宣言型自動化バンドルを使用してScala JARを構築する
この記事では、宣言型自動化バンドルを使用してScala JARを構築、デプロイ、実行する方法について説明します。バンドルに関する情報については、 「宣言型自動化バンドルとは?」を参照してください。
Java JAR をビルドして Unity Catalog にアップロードする構成の例については、「 JAR ファイルを Unity Catalog にアップロードするバンドル」を参照してください。
必要条件
このチュートリアルでは、Databricks ワークスペースが次の要件を満たしている必要があります。
- Unity Catalogが有効になっています。 「Unity Catalog のワークスペースを有効にする」を参照してください。
- ビルドを保存するDatabricksにUnity Catalogボリュームがあり、指定したボリュームパスにJARをアップロードする権限が必要です。「 Unity Catalog ボリュームの作成と管理」を参照してください。
- サーバレスコンピュートが有効になります。 サーバレス コンピュート機能の制限事項を必ず確認してください。
- ワークスペースはサポートされているリージョンにあります。
さらに、ローカル開発環境に以下がインストールされている必要があります。
- Java開発キット(JDK)17
- IntelliJ IDEA
- SBT
- Databricks CLI バージョン 0.218.0 以上。インストールされている Databricks CLI のバージョンを確認するには、コマンド
databricks -vを実行します。Databricks CLI をインストールするには、 「Databricks CLI のインストールまたは更新」を参照してください。 - Databricks CLI 認証は
DEFAULTプロファイルで構成されています。認証を構成するには、 「ワークスペースへのアクセスを構成する」を参照してください。
ステップ 1: バンドルを作成する
まず、 bundle init コマンド と Scala プロジェクトバンドルテンプレートを使用してバンドルを作成します。
Scala JARバンドル テンプレートは、 JARを構築するバンドルを作成し、それを指定されたボリュームにアップロードし、サーバーレス コンピュートで実行するJARを含むSparkタスクを含むジョブを定義します。 テンプレート プロジェクトの Scala は、サンプル DataFrame に単純な変換を適用し、結果を出力する UDF を定義します。テンプレートのソースは、bundle-examples リポジトリにあります。
-
ローカル開発マシンのターミナルウィンドウで次のコマンドを実行します。一部の必須フィールドの値を入力するように求められます。
Bashdatabricks bundle init default-scala -
プロジェクトの名前として、「
my_scala_project」と入力します。これにより、このバンドルのルートディレクトリの名前が決まります。このルートディレクトリは、現在の作業ディレクトリ内に作成されます。 -
ボリュームの作成先のパスには、バンドルのディレクトリを作成し、JARやその他のアーティファクトを格納するDatabricksにおけるUnity Catalogの ボリュームパスを指定します。 例えば、
/Volumes/my-catalog/my-schema/bundle-volumes。
テンプレート プロジェクトはサーバーレス コンピュートを構成しますが、クラシック コンピュートを使用するように変更する場合、管理者は指定したボリュームJARパスをホワイトリストに登録する必要がある場合があります。 標準アクセス モード (以前の共有アクセス モード) でのコンピュートに関する許可リスト ライブラリと init スクリプトを参照してください。
ステップ 2: VM オプションを構成する
-
build.sbtが配置されている IntelliJ の現在のディレクトリをインポートします。 -
IntelliJ で Java 17 を選択します。 [ファイル] > [プロジェクト構造] > [SDK] に移動します。
-
src/main/scala/com/examples/Main.scalaを開きます。 -
VM オプションを追加するには、メインの構成に移動します。
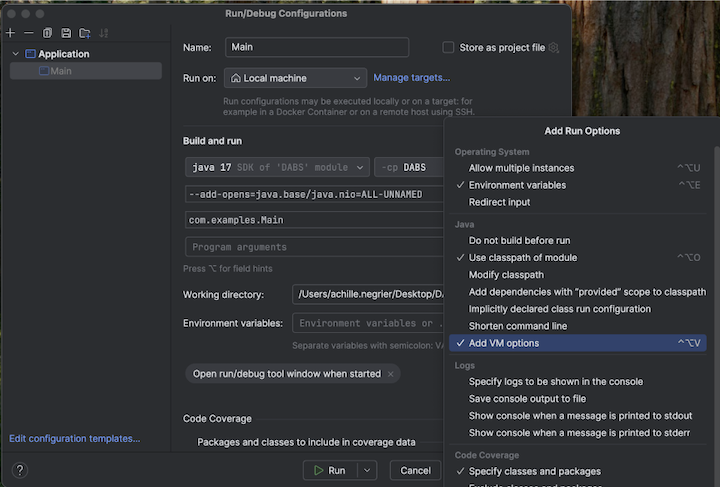
-
VM オプションに以下を追加します。
--add-opens=java.base/java.nio=ALL-UNNAMED
あるいは、Visual Studio Code を使用している場合は、次のコードを sbt ビルド ファイルに追加します。
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
次に、ターミナルからアプリケーションを実行します。
sbt run
ステップ 3: バンドルを探索する
テンプレートによって生成されたファイルを表示するには、新しく作成したバンドルのルート ディレクトリに切り替えて、このディレクトリを IDE で開きます。このテンプレートは、sbt を使用して Scala ファイルをコンパイルおよびパッケージ化し、ローカル開発のために Databricks Connect と連携します。詳細については、生成されたプロジェクトの README.md を参照してください。
特に興味深いファイルは次のとおりです。
databricks.yml: このファイルは、バンドルのプログラム名を指定し、ジョブ定義への参照を含め、ターゲット ワークスペースに関する設定を指定します。resources/my_scala_project.job.yml: このファイルは、ジョブの JAR タスクとクラスター設定を指定します。src/: このディレクトリには、Scala プロジェクトのソースファイルが含まれています。build.sbt: このファイルには、重要なビルド ライブラリと依存ライブラリの設定が含まれています。README.md: このファイルには、これらの開始手順と、ローカルのビルド手順と設定が含まれています。
ステップ 4: プロジェクトのバンドル構成ファイルを検証する
次に、 bundle validate コマンドを使用して、バンドル設定が有効かどうかを確認します。
-
ルート ディレクトリから、Databricks CLI
bundle validateコマンドを実行します。他のチェックの中でも、構成ファイルで指定されたボリュームがワークスペースに存在することを確認します。Bashdatabricks bundle validate -
バンドル構成のサマリーが返された場合、検証は成功しています。エラーが返された場合は、エラーを修正してから、この手順を繰り返します。
この手順の後にバンドルに変更を加えた場合は、この手順を繰り返して、バンドル構成がまだ有効かどうかを確認します。
ステップ 5: ローカル プロジェクトをリモート ワークスペースにデプロイする
次に、 bundle deploy コマンドを使用して、バンドルをリモートの Databricks ワークスペースにデプロイします。この手順では、JARファイルを作成し、指定したボリュームにアップロードします。
-
Databricks CLI
bundle deployコマンドを実行します。Bashdatabricks bundle deploy -t dev -
ローカルにビルドされた JAR ファイルがデプロイされたかどうかを確認するには、次のようにします。
- Databricks ワークスペースのサイドバーで、[ カタログ エクスプローラー ] をクリックします。
- バンドルの初期化時に指定したボリュームの宛先パスに移動します。JAR ファイルは、そのパス内の
/my_scala_project/dev/<user-name>/.internal/フォルダに配置する必要があります。
-
ジョブが作成されたかどうかを確認するには:
- Databricks ワークスペースのサイドバーで、[ ジョブとパイプライン] をクリックします。
- 必要に応じて、[ ジョブ ] と [自分が所有] フィルターを選択します。
- [dev
<your-username>]my_scala_projectをクリックします。 - 「タスク」 タブをクリックします。
タスクは 1 つ、 main_task つあるべきです。
この手順の後にバンドルに変更を加えた場合は、検証とデプロイの手順を繰り返します。
ステップ 6: デプロイされたプロジェクトを実行する
最後に、Databricksbundle run コマンドを使用してジョブを実行します。
-
ルートディレクトリから、 Databricks CLI
bundle runコマンドを実行し、定義ファイルmy_scala_project.job.ymlでジョブの名前を指定します。Bashdatabricks bundle run -t dev my_scala_project -
ターミナルに表示される
Run URLの値をコピーし、この値を Web ブラウザーに貼り付けて Databricks ワークスペースを開きます。 -
Databricks ワークスペースで、タスクが正常に完了し、緑色のタイトル バーが表示されたら、 main_task タスクをクリックして結果を確認します。