
追加の構成の詳細:
- 各ノードで Ray システムのメトリクス収集を有効にするには、
RayMetricsMonitorremote=Trueとともに使用します。 - Ray ランタイム オプション (アクター、データセット、配置グループ、スケジュール) を 標準の Ray APIを使用して装飾された関数。
- クラスター全体の制御 (GPU の数と種類、リモート モードとローカル モード、非同期動作、および Databricksプール環境変数) の関数の 外側の デコレーター引数、または ノートブック環境。
以下の例は、 @ray_launch使用方法を示しています。
from serverless_gpu.ray import ray_launch
@ray_launch(gpus=16, remote=True, gpu_type='A10')
def foo():
import os
import ray
print(ray.state.available_resources_per_node())
return 1
foo.distributed()
完全な例については、この例のノートブックを参照してください。 これにより、Ray が起動され、複数の A10 GPU で Resnet18 ニューラルネットワークをトレーニングします。
このAPIを使用して、LLM 上で分散バッチ推論を実行するための、AI ワークロード向けのスケーラブルなデータ処理ライブラリであるRay Dataを呼び出すこともできます。vllmとsglangの例をご覧ください。
よくある質問
データ読み込みコードはどこに配置すればよいですか?
サーバレスGPU APIを使用する場合 分散トレーニングの場合は、データ読み込みコードを@distributedデコレータ内に移動します。 データセット サイズはpickleで許可されている最大サイズを超える可能性があるため、データセットを生成することをお勧めします。 デコレータ内では次のように記述します。
from serverless_gpu import distributed
# this may cause pickle error
dataset = get_dataset(file_path)
@distributed(gpus=8, remote=True)
def run_train():
# good practice
dataset = get_dataset(file_path)
....
予約済みの GPU プールを使用できますか?
予約済みの GPU プールがワークスペースで利用可能 (管理者に確認してください) で、指定した場合
@distributed デコレータでremoteからTrue指定すると、ワークロードは予約された GPU で起動されます。
勝手にプール。 オンデマンド GPU プールを使用する場合は、環境変数を設定してください
分散関数を呼び出す前に、以下のようにDATABRICKS_USE_RESERVED_GPU_POOLをFalseに変更します。
import os
os.environ['DATABRICKS_USE_RESERVED_GPU_POOL'] = 'False'
@distributed(gpus=8, remote=True)
def run_train():
...
もっと詳しく知る
APIリファレンスについては、 GPU Python APIドキュメントを参照してください。