Azure DevOps を使用した Databricks での継続的インテグレーションとデリバリー
この記事では、サードパーティによって開発された Azure DevOps について説明します。プロバイダーに連絡するには、 Azure DevOpsサービス サポート 」を参照してください。
この記事では、Databricks と連携するようにAzure DevOpsを構成する方法について説明します。具体的には、 Gitリポジトリに接続する継続的インテグレーションとデリバリー ( CI/CD ) ワークフローを構成し、 Azureパイプラインを使用してジョブを実行してPython wheel (*.whl) を構築および単体テストし、 Databricksノートブックで使用できるようにデプロイします。
Databricks での CI/CD の概要については、Databricks における CI/CD を参照してください。ベストプラクティスについては、Databricks の CI/CD ワークフロー および Databricks の開発者向けベストプラクティスを参照してください。
例について
この記事の例では、2 つのパイプラインを使用して、リモート Git リポジトリに保存されているサンプル Python コードと Python ノートブックを収集、デプロイ、実行します。
ビルド パイプラインとして知られる最初のパイプラインは、 リリース パイプラインとして知られる 2 番目のパイプラインのビルド アーティファクトを準備します。 ビルド パイプラインをリリース パイプラインから分離すると、ビルド アーティファクトをデプロイせずに作成したり、複数のビルドからアーティファクトを同時にデプロイしたりすることができます。 ビルド パイプラインとリリース パイプラインを構築するには:
- ビルド パイプライン用の Azure 仮想マシンを作成します。
- Git リポジトリから仮想マシンにファイルをコピーします。
- Python コード、Python ノートブック、および関連するビルド、デプロイメント、実行設定ファイルを含む gzip 圧縮された tar ファイルを作成します。
- gzip 圧縮された tar ファイルを zip ファイルとして、リリース パイプラインがアクセスできる場所にコピーします。
- リリース パイプライン用に別の Azure 仮想マシンを作成します。
- ビルド パイプラインの場所から zip ファイルを取得し、zip ファイルを解凍して、Python コード、Python ノートブック、および関連するビルド、デプロイ、実行設定ファイルを取得します。
- Python コード、Python ノートブック、および関連するビルド、デプロイ、実行設定ファイルをリモート Databricks ワークスペースにデプロイします。
- Python wheelライブラリのコンポーネント コード ファイルをPython wheelファイルにビルドします。
- コンポーネント コードに対して単体テストを実行し、 Python wheelファイル内のロジックをチェックします。
- Pythonノートブックを実行します。そのうちの 1 つは、 Python wheelファイルの機能を呼び出します。
始める前に
この記事の例を使用するには、次のものが必要です。
- 既存のAzure DevOpsプロジェクト。まだプロジェクトがない場合は、 Azure DevOps でプロジェクトを作成します。
- Azure DevOps がサポートする Git プロバイダーを備えた既存のリポジトリ。このリポジトリに、Python サンプル コード、サンプル Python ノートブック、および関連するリリース設定ファイルを追加します。まだリポジトリがない場合は、Git プロバイダーの指示に従ってリポジトリを作成してください。次に、まだ行っていない場合は、Azure DevOps プロジェクトをこのリポジトリに接続します。手順については、 「サポートされているソース リポジトリ」のリンクに従ってください。
- この記事の例では、 OAuthマシン間 (M2M) 認証を使用して、 Microsoft Entra ID サービスプリンシパルをDatabricksワークスペースに対して認証します。 Microsoft Entra ID サービスプリンシパルと、そのサービスプリンシパルのDatabricks OAuthシークレットが必要です。 OAuthを使用したDatabricksへのサービスプリンシパル アクセスの承認」を参照してください。
ステップ 1: サンプルのファイルをリポジトリに追加します
このステップでは、サードパーティのGitプロバイダーを使用したリポジトリに、 Azure DevOpsパイプラインがリモートDatabricksワークスペースでビルド、デプロイ、実行するこの記事のサンプル ファイルをすべて追加します。
ステップ 1.1: Python wheelコンポーネントファイルを追加します
この記事の例では、 Azure DevOpsパイプラインでPython wheelファイルをビルドして単体テストします。 次に、 Databricksノートブックは、構築されたPython wheelファイルの機能を呼び出します。
ノートブック実行の対象となるPython wheelファイルのロジックと単体テストを定義するには、リポジトリのルートにaddcol.pyとtest_addcol.pyという名前の 2 つのファイルを作成し、それらをLibrariesフォルダー内のpython/dabdemo/dabdemoという名前のフォルダー構造に追加します。これは次のように視覚化できます。
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
addcol.pyファイルには、後でPython wheelファイルに構築され、 Databricksクラスターにインストールされるライブラリ関数が含まれています。 これは、リテラルが設定された新しい列を Apache Spark DataFrame に追加する単純な関数です。
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
test_addcol.pyファイルには、 addcol.pyで定義されたwith_status関数にモック DataFrame オブジェクトを渡すテストが含まれています。次に、結果は、予想される値を含む DataFrame オブジェクトと比較されます。値が一致する場合、テストは合格です。
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Databricks CLIこのライブラリ コードをPython wheelファイルに正しくパッケージ化できるようにするには、前の 2 つのファイルと同じフォルダーに__init__.pyと__main__.pyという名前の 2 つのファイルを作成します。 また、次のように視覚化されるpython/dabdemoフォルダーにsetup.pyという名前のファイルを作成します。
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
__init__.pyファイルには、ライブラリのバージョン番号と作成者が含まれています。<my-author-name>あなたの名前に置き換えてください:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
__main__.pyファイルにはライブラリのエントリ ポイントが含まれています:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
setup.pyファイルには、ライブラリをPython wheelファイルに構築するための追加設定が含まれています。 <my-url> 、 <my-author-name>@<my-organization> 、 <my-package-description>を有効な値に置き換えます。
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
ステップ 1.2: Python wheelファイルの単体テスト ノートブックを追加する
その後、Databricks CLI はノートブック ジョブを実行します。このジョブは、ファイル名がrun_unit_tests.pyの Python ノートブックを実行します。このノートブック実行pytestは、 Python wheelライブラリのロジックに対して実行されます。
この記事の例の単体テストを実行するには、次の内容を含むrun_unit_tests.pyという名前のノートブック ファイルをリポジトリのルートに追加します。
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
ステップ 1.3: Python wheelファイルを呼び出すノートブックを追加する
その後、Databricks CLI は別のノートブック ジョブを実行します。このノートブックはDataFrameオブジェクトを作成し、それをPython wheelライブラリのwith_status関数に渡し、結果を出力し、ジョブの実行結果を報告します。 リポジトリのルートに、次の内容を含むdabdemo_notebook.pyという名前のノートブック ファイルを作成します。
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
ステップ 1.4: バンドル構成を作成する
この記事の例では、宣言型自動化バンドルを使用して、 Python wheelファイル、2 つの、およびPythonコード ファイルの構築、デプロイ、および実行の設定と動作を定義します。 宣言的オートメーション バンドルを使用すると、完全なデータ分析とMLプロジェクトをソース ファイルのコレクションとして表現できます。 「宣言型自動化バンドルとは何か?」を参照してください。
この記事の例のバンドルを構成するには、リポジトリのルートにdatabricks.ymlという名前のファイルを作成します。この例のdatabricks.ymlファイルでは、次のプレースホルダーを置き換えます。
<bundle-name>バンドルの一意のプログラム名に置き換えます。たとえば、azure-devops-demo。- この例では、Databricks ワークスペースに作成されたジョブを一意に識別できるように、
<job-prefix-name>何らかの文字列に置き換えます。たとえば、azure-devops-demo。 <spark-version-id>を、ジョブ クラスターの Databricks Runtime バージョン ID (13.3.x-scala2.12など) に置き換えます。<cluster-node-type-id>ジョブ クラスターのクラスター ノード タイプ ID (例:i3.xlarge) に置き換えます。targetsマッピングのdevは、ホストと関連するデプロイメント動作を指定することに注意してください。実際の実装では、独自のバンドル内でこのターゲットに別の名前を付けることができます。
この例のdatabricks.ymlファイルの内容は次のとおりです。
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
targets:
dev:
mode: development
databricks.ymlファイルの構文の詳細については、 「宣言的オートメーション バンドルの構成」を参照してください。
ステップ 2: ビルド パイプラインを定義する
Azure DevOps は、YAML を使用して CI/CD パイプラインのステージを定義するためのクラウド ホスト ユーザー インターフェイスを提供します。Azure DevOpsとパイプラインの詳細については、 Azure DevOpsドキュメントを参照してください。
このステップでは、YAML マークアップを使用してビルド パイプラインを定義し、デプロイメント アーティファクトをビルドします。 コードをDatabricksワークスペースにデプロイするには、このパイプラインのビルド アーティファクトをリリース パイプラインへの入力として指定します。 このリリース パイプラインは後で定義します。
ビルド パイプラインを実行するために、Azure DevOps では、Kubernetes、VM、Azure Functions、Azure Web Apps などのさまざまなターゲットへのデプロイをサポートする、クラウドでホストされるオンデマンド実行エージェントが提供されます。この例では、オンデマンド エージェントを使用して、デプロイメント アーティファクトの構築を自動化します。
この記事のサンプルビルド パイプラインを次のように定義します。
- Azure DevOpsにサインインし、 [サインイン] リンクをクリックして Azure DevOps プロジェクトを開きます。
Azure DevOps プロジェクトの代わりに Azure Portal が表示される場合は、 [その他のサービス] > [Azure DevOps 組織] > [自分の Azure DevOps 組織] をクリックして、Azure DevOps プロジェクトを開きます。
-
サイドバーの 「パイプライン」 をクリックし、 「パイプライン」 メニューの 「パイプライン」を クリックします。
-
[ 新しいパイプライン] ボタンをクリックし、画面の指示に従います。(既にパイプラインがある場合は、代わりに 「パイプラインの作成」を クリックします。) これらの手順の最後に、パイプライン エディターが開きます。ここで、表示される
azure-pipelines.ymlファイルでビルド パイプライン スクリプトを定義します。手順の最後にパイプライン エディターが表示されない場合は、ビルド パイプラインの名前を選択し、 [編集] をクリックします。Gitブランチセレクターを使用することができます
 Git リポジトリ内の各ブランチのビルド プロセスをカスタマイズします。本番運用作業をリポジトリの
Git リポジトリ内の各ブランチのビルド プロセスをカスタマイズします。本番運用作業をリポジトリのmainブランチで直接実行しないことがCI/CDベスト プラクティスです。 この例では、リポジトリ内にmain代わりに使用されるreleaseという名前のブランチが存在することを前提としています。
azure-pipelines.ymlビルド パイプライン スクリプトは、パイプラインに関連付けられたリモート Git リポジトリのルートにデフォルトで保存されます。 -
パイプラインの
azure-pipelines.ymlファイルのスターター コンテンツを次の定義で上書きし、 [保存] をクリックします。YAML# Specify the trigger event to start the build pipeline.
# In this case, new code merged into the release branch initiates a new build.
trigger:
- release
# Specify the operating system for the agent that runs on the Azure virtual
# machine for the build pipeline (known as the build agent). The virtual
# machine image in this example uses the Ubuntu 22.04 virtual machine
# image in the Azure Pipeline agent pool. See
# https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software
pool:
vmImage: ubuntu-22.04
# Download the files from the designated branch in the remote Git repository
# onto the build agent.
steps:
- checkout: self
persistCredentials: true
clean: true
# Generate the deployment artifact. To do this, the build agent gathers
# all the new or updated code to be given to the release pipeline,
# including the sample Python code, the Python notebooks,
# the Python wheel library component files, and the related Databricks asset
# bundle settings.
# Use git diff to flag files that were added in the most recent Git merge.
# Then add the files to be used by the release pipeline.
# The implementation in your pipeline will likely be different.
# The objective here is to add all files intended for the current release.
- script: |
git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory)
mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo
cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo
cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo
cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory)
displayName: 'Get Changes'
# Create the deployment artifact and then publish it to the
# artifact repository.
- task: ArchiveFiles@2
inputs:
rootFolderOrFile: '$(Build.BinariesDirectory)'
includeRootFolder: false
archiveType: 'zip'
archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip'
replaceExistingArchive: true
- task: PublishBuildArtifacts@1
inputs:
ArtifactName: 'DatabricksBuild'
ステップ 3: リリースパイプラインを定義する
リリース パイプラインは、ビルド パイプラインからDatabricks環境にビルド アーティファクトをデプロイします。 このステップのリリース パイプラインを前のステップのビルド パイプラインから分離すると、デプロイせずにビルドを作成したり、複数のビルドからアーティファクトを同時にデプロイしたりできます。
-
Azure DevOps プロジェクトのサイドバーにある [ パイプライン] メニューで、 [リリース] をクリックします。
-
[新規] > [新しいリリース パイプライン] をクリックします。(既にパイプラインがある場合は、代わりに [新しいパイプライン] をクリックします。)
-
画面の横には、一般的なデプロイメント パターンのおすすめテンプレートのリストが表示されます。このリリースパイプラインの例では、
 。
。
-
画面の横にある 「アーティファクト」 ボックスで、
 。 [アーティファクトの追加] ペインの [ソース (ビルド パイプライン)] で、前に作成したビルド パイプラインを選択します。 次に、 「追加」 をクリックします。
。 [アーティファクトの追加] ペインの [ソース (ビルド パイプライン)] で、前に作成したビルド パイプラインを選択します。 次に、 「追加」 をクリックします。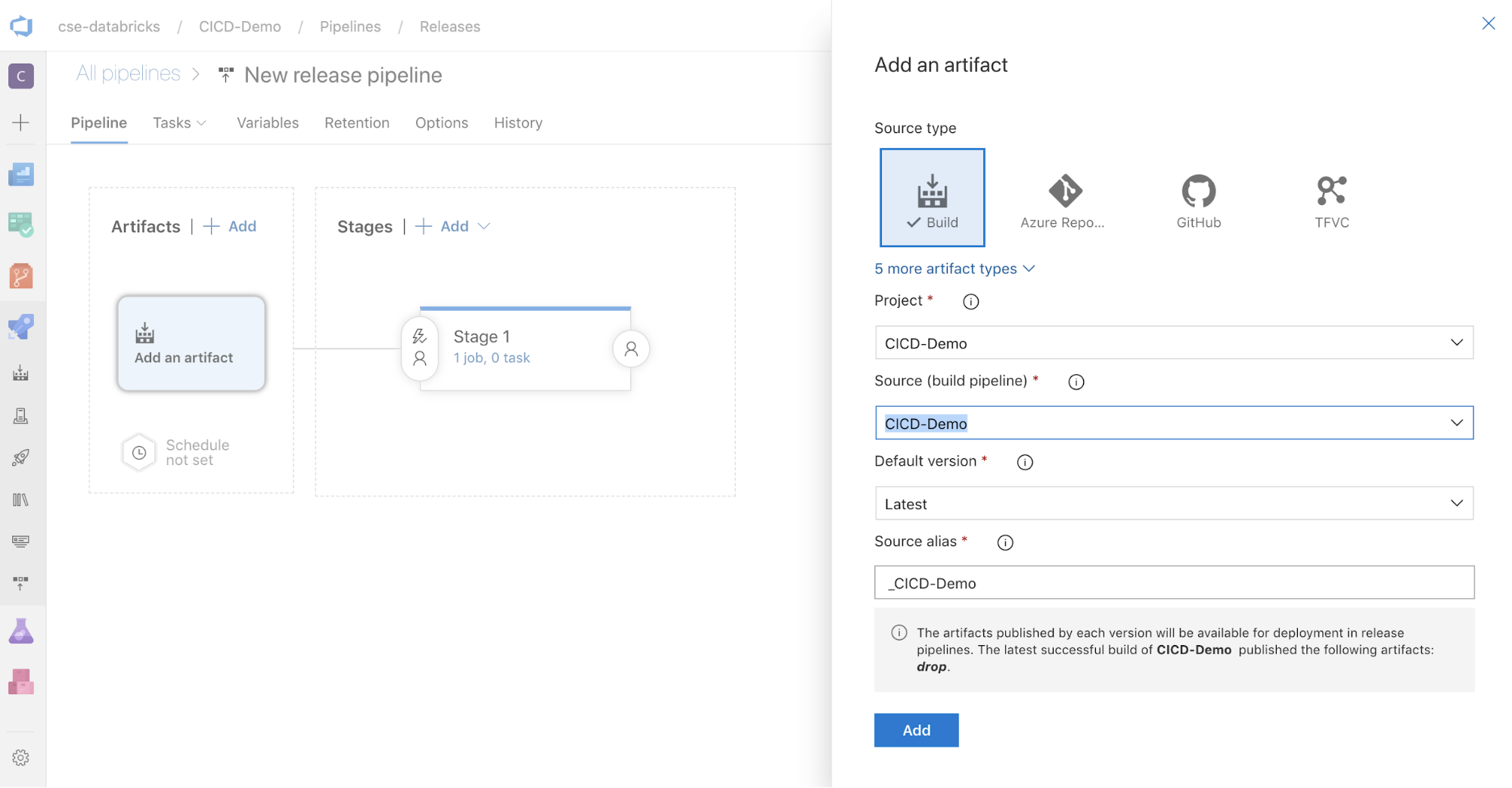
-
パイプラインのトリガー方法を設定するには、
 画面の横にトリガー オプションを表示します。ビルド アーティファクトの可用性に基づいて、またはプル リクエストのワークフロー後にリリースを自動的に開始したい場合は、適切なトリガーを有効にします。 現時点では、この例では、この記事の最後のステップで、ビルド パイプラインを手動でトリガーし、次にリリース パイプラインをトリガーします。
画面の横にトリガー オプションを表示します。ビルド アーティファクトの可用性に基づいて、またはプル リクエストのワークフロー後にリリースを自動的に開始したい場合は、適切なトリガーを有効にします。 現時点では、この例では、この記事の最後のステップで、ビルド パイプラインを手動でトリガーし、次にリリース パイプラインをトリガーします。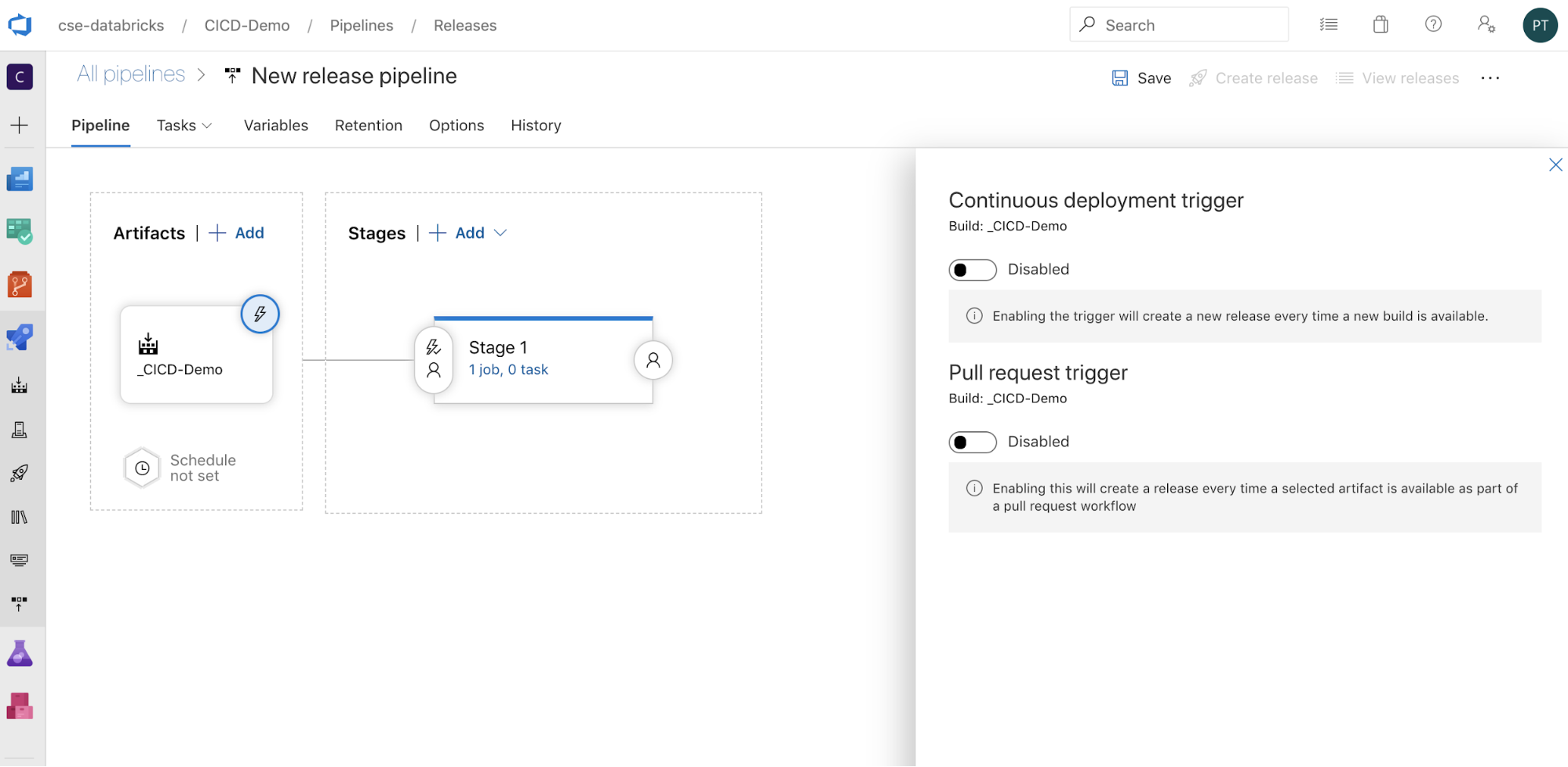
-
[保存] > [OK] をクリックします。
ステップ 3.1: リリースパイプラインの環境変数を定義する
この例のリリース パイプラインは、次の環境変数に依存しています。これは、[ 変数] タブの [パイプライン変数] セクションで [追加] を クリックして追加できます。 スコープ は ステージ 1 です。
BUNDLE_TARGETこれは、databricks.ymlファイル内のtarget名前と一致する必要があります。この記事の例では、これはdevです。DATABRICKS_HOSTこれは、https://で始まる、Databricks ワークスペースのワークスペースごとの URLを表します (例:https://adb-<workspace-id>.<random-number>.azuredatabricks.net)。.net後に末尾の/を含めないでください。DATABRICKS_CLIENT_IDこれは、 Microsoft Entra ID サービスプリンシパルのアプリケーション ID を表します。DATABRICKS_CLIENT_SECRETこれは、 Microsoft Entra ID サービスプリンシパルのDatabricks OAuthシークレットを表します。
ステップ 3.2: 離型パイプラインの離型剤を設定する
-
ステージ 1 オブジェクト内の 1 ジョブ、0 タスク リンクをクリックします。
-
[タスク] タブで、 [エージェント ジョブ] をクリックします。
-
[エージェントの選択] セクションの [エージェント プール] で、 Azureパイプライン] を選択します。
-
[エージェント仕様] では、先ほどビルド エージェントに指定したのと同じエージェント (この例では ubuntu-22.04) を選択します。
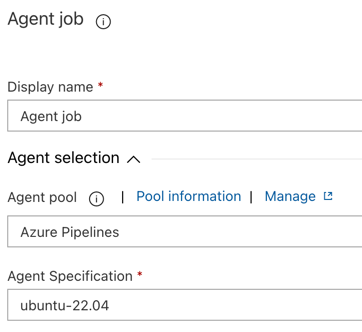
-
[保存] > [OK] をクリックします。
ステップ 3.3: リリース エージェントのPythonバージョンを設定する
-
次の図の赤い矢印で示されている、 エージェント ジョブ セクションのプラス記号をクリックします。利用可能なタスクの検索可能なリストが表示されます。標準の Azure DevOps タスクを補完するために使用できるサードパーティ プラグイン用の Marketplace タブもあります。次の数ステップの間に、離型剤にいくつかのタスクを追加します。
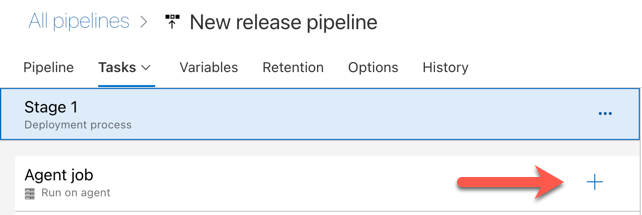
-
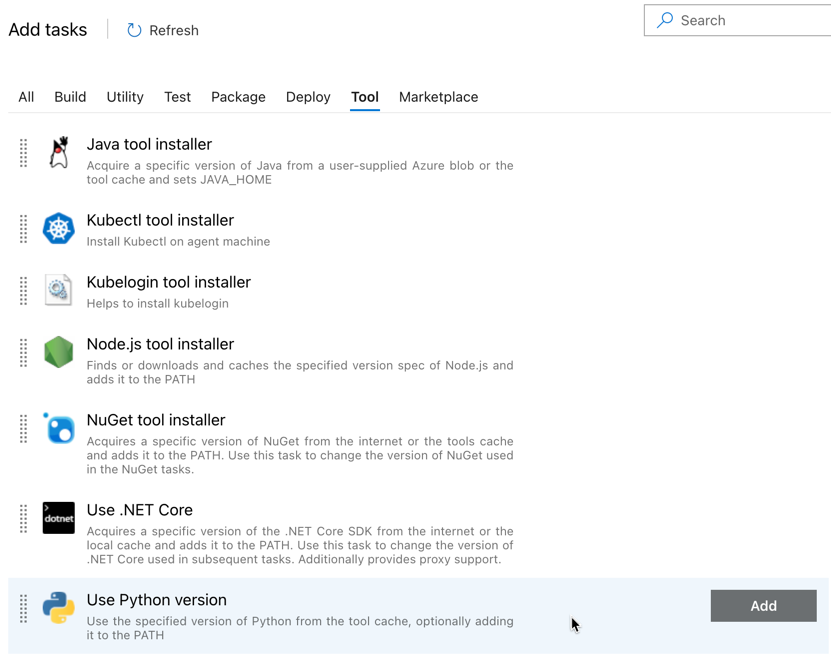
最初に追加するタスクは、 [ツール] タブにある [Python バージョンの使用] です。このタスクが見つからない場合は、 検索 ボックスを使用して検索してください。見つかったら、それを選択して、 「Python バージョンの使用」 タスクの横にある [追加] ボタンをクリックします。
-
ビルド パイプラインと同様に、Python のバージョンが後続のタスクで呼び出されるスクリプトと互換性があることを確認する必要があります。この場合は、 エージェントジョブ の横にある 「Python 3.x を使用する 」タスクをクリックし、 バージョン仕様 を
3.10に設定します。また、 表示名 をUse Python 3.10に設定します。このパイプラインでは、Python 3.10.12 がインストールされているクラスターで Databricks Runtime 13.3 LTS を使用していることを前提としています。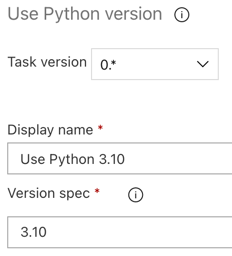
-
[保存] > [OK] をクリックします。
ステップ 3.4: ビルド パイプラインからビルド アーティファクトをパッケージ解除します。
-
次に、リリース エージェントに、[ファイルの抽出] タスクを使用して、zip ファイルからPython wheelファイル、関連する リリース 設定ファイル、ノートブック、およびPythonコード ファイルを抽出させます。 [エージェント ジョブ] セクションのプラス記号をクリックし、[ ユーティリティ ] タブで [ファイルの抽出 ] タスクを選択し、 [追加] をクリックします。
-
エージェント ジョブ の横にある ファイルの抽出 タスクをクリックし、 アーカイブ ファイル パターンを
**/*.zipに設定し、 宛先フォルダーを システム変数$(Release.PrimaryArtifactSourceAlias)/Databricksに設定します。また、 表示名 をExtract build pipeline artifactに設定します。
$(Release.PrimaryArtifactSourceAlias) は、リリース エージェント上のプライマリ アーティファクト ソースの場所を識別するためにAzure DevOps で生成されたエイリアスを表します (例: _<your-github-alias>.<your-github-repo-name> )。 リリース パイプラインは、リリース エージェントの ジョブ初期化 フェーズでこの値を環境変数RELEASE_PRIMARYARTIFACTSOURCEALIASとして設定します。「クラシック リリースとアーティファクト変数」を参照してください。
-
表示名を
Extract build pipeline artifactに設定します。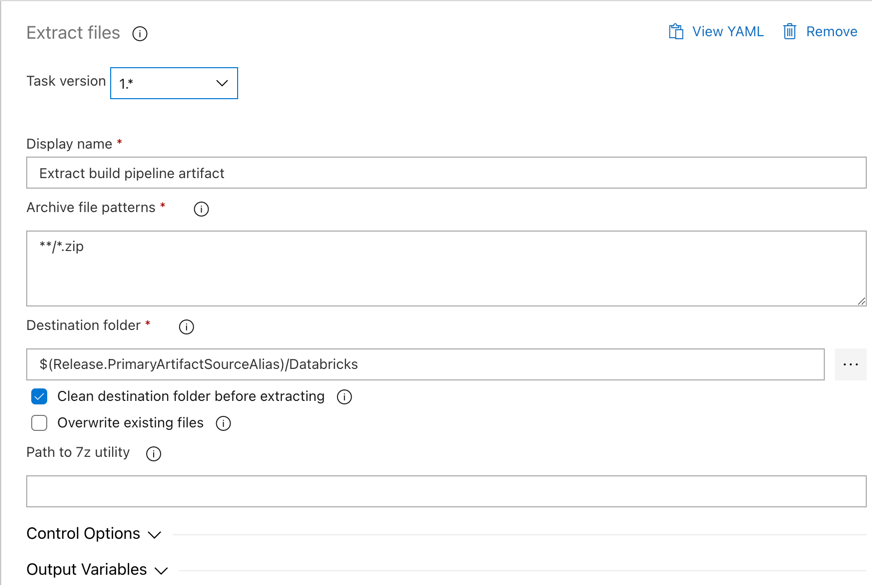
-
[保存] > [OK] をクリックします。
ステップ 3.5: BUNDLE_ROOT 環境変数を設定する
この記事の例が期待どおりに動作するためには、リリースパイプラインでBUNDLE_ROOTという名前の環境変数を設定する必要があります。Declarative Automation Bundles はこの環境変数を使用して、 databricks.ymlファイルの場所を特定します。この環境変数を設定するには:
- 環境変数 タスクを使用します。 エージェント ジョブ セクションでもう一度プラス記号をクリックし、 ユーティリティ タブで 環境変数 タスクを選択して、 追加 をクリックします。
環境変数 タスクが ユーティリティ タブに表示されない場合は、 検索 ボックスにEnvironment Variablesと入力し、画面の指示に従ってタスクを ユーティリティ タブに追加します。この場合、Azure DevOps を終了して、中断した場所に戻る必要がある場合があります。
- 環境変数 (カンマ区切り) には、次の定義を入力します:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks。
$(Agent.ReleaseDirectory) リリース エージェント上のリリース ディレクトリの場所を識別するための、Azure DevOps によって生成されたエイリアスを表します (例: /home/vsts/work/r1/a )。リリース パイプラインは、リリース エージェントの ジョブ初期化 フェーズでこの値を環境変数AGENT_RELEASEDIRECTORYとして設定します。「クラシック リリースとアーティファクト変数」を参照してください。 $(Release.PrimaryArtifactSourceAlias)に関する情報については、前のステップの注を参照してください。
-
表示名を
Set BUNDLE_ROOT environment variableに設定します。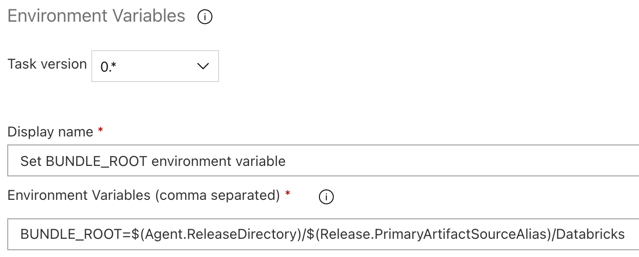
-
[保存] > [OK] をクリックします。
ステップ3.6。 Databricks CLIとPython wheelビルドツールをインストールする
-
次に、リリース エージェントにDatabricks CLIとPython wheelビルド ツールをインストールします。 リリース エージェントは、次の数回のタスクでDatabricks CLIとPython wheelビルド ツールを呼び出します。 これを行うには、 Bash タスクを使用します。 エージェント ジョブ セクションでもう一度プラス記号をクリックし、 ユーティリティ タブで Bash タスクを選択して、 追加 をクリックします。
-
エージェントジョブ の横にある Bash スクリプト タスクをクリックします。
-
タイプ には、 インライン を選択します。
-
スクリプト の内容を次のコマンドに置き換えます。これにより、 Databricks CLIとPython wheelビルド ツールがインストールされます。
Bashcurl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
pip install wheel -
表示名を
Install Databricks CLI and Python wheel build toolsに設定します。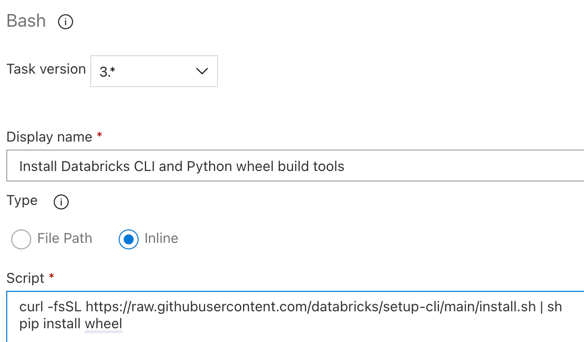
-
[保存] > [OK] をクリックします。
ステップ 3.7: Databricksアセット バンドルを検証する
このステップでは、 databricks.ymlファイルが構文的に正しいことを確認します。
-
Bash タスクを使用します。 エージェント ジョブ セクションでもう一度プラス記号をクリックし、 ユーティリティ タブで Bash タスクを選択して、 追加 をクリックします。
-
エージェントジョブ の横にある Bash スクリプト タスクをクリックします。
-
タイプ には、 インライン を選択します。
-
スクリプト の内容を次のコマンドに置き換えます。このコマンドは、Databricks CLI を使用して、
databricks.ymlファイルの構文が正しいかどうかを確認します。Bashdatabricks bundle validate -t $(BUNDLE_TARGET) -
表示名を
Validate bundleに設定します。 -
[保存] > [OK] をクリックします。
ステップ 3.8: バンドルをデプロイする
このステップでは、 Python wheelファイルをビルドし、ビルドされたPython wheelファイル、2 つのPythonノートブック、およびリリース パイプラインからのPythonファイルをDatabricksワークスペースにデプロイします。
-
Bash タスクを使用します。 エージェント ジョブ セクションでもう一度プラス記号をクリックし、 ユーティリティ タブで Bash タスクを選択して、 追加 をクリックします。
-
エージェントジョブ の横にある Bash スクリプト タスクをクリックします。
-
タイプ には、 インライン を選択します。
-
スクリプト の内容を次のコマンドに置き換えます。このコマンドは、 Databricks CLIを使用してPython wheelファイルを構築し、この記事のサンプル ファイルをリリース パイプラインからDatabricksワークスペースにデプロイします。
Bashdatabricks bundle deploy -t $(BUNDLE_TARGET) -
表示名を
Deploy bundleに設定します。 -
[保存] > [OK] をクリックします。
ステップ 3.9: Python wheelの単体テストを実行する ノートブック
このステップでは、 Databricksワークスペースで単体テスト ノートブックを実行するジョブを実行します。 このノートブック実行ユニットはPython wheelライブラリのロジックに対してテストします。
-
Bash タスクを使用します。 エージェント ジョブ セクションでもう一度プラス記号をクリックし、 ユーティリティ タブで Bash タスクを選択して、 追加 をクリックします。
-
エージェントジョブ の横にある Bash スクリプト タスクをクリックします。
-
タイプ には、 インライン を選択します。
-
スクリプト の内容を、Databricks CLI を使用して Databricks ワークスペースでジョブを実行する次のコマンドに置き換えます。
Bashdatabricks bundle run -t $(BUNDLE_TARGET) run-unit-tests -
表示名を
Run unit testsに設定します。 -
[保存] > [OK] をクリックします。
ステップ 3.10: Python wheelを呼び出すノートブックを実行する
このステップでは、 Databricksワークスペース内の別のノートブックを実行するジョブを実行します。 このノートブックはPython wheelライブラリ と呼んでいます。
-
Bash タスクを使用します。 エージェント ジョブ セクションでもう一度プラス記号をクリックし、 ユーティリティ タブで Bash タスクを選択して、 追加 をクリックします。
-
エージェントジョブ の横にある Bash スクリプト タスクをクリックします。
-
タイプ には、 インライン を選択します。
-
スクリプト の内容を、Databricks CLI を使用して Databricks ワークスペースでジョブを実行する次のコマンドに置き換えます。
Bashdatabricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebook -
表示名を
Run notebookに設定します。 -
[保存] > [OK] をクリックします。
これでリリース パイプラインの構成が完了しました。次のようになります。
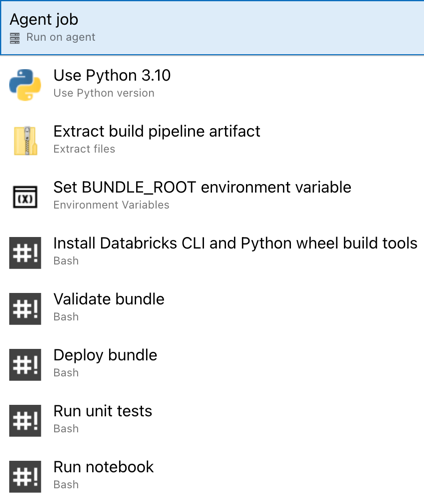
ステップ 4: パイプラインのビルドとリリースを実行する
このステップでは、パイプラインを手動で実行します。パイプラインを自動的に実行する方法の詳細については、 「パイプラインをトリガーするイベントの指定」および「トリガーのリリース」を参照してください。
ビルド パイプラインを手動で実行するには:
- サイドバーの 「パイプライン」 メニューで、 「パイプライン」 をクリックします。
- ビルド パイプラインの名前をクリックし、 [パイプラインの実行] をクリックします。
- [ブランチ/タグ] で、追加したすべてのソース コードを含むGitリポジトリ内のブランチの名前を選択します。 この例では、これが
releaseブランチにあると想定しています。 - 実行 をクリックします。ビルド パイプラインの実行ページが表示されます。
- ビルド パイプラインの進行状況を確認し、関連ログを表示するには、 ジョブ の横にある回転アイコンをクリックします。
- ジョブ アイコンが緑色のチェック マークに変わったら、リリース パイプラインの実行に進みます。
リリース パイプラインを手動で実行するには:
- ビルド パイプラインが正常に実行されたら、サイドバーの パイプライン メニューで [リリース] を クリックします。
- リリース パイプラインの名前をクリックし、 [リリースの作成] を クリックします。
- 作成 をクリックします。
- リリース パイプラインの進行状況を確認するには、リリースのリストで最新のリリースの名前をクリックします。
- [ステージ] ボックスで、 [ステージ 1] をクリックし、 [ログ] をクリックします。