Databricksのスキーマの進化
スキーマ進化 とは、時間の経過に伴うデータ構造の変化に適応するシステムの能力を指します。 これらの変更は、新しいフィールドが追加されたり、データ型が変化したり、ネストされた構造が進化したりする半構造化データ、イベント ストリーム、またはサードパーティ ソースを操作する場合によく発生します。
一般的な変更には次のようなものがあります:
- 新しい列 : 以前に定義されていなかった追加のフィールド。カスタムのバックフィル値が設定される場合もあります。
- 列名の変更 : 列名を、たとえば
nameからfull_nameに変更します。 - 削除された列 : テーブル スキーマから列を削除します。
- 型の拡張 : 列の型をより広い型に変更します。たとえば、
INTフィールドはDOUBLEになります。 - その他のタイプの変更 : 列のタイプを変更します。たとえば、
INTフィールドはSTRINGになります。
スキーマ進化のサポートは、頻繁に手動で更新することなく変化するデータに対応できる、回復力があり、長期にわたって実行されるパイプラインを構築するために重要です。
コンポーネント
Databricksスキーマ進化には 4 つの主要なコンポーネント カテゴリが含まれており、それぞれがスキーマの変更を個別に処理します。
- コネクタ : 外部ソースからデータを取り込むコンポーネント。これらには、 Auto Loader 、 Kafka 、 Kinesis 、 Lakeflowコネクタが含まれます。
- フォーマット パーサー :
from_json、from_avro、from_xml、from_protobufなどの生のフォーマットをデコードする関数。 - エンジン : 構造化ストリーミングを含むクエリを実行する処理エンジン。
- データセット : ストリーミング テーブル、マテリアライズド ビュー、 Deltaテーブル、およびデータを保持して提供するビュー。
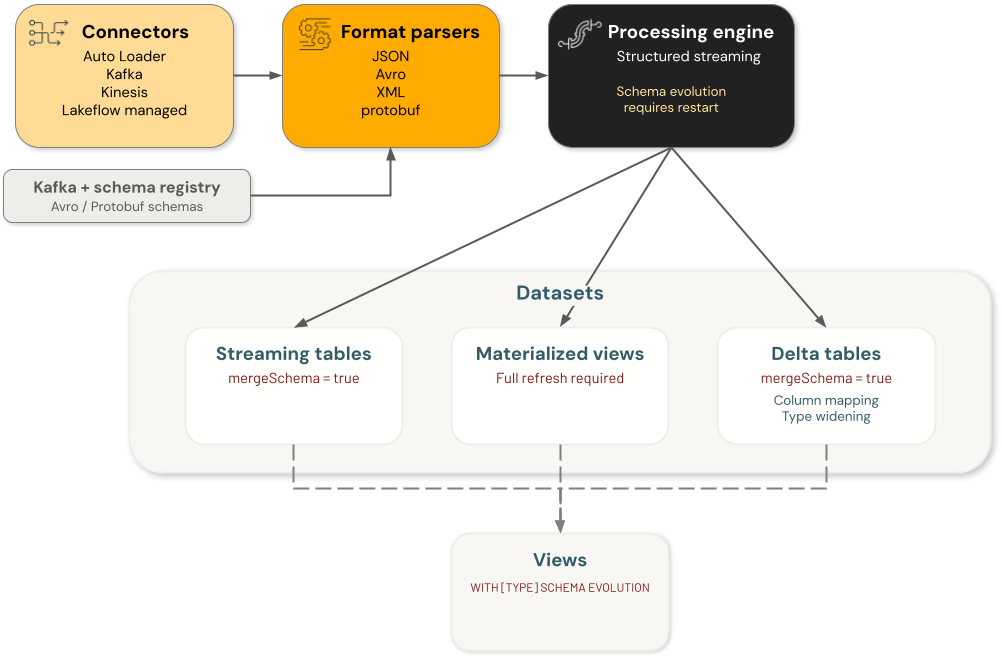
データエンジニアリング アーキテクチャのスキーマ進化の各コンポーネントは独立しています。 データ処理フローで目的の動作を実現するために、個々のコンポーネントでゲスト進化を構成する必要があります。
例えば、Auto Loader を使用して Delta テーブルにデータをインジェストする際、2つの永続スキーマが存在します。1つは Auto Loader のスキーマロケーションで管理され、もう1つはターゲットの Delta テーブルのスキーマです。安定状態では、両者は同一です。Auto Loader が入力データに基づいてスキーマを進化させる際、Delta テーブルもスキーマを進化させる必要があります。そうしないと、クエリは失敗します。その場合、(a) スキーマ進化を有効にするか直接DDLコマンドを使用することでターゲットの Delta テーブルスキーマを更新するか、または (b) ターゲットの Delta テーブルを完全に書き換えることができます。
コネクタによるスキーマ進化のサポート
次のセクションでは、各 Databricks コンポーネントがさまざまな種類のスキーマ変更を処理する方法について詳しく説明します。
Auto Loader
Auto Loader列の変更と型の拡張に対応しています。 cloudFiles.schemaEvolutionModeとrescuedDataColumnを使用して、自動スキーマ進化を設定します。手動でschemaHints設定するか、変更不可能なschema設定できます。スキーマを自動的に進化させる際、ストリームは最初に失敗します。再起動時には、進化させたスキーマが使用されます。「Auto Loaderのスキーマ進化はどのように機能するのか?」を参照してください。
- 新しい列 : 選択した
schemaEvolutionModeに応じてサポートされます。失敗し、スキーマに新しい列を追加するには手動で再起動する必要があります。 - 列名の変更 : 選択した
schemaEvolutionModeに応じてサポートされます。名前が変更された列は追加された新しい列として扱われ、新しい行の古い列にはNULLが入力されます。スキーマを更新するには手動で再起動する必要があり、失敗します。 - ドロップされた列 : サポートされています。ソフト削除として扱われ、削除された列の新しい行は
NULLに設定されます。 - 型の拡張 : Databricks Runtime 16.4 以降で
schemaEvolutionModeaddNewColumnsWithTypeWideningに設定することでサポートされます。サポートされているデータ型の変更は自動的に拡張されます。サポートされていない型変更はrescuedDataColumnに記録されます。Auto Loaderによる自動型幅調整を参照してください。 - その他のタイプの変更 : サポートされていません。
rescueDataColumnが設定され、schemaEvolutionModeがrescueに設定されている場合、型の変更はrescuedDataColumnでキャプチャされます。それ以外の場合は、手動でスキーマを変更する必要があります。
Deltaコネクタ
Deltaコネクタはスキーマ進化に対応可能です。 列マッピングとschemaTrackingLocationが有効になっているDeltaテーブルから読み取る場合、列の名前変更と列の削除に対するスキーマ進化がサポートされます。 ストリームを停止せずにスキーマを展開するには、それぞれの変更に対して正しい Spark 構成を設定する必要があります。それ以外の場合、ストリームは変更が検出されるたびに追跡対象のスキーマを展開し、その後停止します。処理を再開するには、ストリーミング クエリを手動で再起動する必要があります。
- 新しい列 : サポートされています。
mergeSchema有効にすると、新しい列が自動的に追加されます。そうでない場合、クエリは失敗し、新しい列をスキーマに追加するためにストリームを再起動する必要がありますが、Delta テーブルは書き換える必要はありません。 - 列の名前の変更:サポートされています。Spark構成
spark.databricks.delta.streaming.allowSourceColumnRenameを使用して、ストリーミングクエリ内でスキーマを進化させることができます。 - ドロップされた列 : サポートされています。Spark設定
spark.databricks.delta.streaming.allowSourceColumnDropを使用して、ストリーミングクエリ内でスキーマを進化させることができます。 - **型の拡張**: Databricks Runtime 16.4 LTS以降でサポートされています。
mergeSchemaが有効になっており、ターゲットテーブルで型の拡張が有効になっている場合、型変更は自動的に処理されます。delta.enableTypeWideningテーブルプロパティを使用して、型の拡張を有効にできます。型の拡張を参照してください。 - その他のタイプの変更 : サポートされていません。
SaaS および CDC コネクタ
SaaS および CDC コネクタは、列が変更されるとスキーマを自動的に進化させます。これは、変更が検出されると自動的に再起動することで処理されます。タイプを変更するには完全な更新が必要です。
- 新しい列 : サポートされています。スキーマの不一致を解決するためにクエリが自動的に再開されます。
- 列名の変更 : サポートされています。スキーマの不一致を解決するためにクエリが自動的に再開されます。名前を変更した列は、新しく追加された列として扱われます。
- ドロップされた列 : サポートされています。削除された列はソフト削除として扱われ、削除された列の新しい行は
NULLに設定されます。 - 型の拡張 : サポートされていません。スキーマを更新するには完全な更新が必要です。
- その他のタイプの変更 : サポートされていません。スキーマを更新するには完全な更新が必要です。
Kinesis、Kafka、Pub/Sub、Pulsar コネクタ
ネイティブのスキーマ進化はサポートされていません。 各コネクタ関数はバイナリ BLOB を返します。スキーマ進化はフォーマットパーサーによって処理されます。
- 新しい列 : フォーマット パーサーによって処理されます。
- 列の名前変更 : フォーマット パーサーによって処理されます。
- 削除された列 : フォーマット パーサーによって処理されます。
- 型の拡張 : フォーマット パーサーによって処理されます。
- その他の型の変更 : フォーマット パーサーによって処理されます。
フォーマットパーサーによるスキーマ進化のサポート
from_jsonパーサー
from_jsonパーサーはスキーマ進化をサポートしていません。スキーマを手動で更新する必要があります。When using from_json within LakeFlow Pipelines, automatic スキーマ進化 can be enabled with schemaLocationKey and schemaEvolutionMode.
- 新しい列 : 自動スキーマ進化が有効になっている場合、Auto Loader のように動作します。
- 列の名前変更 : 自動スキーマ進化が有効になっている場合、Auto Loader のように動作します。
- 削除された列 : 自動スキーマ進化が有効になっている場合、Auto Loader のように動作します。
- 型の拡張 : 自動スキーマ進化が有効になっている場合、Auto Loader のように動作します。
- その他のタイプの変更 : 自動スキーマ進化が有効になっている場合、Auto Loader のように動作します。
from_avroおよびfrom_protobufパーサー
from_avroパーサーとfrom_protobufパーサーは同じように動作します。スキーマはConfluent スキーマ レジストリから取得できます。また、ユーザーがスキーマを提供して、スキーマを手動で更新することもできます。from_avroまたはfrom_protobuf関数内にはスキーマ進化の概念がないため、実行エンジンとスキーマ レジストリによって処理する必要があります。
- 新しい列 : Confluent Schema Registry でサポートされます。それ以外の場合、ユーザーはスキーマを手動で更新する必要があります。
- 列名の変更 : Confluent Schema Registry でサポートされています。それ以外の場合、ユーザーはスキーマを手動で更新する必要があります。
- 削除された列 : Confluent Schema Registry でサポートされています。それ以外の場合、ユーザーはスキーマを手動で更新する必要があります。
- 型の拡張 : Confluent Schema Registry でサポートされています。それ以外の場合、ユーザーはスキーマを手動で更新する必要があります。
- その他のタイプの変更 : Confluent Schema Registry でサポートされています。それ以外の場合、ユーザーはスキーマを手動で更新する必要があります。
from_csvおよびfrom_xmlパーサー
from_csvおよびfrom_xmlパーサーはスキーマ進化をサポートしていません。
- 新しい列 : サポートされていません
- 列名の変更 : サポートされていません
- ドロップされた列 : サポートされていません
- 型拡張 : サポートされていません
- その他のタイプの変更 : サポートされていません
エンジンによるスキーマ進化のサポート
構造化ストリーミング
ストリーミング クエリのスキーマは計画フェーズでロックされ、すべてのマイクロバッチは再計画せずにその計画を再利用します。実行中にソース スキーマが変更された場合、クエリは失敗し、ユーザーはストリーミング クエリを再開して、Spark が新しいスキーマに対して再計画できるようにする必要があります。
ストリームが書き込むデータセットもスキーマ進化をサポートする必要があります。
- 新しい列 : サポートされています。クエリは失敗するため、スキーマの不一致を解決するにはストリームを再起動する必要があります。
- 列名の変更 : サポートされています。クエリは失敗するため、スキーマの不一致を解決するにはストリームを再起動する必要があります。
- ドロップされた列 : サポートされています。クエリは失敗するため、スキーマの不一致を解決するにはストリームを再起動する必要があります。
- 型の拡張 : サポートされています。クエリは失敗するため、スキーマの不一致を解決するにはストリームを再起動する必要があります。
- その他のタイプの変更 : サポートされています。クエリは失敗するため、スキーマの不一致を解決するにはストリームを再起動する必要があります。
データセットによるスキーマの進化
ストリーミングテーブル
デフォルトで、ストリーミングテーブルはマージスキーマ進化の挙動をサポートします。スキーマの更新には手動での再起動は必要ありませんが、任意のスキーマの変更には完全な更新が必要です。
- 新しい列 : サポートされています。スキーマの不一致を解決するために、クエリが自動的に再開されます。
- 列名の変更 : サポートされています。スキーマの不一致を解決するためにクエリが再開されます。名前を変更した列は、新しく追加された列として扱われます。
- ドロップされた列 : サポートされています。削除された列はソフト削除として扱われ、削除された列の新しい行は NULL に設定されます。
- 型の拡張 :サポートされています。型の拡張は、パイプラインレベルで、またはテーブルで直接有効にする必要があります。LakeFlow Pipelinesでの型の拡張については、こちらを参照してください。
- その他のタイプの変更 : サポートされていません。スキーマを更新するには完全な更新が必要です。
マテリアライズドビュー
スキーマまたは定義クエリを更新すると、マテリアライズドビューの完全な再計算がトリガーされます。
- 新しい列 : 完全な再計算がトリガーされました。
- 列の名前変更 : 完全な再計算がトリガーされました。
- 削除された列 : 完全な再計算がトリガーされました。
- 型の拡張 : 完全な再計算がトリガーされました。
- その他のタイプの変更 : 完全な再計算がトリガーされました。
Deltaテーブル
Deltaテーブルは、テーブル データを書き換えずに列の名前の変更、削除、列の種類の拡張など、テーブル スキーマを更新するためのさまざまな構成をサポートしています。 サポートされる構成には、マージ スキーマ進化、列マッピング、型拡張、およびoverwriteSchemaが含まれます。
- 新しい列 : サポートされています。マージ スキーマ進化が有効な場合、 Deltaテーブルの書き換えを必要とせずに自動進化します。 マージ スキーマ進化が有効になっていない場合、更新は失敗します。
- 列名の変更 : サポートされています。列マッピングを有効にして、手動の
ALTER TABLE DDLコマンドを使用して名前を変更できます。Delta テーブルの書き換えは必要ありません。 - ドロップされた列 : サポートされています。列マッピングが有効になっている手動の
ALTER TABLE DDLコマンドを使用して列を削除できます。Delta テーブルの書き換えは必要ありません。 - 型の拡張 : サポートされています。型の拡張とスキーマ進化のマージが有効な場合、型の変更を自動的に適用します。 型の拡張が有効になっている場合は、手動の
ALTER TABLE DDLコマンドを使用して列を拡張できます。どちらも設定されていない場合、操作は失敗します。自動スキーマ進化による型の拡張を参照してください。 - その他のタイプの変更 : サポートされていますが、 Deltaテーブルを完全に書き換える必要があります。 Deltaテーブルの完全な書き換えを有効にするには、
overwriteSchema有効にする必要があります。 そうでない場合、操作は失敗します。
ビュー
ビューに新しいスキーマと一致しないcolumn_listがある場合、または解析できないクエリがある場合、ビューは無効になります。そうでない場合は、 SCHEMA TYPE EVOLUTIONを使用して型の変更に対して行動進化を有効にし、 SCHEMA EVOLUTIONを使用して型の変更に加えて、新しい列、名前が変更された列、および削除された列に対して行動進化を有効にできます (これは型の進化のスーパーセットです)。
- 新しい列 : サポートされています。
SCHEMA EVOLUTIONモードでは、明示的なcolumn_listがない場合、ビューは手動による介入なしに自動的に進化します。そうしないと、ビューが無効になり、ユーザーがクエリを実行できなくなります。 - 列の名前変更 : サポートされています。
SCHEMA EVOLUTIONモードでは、明示的なcolumn_listがない場合、ビューは手動による介入なしに自動的に進化します。そうしないと、ビューが無効になる可能性があります。 - ドロップされた列 : サポートされています。
SCHEMA EVOLUTIONモードでは、明示的なcolumn_listがない場合、ビューは手動による介入なしに自動的に進化します。そうしないと、ビューが無効になる可能性があります。 - 型の拡張 : サポートされています。
SCHEMA TYPE EVOLUTIONモードでは、あらゆるタイプの変更に応じてビューが自動的に進化します。SCHEMA EVOLUTIONモードでは、明示的なcolumn_listがない場合、ビューは手動による介入なしに自動的に進化します。そうしないと、ビューが無効になる可能性があります。 - その他のタイプの変更 : サポートされています。
SCHEMA TYPE EVOLUTIONモードでは、あらゆるタイプの変更に応じてビューが自動的に進化します。SCHEMA EVOLUTIONモードでは、明示的なcolumn_listがない場合、ビューは手動による介入なしに自動的に進化します。そうしないと、ビューが無効になる可能性があります。
例
次の例は、Confluent Schema Registry に登録された Avro エンコードされたペイロードを含むKafkaトピックを取り込み、それらを azure 進化 が有効になっている管理対象Deltaテーブルに書き込む方法を示しています。
示された重要なポイント:
- Kafka コネクタと統合します。
- Kafka スキーマ レジストリで from_avro を使用して Avro レコードをデコードします。
avroSchemaEvolutionModeを設定してスキーマ進化を処理します。- 追加的な変更を可能にするために、
mergeSchemaを有効にして Delta テーブルに書き込みます。
このコードでは、Confluent スキーマ レジストリを使用して Avro でエンコードされたデータを出力する Kafka トピックがあることを前提としています。
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)