Visual Studio Code の Databricks 拡張機能を使用して、クラスター上のファイル、またはファイルまたはノートブックを Databricks のジョブとして実行する
Visual Studio Code の Databricks 拡張機能を使用すると、 Python コードをクラスターで実行したり、 Python、R、 Scala、 SQL コード、ノートブックを Databricksのジョブとして実行したりできます。
この情報は、Visual Studio Code の Databricks 拡張機能を既にインストールして設定していることを前提としています。 Visual Studio Code の Databricks 拡張機能のインストールを参照してください。
Visual Studio Code 内からコードまたはノートブックをデバッグするには、Databricks Connect を使用します。 Visual Studio Code の Databricks 拡張機能については、Databricks Connect を使用したコードのデバッグ、およびVisual Studio Code の Databricks 拡張機能を使用して Databricks Connect でノートブック セルを実行およびデバッグするを参照してください。
クラスター上の Python ファイルの実行
この機能は、サーバレス コンピュートを使用している場合は使用できません。
Visual Studio Code のDatabricks拡張機能を使用してDatabricksクラスターでPythonファイルを実行し、その拡張機能とプロジェクトを開いた状態で実行するには、次のようにします。
- クラスターで実行する Python ファイルを開きます。
- 以下のいずれかを実行します。
-
ファイル エディターのタイトル バーで、[ Databricks で実行 ] アイコンをクリックし、[ ファイルのアップロードと実行 ] をクリックします。
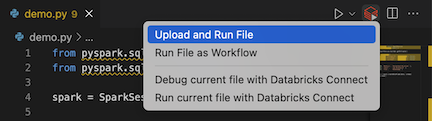
-
エクスプローラー ビュー ( 表示 > エクスプローラー ) で、ファイルを右クリックし、コンテキスト メニューから Databricks > アップロードしてファイルを実行 を選択します。
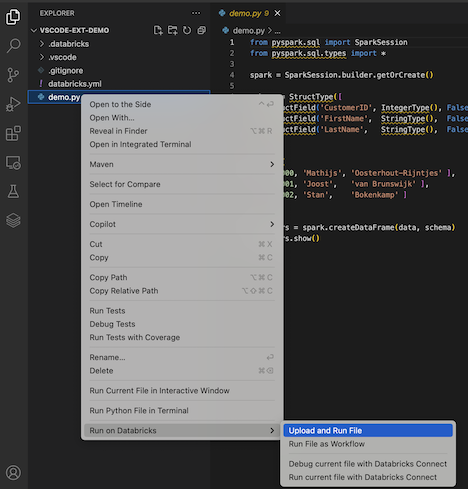
-
クラスターで実行され、出力されたファイルは デバッグコンソール ( 表示 > デバッグコンソール )で使用できます。
Python ファイルをジョブとして実行する
Visual Studio Code の Databricks 拡張機能を使用して Python ファイルを Databricks ジョブとして実行するには、拡張機能とプロジェクトを開いた状態で、次のようにします。
- ジョブとして実行する Python ファイルを開きます。
- 以下のいずれかを実行します。
-
ファイル エディターのタイトル バーで、 Databricks で実行 アイコンをクリックし、 ファイルをワークフローとして実行 をクリックします。
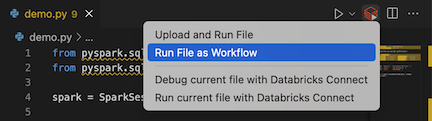
-
エクスプローラー ビュー ( 表示 > エクスプローラー ) で、ファイルを右クリックし、コンテキスト メニューから Databricks で実行 > ファイルをワークフローとして実行 を選択します。
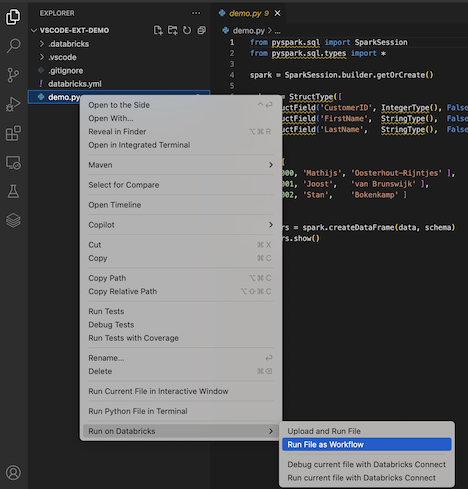
-
Databricks ジョブの実行 というタイトルの新しいエディター タブが表示されます。ファイルはワークスペースでジョブとして実行され、出力は新しいエディター タブの 出力 領域に表示されます。
ジョブ実行に関する情報を表示するには、新しい Databricks ジョブ実行 エディタータブの タスク 実行 ID リンクをクリックします。ワークスペースが開き、ジョブ実行の詳細がワークスペースに表示されます。
Python、R、Scala、または SQL ノートブックをジョブとして実行する
Visual Studio Code の Databricks 拡張機能を使用してノートブックを Databricks ジョブとして実行するには、拡張機能とプロジェクトを開いた状態で、次の操作を行います。
- ジョブとして実行するノートブックを開きます。
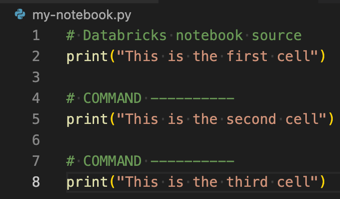
Python、R、Scala、または SQL ファイルを Databricks ノートブックに変換するには、ファイルの先頭にコメント # Databricks notebook source を追加し、各セルの前にコメント # COMMAND ---------- を追加します。詳細については、「 ファイルをノートブックに変換する」を参照してください。
-
以下のいずれかを実行します。
- ノートブック ファイル エディターのタイトル バーで、 Databricks で実行 アイコンをクリックし、 ファイルをワークフローとして実行 をクリックします。
ワークフローとしてDatabricksを実行 が使用できない場合は、カスタム実行構成の作成を参照してください。
- エクスプローラー ビュー ( 表示 > エクスプローラー ) で、ノートブック ファイルを右クリックし、コンテキスト メニューから Databricks で実行 > ファイルをワークフローとして実行 を選択します。
Databricks ジョブの実行 というタイトルの新しいエディター タブが表示されます。ノートブックは、ワークスペースでジョブとして実行されます。ノートブックとその出力は、新しいエディター タブの 出力 領域に表示されます。
ジョブ実行に関する情報を表示するには、 Databricks ジョブ実行 エディター タブの タスク実行 ID リンクをクリックします。ワークスペースが開き、ジョブ実行の詳細がワークスペースに表示されます。
カスタム実行構成を作成する
Visual Studio Code 用 Databricks 拡張機能のカスタム実行構成を使用すると、ジョブやノートブックにカスタム引数を渡したり、ファイルごとに異なる実行設定を作成したりできます。詳細については、Visual Studio Code のドキュメントにある「起動構成」を参照してください。
カスタム実行構成を作成するには、Visual Studio Code のメイン メニューから 実行 > 構成の追加 をクリックします。 次に、クラスターベースの実行構成の場合は Databricks を、ジョブベースの実行構成の場合は Databricks: ワークフロー を選択します。
たとえば、次のカスタム実行構成では、 実行ファイルをワークフロー 起動コマンドとして変更し、 --prod 引数をジョブに渡します。
{
"version": "0.2.0",
"configurations": [
{
"type": "databricks-workflow",
"request": "launch",
"name": "Run on Databricks as Workflow",
"program": "${file}",
"parameters": {},
"args": ["--prod"]
}
]
}
Python 構成を使用し、拡張機能のセットアップの一部である Databricks Connect 認証を利用する場合は、 "databricks": true "type": "python"構成に追加します。