データ分類
このページでは、Unity Catalog の Databricks データ分類 を使用して、カタログ内の機密データを自動的に分類およびタグ付けする方法について説明します。
データカタログには膨大な量のデータが含まれる可能性があり、多くの場合、既知および未知の機密データが含まれます。 データ チームにとって、各テーブルにどのような種類の機密データが存在するかを理解し、そのデータへのアクセスを管理および民主化することが重要です。
この問題を解決するために、Databricksのデータ分類機能はAIエージェントを使用して、カタログ内のテーブルを自動的に分類およびタグ付けします。これにより、 Unity Catalog の属性ベースのアクセス制御などのツールを使用して、機密データを検出し、結果に対してガバナンス制御を適用することができます。サポートされているタグの一覧については、 「サポートされている分類タグ」を参照してください。
この機能を使用すると、次のことができます。
- データの分類 : エンジンはエージェント AI システムを使用して、Unity Catalog 内の任意のテーブルを自動的に分類し、タグ付けします。
- インテリジェント スキャンによるコストの最適化 : システムは、Unity Catalog と Data Intelligence Engine を活用して、データをスキャンするタイミングをインテリジェントに決定します。つまり、スキャンは増分的に行われ、手動で構成しなくてもすべての新しいデータが分類されるように最適化されます。
- 機密データの確認と保護 : 結果表示では、分類結果を表示し、各クラスにタグを付け、アクセス制御ポリシーを作成することで機密データを保護できます。
Databricks データ分類では、分類結果を保存するためにデフォルトのストレージを使用します。ストレージに対して料金は請求されません。
Databricks データ分類では、分類を支援するために大規模言語モデル (LLM) を使用します。
必要条件
- ワークスペースでは、サーバレスコンピュートが利用可能である必要があります (ワークスペースでUnity Catalog使用することで有効になります)。
- データ分類を有効にするには、カタログを所有しているか、カタログに対する
USE CATALOGおよびMANAGE権限を持っている必要があります。 - カタログの自動タグを有効にするには、カタログに
USE CATALOG、カタログにAPPLY TAG、適用するタグにASSIGNが必要です。 - UIで分類結果を表示するには、カタログに
USE CATALOGとMANAGEまたは(SELECT+USE SCHEMA)のいずれかが必要です。検出に関連付けられたサンプル値を表示するには、結果システムテーブルにSELECTが必要です。
もちろん、データ分類システム管理タグに対するMANAGEおよびASSIGN権限を持つのはアカウント管理者だけです。 アカウント管理者は、個別の管理タグのMANAGEとASSIGN他のユーザー、サービスプリンシパル、またはグループに付与できます。 「管理タグの権限の管理」を参照してください。
データ分類を使用する
結果ページから複数のカタログに対して一度にデータ分類を有効にすることも、個々のカタログに対してより詳細なスキーマレベルの制御を設定することもできます。
複数のカタログを有効にする
- データ分類結果ページで、 [設定] をクリックします。
- 有効にするカタログを選択するか、ワークスペースで使用可能なすべてのカタログを選択してください。
- [ 有効にする ]をクリックします。
利用可能なすべてのカタログを有効にしても、将来のカタログが自動的に有効になるわけではありません。新しいカタログを分類するには、 設定 ダイアログに戻って有効にします。
スキーマ選択で単一カタログを有効にする
カタログ内の特定のスキーマを選択するには:
-
カタログに移動し、 [詳細] タブをクリックします。
![カタログエクスプローラ のカタログページの [Details] タブ。](/aws/ja/assets/images/data-classification-details-tab-d8cf3e2ec2825893f62683cc0337b007.png)
-
データ分類の 横にある 「有効にする」 ボタンをクリックします。
-
データ分類 ダイアログが表示されます。デフォルトでは、すべてのスキーマが含まれます。一部のスキーマのみを含めるには、 「含めるスキーマ」 ドロップダウンメニューでそれらを選択してください。 使用ポリシー を選択することもできます
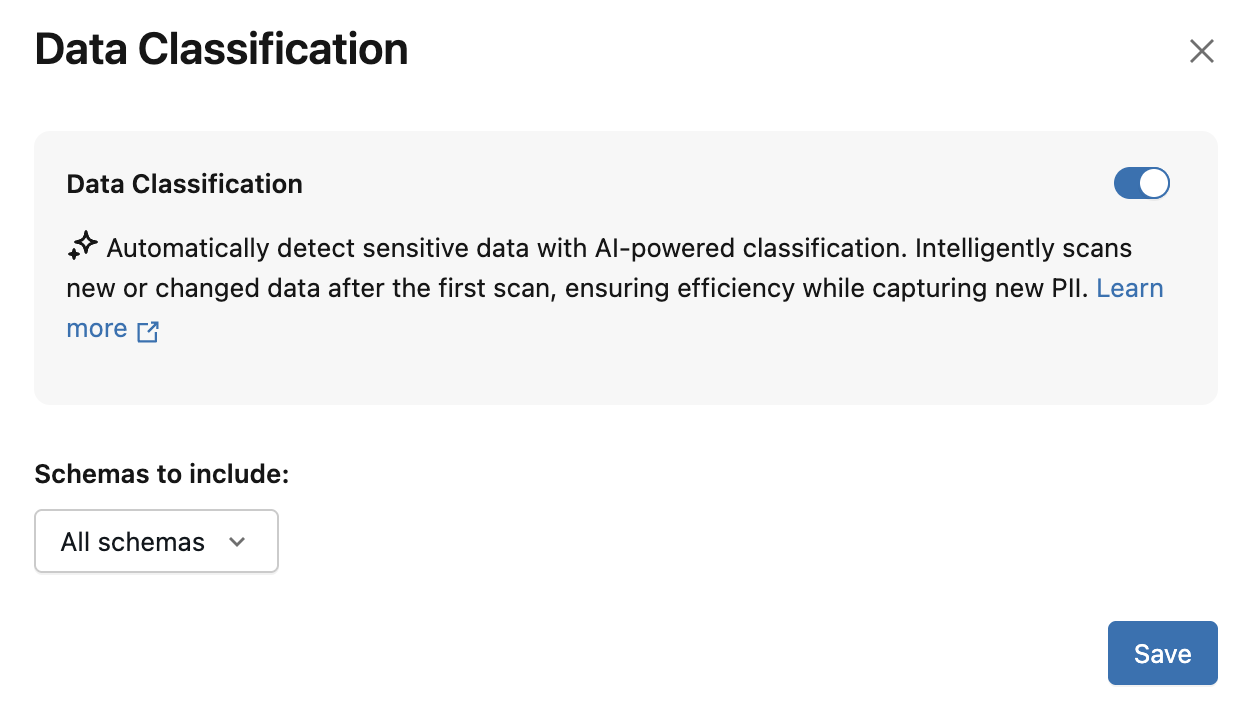
-
保存 をクリックします。
これにより、カタログまたは選択したスキーマ内のすべてのテーブルを増分スキャンするバックグラウンドジョブが作成されます。
分類エンジンは、インテリジェント スキャンを利用して、テーブルをスキャンするタイミングを決定します。通常、カタログ内の新しいテーブルと列は作成後 24 時間以内にスキャンされます。
分類結果の表示
分類結果を表示するには、 「データ分類」 設定の横にある 「結果を表示」 をクリックします。
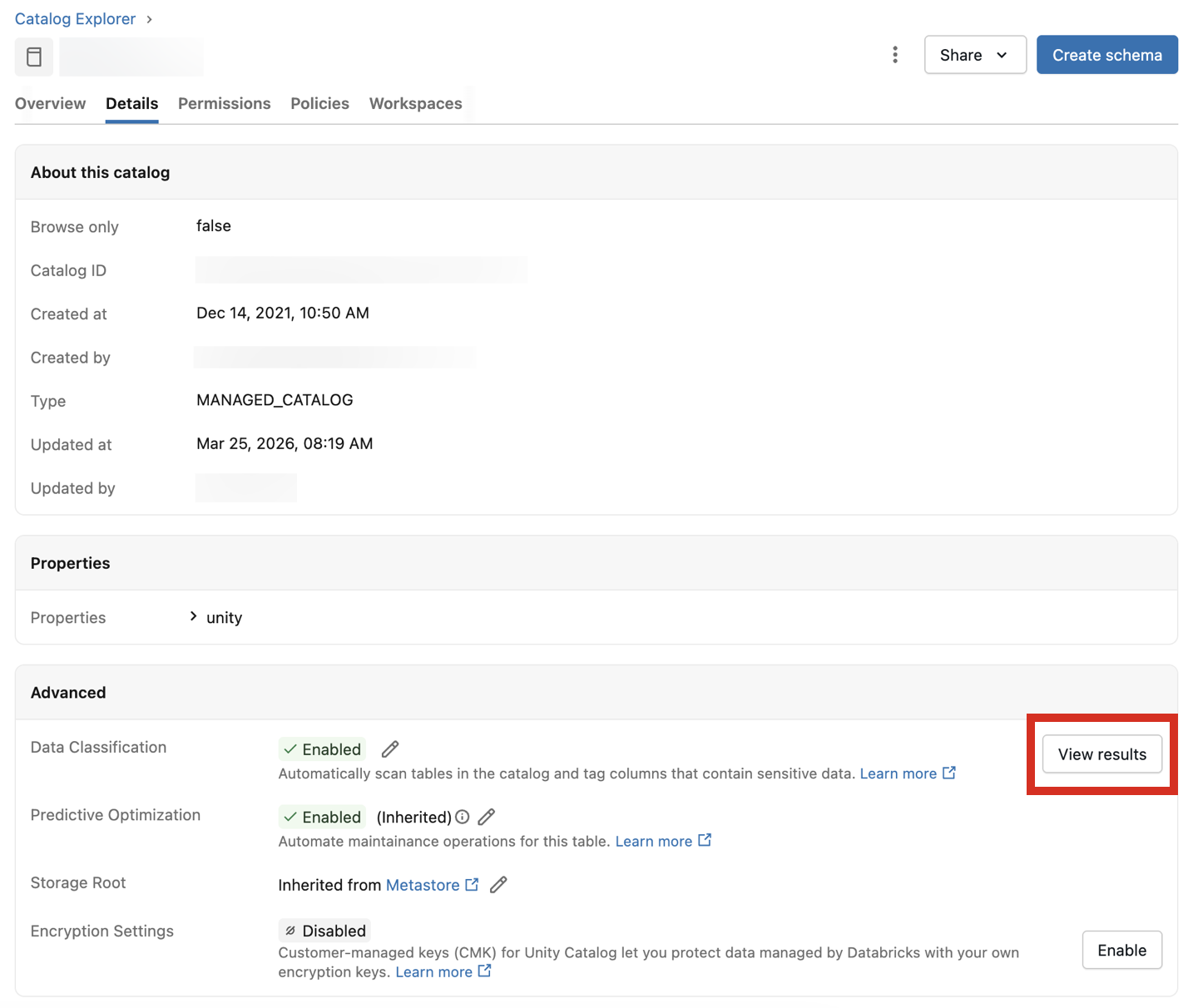
これにより、カタログのデータ分類 UI が開きます。 分類結果を表示するには、サーバレスSQLウェアハウスが必要です。
左上にあるカタログセレクターを使用すると、メタストア内のすべての分類済みカタログにわたる集計結果を表示することもできます。ドロップダウンメニューから 「すべてのカタログ」 を選択してください。
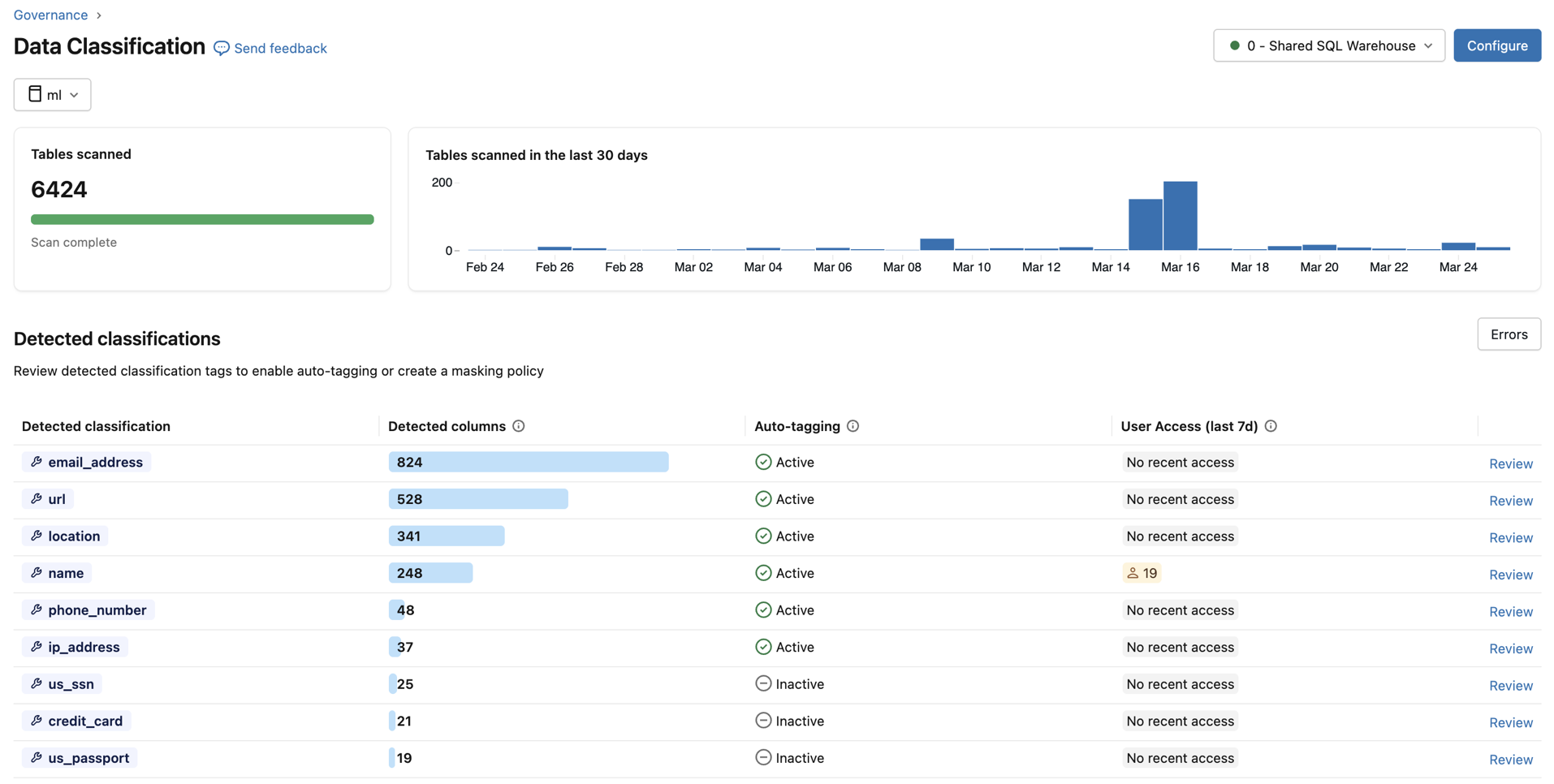
各分類タイプについて、表には以下が示されています。
- 検出された列数 :分類が検出された列の数。
- 自動タグ付け :その分類のタグ付けステータス - アクティブ または 非アクティブ 。メタストアビューにおいて、 「部分的に有効」 というステータスは、タグ付けが一部のカタログでは有効になっているものの、すべてのカタログで有効になっているわけではないことを示します。
- ユーザーアクセス(過去7日間) :過去7日間に、その分類の非マスクデータとマスクデータにアクセスした異なるユーザーの数。これを使用して、組織全体における機密データの漏洩状況を評価してください。
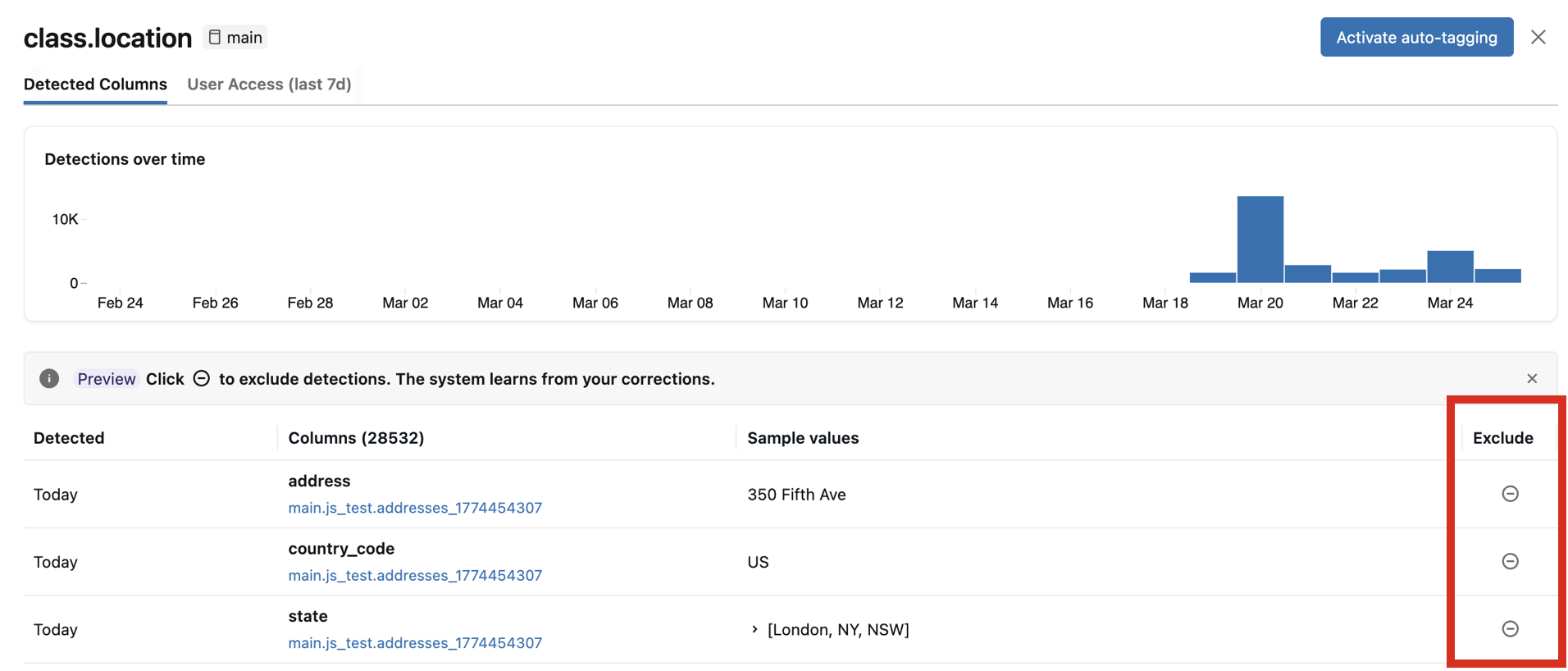
検出結果を確認する
特定の分類タイプの結果を確認するには、一番右の列にある 「確認」 をクリックしてください。2つのタブが表示されたパネルが表示されます。
- 検出された列 :分類タグが高信頼度で検出された列を、最新の検出順で表示します。また、 検出件数の推移を示す グラフと、検出された列とそのサンプル値の一覧も含まれています。グラフ内のいずれかの棒をクリックすると、その日付の具体的な検出結果が表示されます。サンプル値は、分類結果を表示するために必要な権限を持っている場合にのみ表示されます。
- ユーザーアクセス :この分類タグが付いた列にアクセスしたすべてのユーザーを一覧表示し、ユーザーのメールアドレスとユーザー名、およびマスクされたアクセス権限かマスクされていないアクセス権限かを示します。 また、この分類タグに割り当てられている属性ベースアクセス制御(ABAC)ポリシーも表示されます。単一カタログの結果を表示している場合、新しいABACを作成できます パネルから直接作成できます。
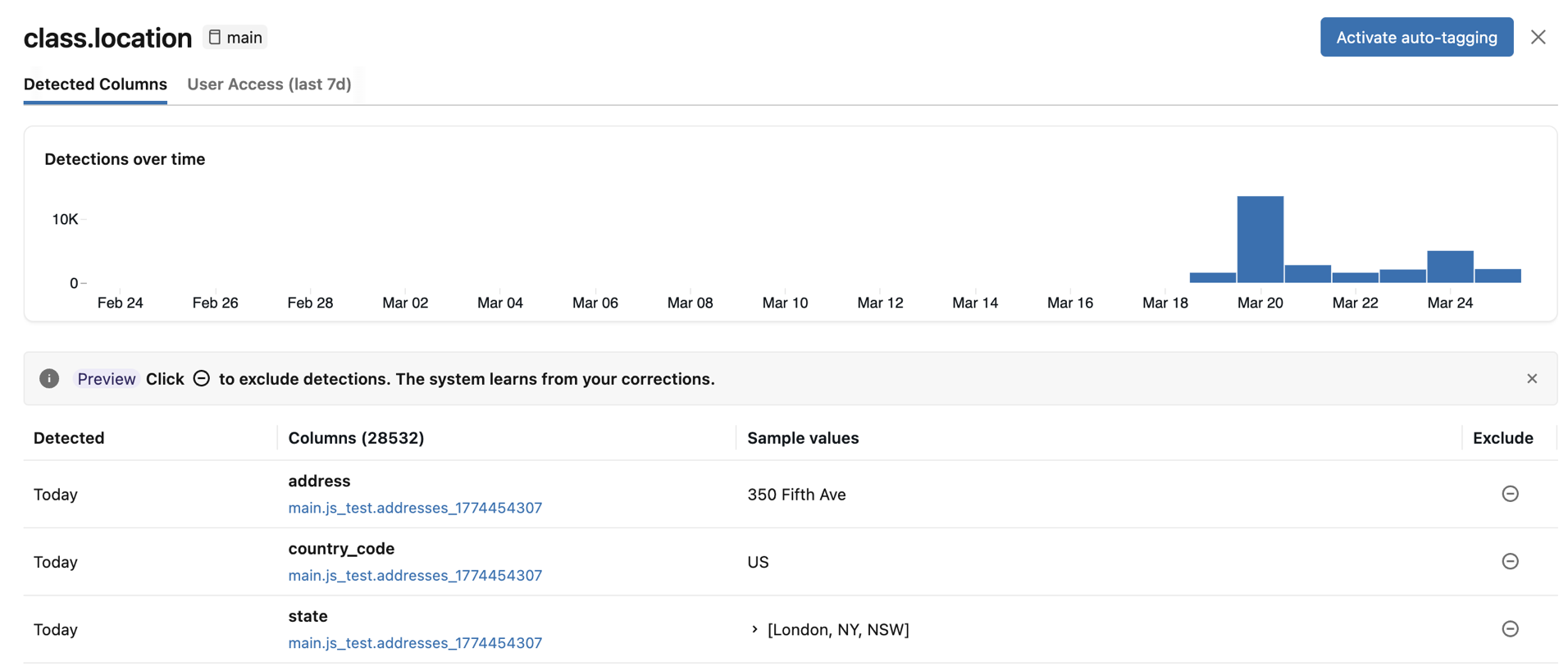
検出された列に誤りがある場合は、該当項目の右側にある 除外 アイコンをクリックしてください。検出対象を除外するを参照してください。
自動タグ付けを有効にする
特定された列が期待どおりであれば、分類タグの自動タグ付けを有効にすることができます。 自動タグが有効になっている場合、この分類の既存および今後の検出はすべてタグになります。
自動タグ付けは2つのレベルで設定できます。
- メタストアレベル :すべてのカタログに対して一度に有効または無効にします。メタストア管理者である必要があり、適用するタグに
ASSIGN設定されている必要があります。 - カタログレベル :現在のカタログのみに対して有効または無効にします。カタログレベルの設定は、メタストアレベルの設定よりも優先されます。カタログには
USE CATALOGとAPPLY TAGが、適用するタグにはASSIGNなければなりません。
カタログレベルでは、自動タグ付けには3つの状態があります。
- デフォルト(継承) :カタログはメタストアレベルからタグ付け設定を継承します。
- 有効 :メタストアレベルの設定に関係なく、このカタログではタグ付けが明示的に有効になっています。
- 非アクティブ :メタストアレベルの設定に関係なく、このカタログではタグ付けが明示的に無効になっています。
タグを無効にすると、今後のタグは適用されませんが、既存のタグは削除されません。
自動タグを有効にすると、タグはすぐに埋め戻されません。 これらは次のスキャンで入力され、24 時間以内に有効になります。後続の分類は直ちにタグ付けされます。
検出対象を除外する
ベータ版
検出除外機能およびそれらを用いた将来の分類精度向上機能はベータ版です。
レビューパネルでは、個々の列の検出結果を除外できます。検出を除外する:
- その列から既存の分類タグをすべて削除します。
- 今後のスキャンでその列にタグが再適用されるのを防ぎます。
- 将来の分類結果の精度を向上させるフィードバックを提供する。
検出結果を除外するには、レビューパネルの該当する列の 「除外」 アイコンをクリックします。検出を再度有効にするには、アイコンをもう一度クリックしてください。
結果システムテーブル
データ分類は、アカウント管理者のみがアクセスできる結果を保存するために、 system.data_classification.resultsという名前のシステム テーブルを作成します。 アカウント管理者はこのテーブルを共有できます。このテーブルは、サーバレスコンピュートを使用する場合にのみアクセスできます。 このテーブルの詳細については、 「データ分類システムテーブル リファレンス」を参照してください。
結果テーブルsystem.data_classification.resultsには、メタストア全体のすべての分類結果が含まれており、各カタログのテーブルからのサンプル値も含まれています。このテーブルは、サンプル値を含むメタストア全体の分類結果を表示する権限を持つユーザーとのみ共有する必要があります。
このテーブルへのアクセス権がSELECTユーザーは、データ分類結果ページで検出結果に関連付けられたサンプル値も確認できます。
データ分類結果に基づいてガバナンス制御を設定する
ABAC ポリシーを使用して機密データをマスクする
Databricksは、データ分類結果に基づいてガバナンス制御を作成するために、 Unity Catalogの属性ベースのアクセス制御を使用することを推奨しています。
データ分類結果ページからポリシーを作成するには、分類タグの 「レビュー」 をクリックし、 「ユーザーアクセス」 タブを開いて 「新しいポリシー」 をクリックします。審査対象の分類タグが付いた列は、ポリシーフォームにあらかじめ入力されています。データをマスクするには、 Unity Catalogに登録されている任意のマスキング関数を指定し、 [保存] をクリックします。
また、 「いつ」列を 条件を満たす ように変更し、複数のタグを提供することで、複数の分類タグをカバーするポリシーを作成することもできます。
たとえば、名前、電子メール、または電話番号をマスクする「機密」というポリシーを作成するには、 満たす条件 をhas_tag("class.name") OR has_tag("class.email_address") OR has_tag("class.phone_number")に設定します。
GDPRの検出と削除
このノートブックの例では、データ分類を使用してGDPRコンプライアンスの削除を支援する方法を示しています。
データ分類ノートブックを使用した GDPR の検出と削除
間違ったタグの扱い方
分類が誤っている場合は、その検出結果を審査委員会から除外する。検出対象から除外すると、タグが削除され、再適用されなくなり、今後のスキャンの精度が向上します。検出対象を除外するを参照してください。
スキャンエラー
スキャン中にエラーが発生した場合は、結果テーブルの右上に 「エラー」 ボタンが表示されます。
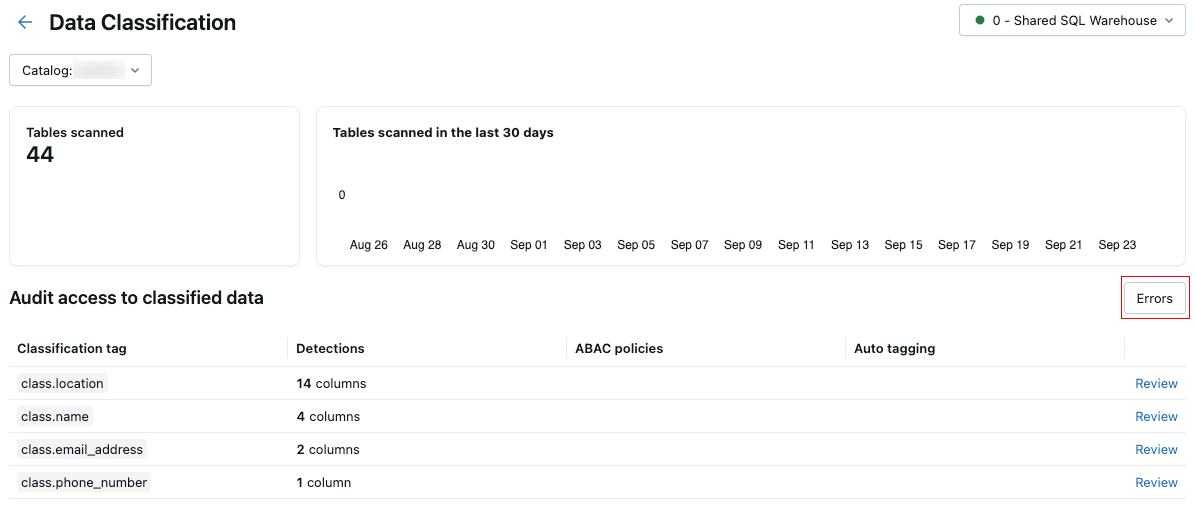
ボタンをクリックすると、スキャンに失敗したテーブルと関連するエラー メッセージが表示されます。

デフォルトでは、個々のテーブルで発生した障害はスキップされ、翌日に再試行されます。
データ分類の経費を表示する
データ分類の課金方法については、価格ページをご覧ください。 クエリを実行するか、使用状況ダッシュボードを表示することで、データ分類に関連する費用を表示できます。
最初のスキャンは増分スキャンであり、通常はコストが低くなるため、同じカタログの後続のスキャンよりもコストがかかります。
システムテーブルから使用状況を表示する system.billing.usage
system.billing.usageからデータ分類経費を照会できます。フィールドcreated_byとcatalog_idオプションで使用してコストを内訳できます。
created_by: 使用を開始したユーザー別のコストを確認する場合に含めます。catalog_id: カタログ別にコストを確認する場合に含めます。カタログ ID はsystem.data_classification.resultsテーブルに表示されます。
過去 30 日間のクエリの例:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
合計ドルコストを計算するには、 system.billing.list_pricesと結合します。次のクエリ例では、指定された価格:add_on_rateを定価の乗数として使用します。 定価を直接使用するには1に設定し、交渉された割引を反映するには1未満の値に設定します (たとえば、10% 割引の場合は0.9 )。
過去 30 日間の合計ドルコストのクエリ例:
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
使用状況ダッシュボードから使用状況を表示する
ワークスペースに使用状況ダッシュボードが既に構成されている場合は、それを使用して [データ分類] というラベルの付いた請求元プロジェクトを選択して使用状況をフィルター処理できます。使用状況ダッシュボードが構成されていない場合は、ダッシュボードをインポートして同じフィルタリングを適用できます。詳細については、「 使用状況ダッシュボード」を参照してください。
サポートされている分類タグ
グローバルタグ、リージョンタグ、およびコンプライアンスフレームワーク(PII、PCI DSS、GDPR、HIPPA、GLBA、DPDPA、PIPEDA)別に整理されたサポート対象のタグの完全なリストについては、サポートされている分類タグを参照してください。
制限事項
- ビューとメトリクス ビューはサポートされていません。 ビューが既存のテーブルに基づいている場合、Databricks では、基になるテーブルを分類して機密データが含まれているかどうかを確認することをお勧めします。