Lakeflow Designer でビジュアルデータ準備を作成する
Lakeflow Designer を使用すると、視覚的なドラッグ アンド ドロップ キャンバス上にデータ変換ワークフローを構築できます。 このページでは、データソースの追加や演算子の連結から、結果のプレビュー、 Unity Catalogへの書き込みまで、ビジュアルデータ準備の作成方法について説明します。
要件
Lakeflow Designer を使用するには、以下が必要です。
- Unity Catalog が有効になっている Databricks ワークスペース。
CAN USE少なくとも 1 つの汎用コンピュート リソース (サーバレスまたは汎用) に対する許可。
Designerの右上にある スケジュール ボタンの横にあるコンピュートピッカーから、使用するコンピュートを選択します。
新しいビジュアルデータ準備を作成する
新しいビジュアルデータ準備を作成するには、クリックします。![]() サイドバーの 「新規」 から 「ビジュアルデータ準備」 を選択します。
サイドバーの 「新規」 から 「ビジュアルデータ準備」 を選択します。
Designerを起動すると、ウェルカム画面が表示され、そこでデータソースを追加したり、サンプルとなるビジュアルデータ準備を確認したりできます。
データソースを追加する
すべてのビジュアルデータ準備は、1つ以上のデータソースから始まります。 ソース オペレーターは、キャンバス上のデータソースを表します。
データソースを追加するには:
- ソース演算子を追加します。ようこそ画面から、 [ソース オペレータの選択] をクリックします。キャンバスから演算子メニューを開き、 ソース を選択します。
- ソース構成ペインで、データを取り込む方法を選択します。既存のテーブルを参照したり、ローカルの CSV または Excel ファイルをアップロードしたり、ファイルからテーブルを作成したり、Google ドライブまたは SharePoint からインポートしたりできます。
- データソースを選択または設定します。 ソース演算子がキャンバスに表示されます。
CSV または Excel ファイルをキャンバスに直接ドラッグ アンド ドロップして、ソース演算子をすばやく作成することもできます。
後でソースを変更するには、ソース演算子を開いて、 「新しいデータソースの選択」 をクリックします。 ソースを変更すると、すべての下流演算子の出力キャッシュが無効になります。
各取り込みオプションの詳細については、 Lakeflow Designer へのデータの取り込み」を参照してください。
オペレーターの追加と設定
オペレーターを追加するには、キャンバスの左側にあるサイドペインでオペレーターメニューを開きます。演算子をクリックしてキャンバスに追加します、または、メニューから演算子をキャンバスにドラッグします。既存の演算子の横にある**+**ボタンをクリックして、自動接続で新しい演算子を追加することもできます。

オペレーターを設定するには、それをダブルクリックするか、ポインターをオペレーターの上に置いてクリックします。![]() ( 編集オペレーター )をクリックして、設定ペインを開きます。そのオペレータータイプのオプションを設定し、 [適用] をクリックします。
( 編集オペレーター )をクリックして、設定ペインを開きます。そのオペレータータイプのオプションを設定し、 [適用] をクリックします。
各オペレーターの詳細については、 「Lakeflow Designer の組み込みオペレーター」を参照してください。独自のユーザー定義演算子を作成する方法の詳細については、 「Lakeflow Designer のユーザー定義演算子」を参照してください。
オペレーターを接続する
2つの演算子を接続するには、出力ハンドル(演算子の右端にある小さな円)から入力ハンドル(次の演算子の左端にある小さな円)までクリックしてドラッグします。これは、データが最初の演算子から2番目の演算子へ流れることを指定するものです。データは、ビジュアルデータ準備プロセスにおいて左から右へと流れます。
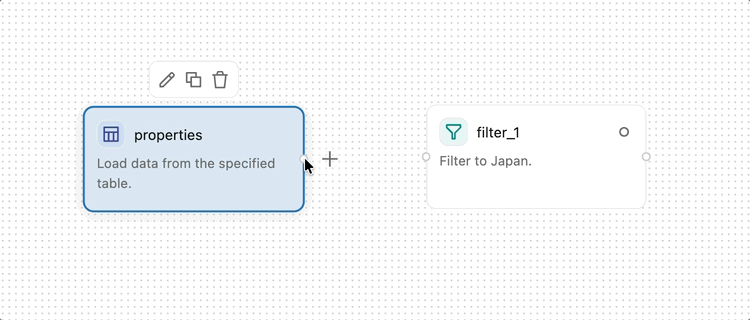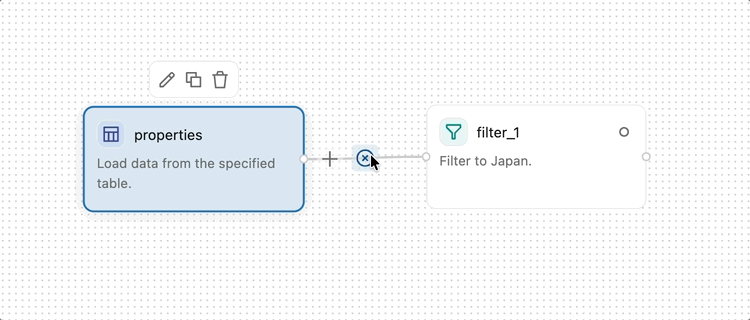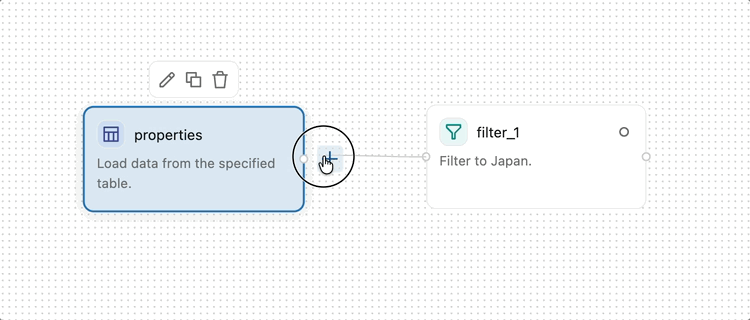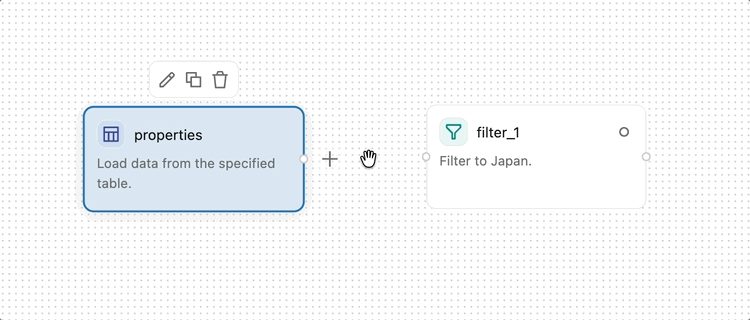
Join や Combine などの一部の演算子は複数の入力を受け入れます。
接続を削除するには、接続の上にポインターを置いて、接続の上に表示されるツールバーの ![]() をクリックします。
をクリックします。
Genie Codeを使用する
Lakeflow Designerで編集作業を行っている間はいつでも、Genie Codeへのプロンプトを作成して作業を補助することができます。See Genie Code.
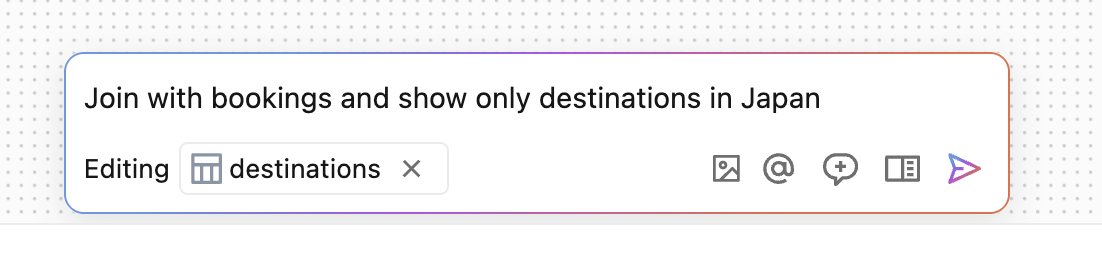
Genie Codeを使用する際、以下のボタンは追加機能を提供します。
 プロンプトの一部として使用する画像をアップロードします。
プロンプトの一部として使用する画像をアップロードします。 : プロンプトの一部として使用するテーブルやファイルなどのオブジェクトを指定する場合に使用します。
: プロンプトの一部として使用するテーブルやファイルなどのオブジェクトを指定する場合に使用します。 新しいエージェントコンテキストで新しいチャットスレッドを開始します。
新しいエージェントコンテキストで新しいチャットスレッドを開始します。 : 会話履歴のサイドペインを開き、エージェントが行っていることの詳細を表示します。
: 会話履歴のサイドペインを開き、エージェントが行っていることの詳細を表示します。
Genie Codeは、入力ボックスの上に最新の編集の1行の要約を表示します。
プレビュー結果
画面下部の出力ペインで結果を表示するには、任意の演算子を選択してください。ほとんどの演算子では、入力データは左側に、出力データは右側にあります。プロット、HTML、または画像など、表形式以外の結果を生成するオペレーターは、その出力を出力ペインに直接表示します。
出力ペインの表示コントロールを使用して、入力と出力(デフォルト)、入力のみ、または出力のみを切り替えます。結合ビューで、区切りをドラッグして入力ペインと出力ペインのサイズを変更します。
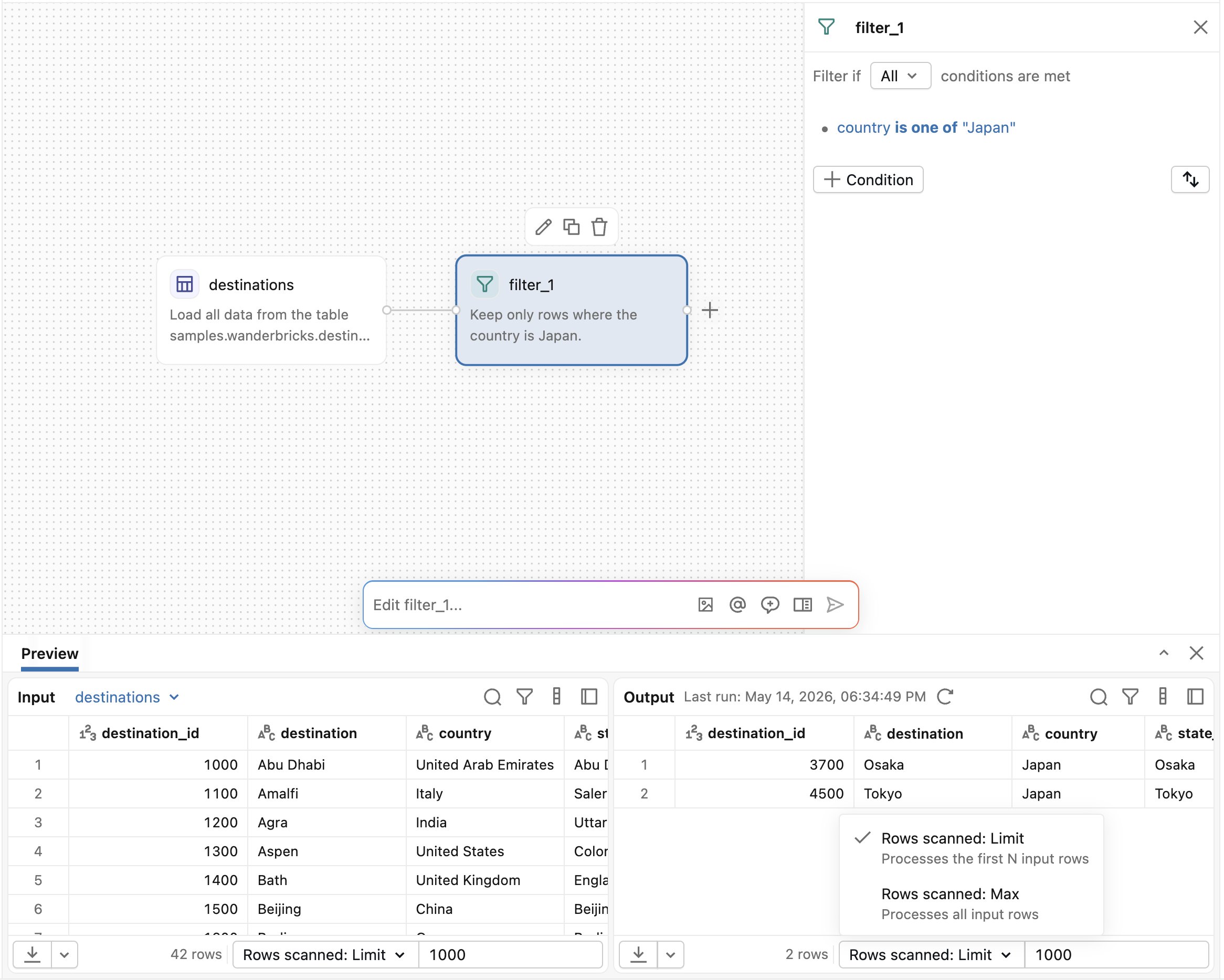
デフォルトでは、オペレーターはプレビュー用に限られたサンプルデータを処理します。出力ペインの Rows scanned ドロップダウンを使用して、処理する行数を制御します:
- スキャンされる行数:制限 :最初のN行の入力を処理します。ドロップダウンリストの横にある欄に、行数を指定してください。
- スキャンされた行数: 最大 : すべての入力行を処理します。
行 スキャンを実行しても、Max は 完全な無制限のデータセットを使用してすべての上流オペレーターを再実行するため、時間がかかる場合があります。
「 スキャンされた行 」設定は、プレビュー処理のみを制御します。スケジュールされた実行とジョブの実行は、常に完全なデータセットを処理します。
結果をUnity Catalogに書き込む
出力 オペレーターを追加して、結果を Unity Catalog のテーブルに書き込みます。
- 演算子メニューを開いて [出力] を選択するか、最後の演算子の横にある + を クリックして [出力] を選択します。
- まだ接続されていない場合は、最後の変換の出力ハンドルを出力 オペレータ の入力ハンドルに接続します。
- 出力 オペレーターをダブルクリックして、その構成ペインを開きます。
- テーブル名 を入力し、 出力場所 (カタログとスキーマ) を選択します。
- 実行 をクリックします。
各実行はマネージド出力テーブルを作成または置換するため、スケジュールされた実行は追加するのではなく上書きします。出力を参照してください。
本番運用でのスケジュールまたは実行
ワークフローをジョブとしてスケジュールすることで、自動化できます。
- 直接スケジュールする :上部メニューの 「スケジュール」 ボタンをクリックして、ビジュアルデータ準備のスケジュール済みジョブを作成します。
- ジョブに追加 : Databricksジョブを作成し、ビジュアル データの準備をタスクとして選択します。 これにより、視覚的なデータ準備作業を、より大規模なパイプライン内の他のタスクと組み合わせることが可能になります。
既存のスケジュールを表示および管理するには、もう一度 スケジュール をクリックしてリストを開きます。 スケジュールを追加 をクリックして別のものを作成するか、スケジュールの![]() ケバブメニューを開いて 編集 、 今すぐ実行 、 停止 、 複製 、 ジョブで表示 、または 削除 します。
ケバブメニューを開いて 編集 、 今すぐ実行 、 停止 、 複製 、 ジョブで表示 、または 削除 します。
ビジュアルデータの準備をスケジュールするとき、オプションでそのパラメーター値をそのスケジュールに対して上書きできます。たとえば、environmentパラメーターをtestに設定して実行するスケジュールを1つ作成し、productionに設定して実行する別のスケジュールを作成できます。See パラメーター.
ビジュアルデータ準備ファイルを保存および管理します
ビジュアルデータ準備ファイルはワークスペースにネイティブに保存されます。Gitフォルダ内に配置すると、それらをエクスポート、インポート、およびGitで追跡できます。
ビジュアルデータ準備ファイルをエクスポート
- 右上隅にある
 をクリックします。
をクリックします。 - 「 ファイル 」>「 エクスポート 」を選択します。
- ファイルは
<file_name>.designer.ipynbとしてエクスポートされます。
ビジュアルデータ準備ファイルをインポートします
- ワークスペースファイルシステムで、をクリックします。
- 「 インポート 」を選択します。
- インポートするビジュアルデータ準備ファイルを選択してください。
Git でビジュアル データ準備ファイルを使用する
- ワークスペースにGitフォルダを作成します。
- ビジュアルデータ準備ファイルをそのGitフォルダーに移動します。
- 他のノートブックと同様に、Git でファイルを追跡、コミット、バージョン管理します。
- Gitでは、ファイルは
<file_name>.designer.ipynbとして表示されます。
ビジュアルデータプレップの名前を変更する
ビジュアルデータプレップの名前を変更するには、エディタ上部でその名前が表示されているタブをクリックし、新しい名前を入力してください。
ビジュアルデータ準備を削除する
ビジュアルデータ準備を削除するには、ファイルの![]() ケバブメニューを開き、 ごみ箱に移動 を選択します。
ケバブメニューを開き、 ごみ箱に移動 を選択します。
複数のビジュアルデータ準備ファイルを一度に削除するには、左側のナビゲーションから**ワークスペース**を開き、削除するファイルを選択し、リストの上部にある**ゴミ箱に移動**を選択します。
キャンバスで作業する際の追加のヒント
キャンバス上では、ビジュアルデータの準備を編集するのに役立つ以下の操作が利用できます。
- オペレーターの名前を変更する :設定ペインの上部にあるテキストフィールドをクリックして、オペレーターの名前を変更します。分かりやすい名前を使うことで、視覚的なデータ準備が一目で理解しやすくなります。SQL演算子など、一部の演算子は、他の演算子の出力を名前で参照できます。
- 演算子をコピーする : 演算子の上にポインタを置いてクリックします
 、または演算子を選択して、 Cmd/Ctrl+C を押してから Cmd/Ctrl+V を 押します。
、または演算子を選択して、 Cmd/Ctrl+C を押してから Cmd/Ctrl+V を 押します。 - **演算子を削除する**:演算子の上にポインターを置いて、その上に表示されるツールバーの
 をクリックするか、演算子を選択して「**Delete**」を押します。
をクリックするか、演算子を選択して「**Delete**」を押します。 - 自動レイアウト :クリック
 ヘッダーツールバーで、すべての演算子をコンパクトなレイアウトに自動的に配置します。
ヘッダーツールバーで、すべての演算子をコンパクトなレイアウトに自動的に配置します。 - フィット表示 :クリック
 ヘッダーツールバーで、現在のビューポート内のすべての演算子を表示します。
ヘッダーツールバーで、現在のビューポート内のすべての演算子を表示します。 - 元に戻す/やり直し : Cmd/Ctrl+Z と Cmd/Ctrl+Shift+Z を押すか、ヘッダーツールバーの元に戻す/やり直しボタンを使用します。
- ` [生成されたコードを表示] `: Designerによって生成されたPySparkコードを表示するには、右ペインで` [バージョン履歴] `を開いて、ファイルをGitフォルダーにプッシュしてそこで表示するか、ジョブ実行の詳細でコードを表示します。
- バージョン履歴を表示:右ペインの
 をクリックして、ビジュアルデータ準備のバージョン履歴を開きます。そこに変更が一覧表示されます。以下のバージョンと比較するバージョンを選択してください。
をクリックして、ビジュアルデータ準備のバージョン履歴を開きます。そこに変更が一覧表示されます。以下のバージョンと比較するバージョンを選択してください。