エクスペクテーションの推奨事項と高度なパターン
この記事には、エクスペクテーションを大規模に実装するための推奨事項と、エクスペクテーションによってサポートされる高度なパターンの例が含まれています。 これらのパターンでは、複数のデータセットをエクスペクテーションと組み合わせて使用し、ユーザーはマテリアライズドビュー、ストリーミング テーブル、およびエクスペクテーションの構文とセマンティクスを理解する必要があります。
エクスペクテーションの動作と構文の基本的な概要については、「 パイプラインのエクスペクテーションを使用してデータ品質を管理する」を参照してください。
移植性と再利用性への期待
Databricks では、移植性を向上させ、メンテナンスの負担を軽減するためのエクスペクテーションを実装する際に、次のベスト プラクティスを推奨しています。
推奨事項 | インパクト |
|---|---|
エクスペクテーションの定義をパイプライン ロジックとは別に格納します。 | 複数のデータセットやパイプラインに期待事項を簡単に適用できます。 パイプラインのソースコードを変更せずに、エクスペクテーションを更新、監査、維持します。 |
カスタムタグを追加して、関連するエクスペクテーションのグループを作成します。 | タグに基づいてエクスペクテーションをフィルタリングします。 |
類似したデータセットに一貫してエクスペクテーションを適用します。 | 複数のデータセットとパイプラインで同じエクスペクテーションを使用して、同一のロジックを評価します。 |
次の例は、Delta テーブルまたはディクショナリを使用して中央のエクスペクテーションリポジトリを作成する方法を示しています。 次に、カスタム Python 関数がこれらのエクスペクテーションをサンプル パイプラインのデータセットに適用します。
- Delta Table
- Python Module
次の例では、ルールを維持するためにrulesという名前のテーブルを作成します:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
次の Python の例では、 rules テーブルのルールに基づいてデータ品質のエクスペクテーションを定義しています。 get_rules() 関数は、rules テーブルからルールを読み取り、関数に渡された tag 引数に一致するルールを含む Python ディクショナリを返します。
この例では、データ品質の制約を適用するために、 @dp.expect_all_or_drop()デコレータを使用して辞書が適用されます。
たとえば、 validityのタグが付けられたルールに違反したレコードは、 raw_farmers_marketテーブルから削除されます。
from pyspark import pipelines as dp
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
次の例では、ルールを維持するための Python モジュールを作成します。この例では、パイプラインのソース コードとして使用されるノートブックと同じフォルダー内のrules_module.pyという名前のファイルにこのコードを保存します。
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
次の Python の例では、 rules_module.py ファイルで定義されているルールに基づいて、データ品質のエクスペクテーションを定義しています。 get_rules()関数は、渡された tag 引数に一致するルールを含む Python ディクショナリを返します。
この例では、データ品質の制約を適用するために、 @dp.expect_all_or_drop()デコレータを使用して辞書が適用されます。
たとえば、 validityのタグが付けられたルールに違反したレコードは、 raw_farmers_marketテーブルから削除されます。
from pyspark import pipelines as dp
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
行数の検証
次の例では、 table_aとtable_bの行数が等しいかどうかを検証し、変換中にデータが失われないことを確認します。
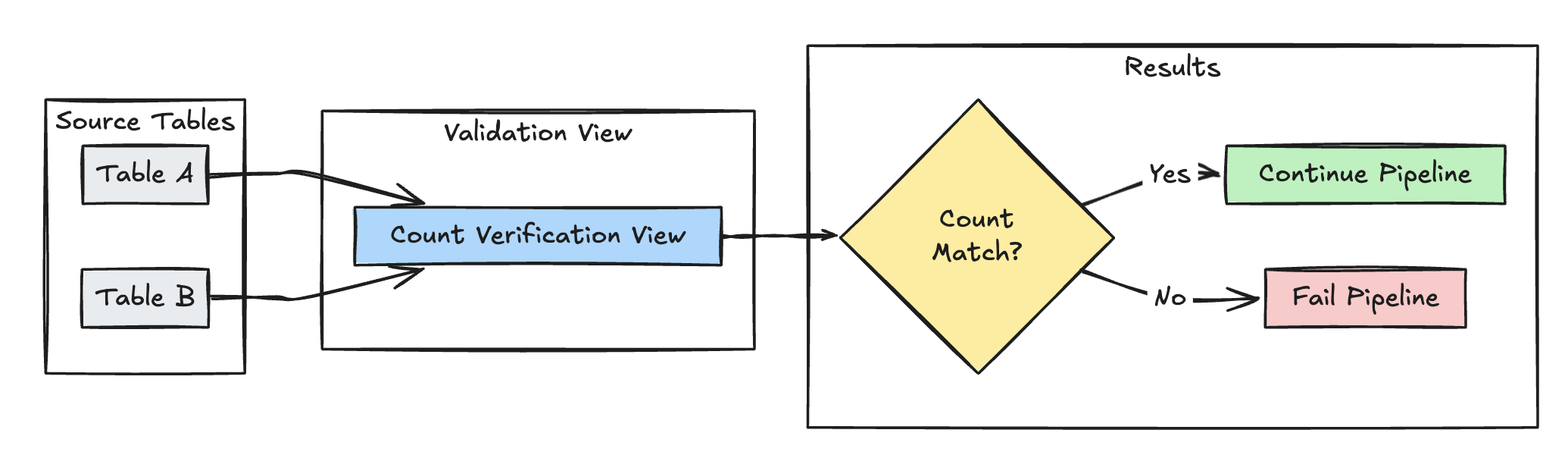
- Python
- SQL
@dp.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dp.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
欠落レコードの検出
次の例では、予期されるすべてのレコードがreportテーブルに存在することを検証します:
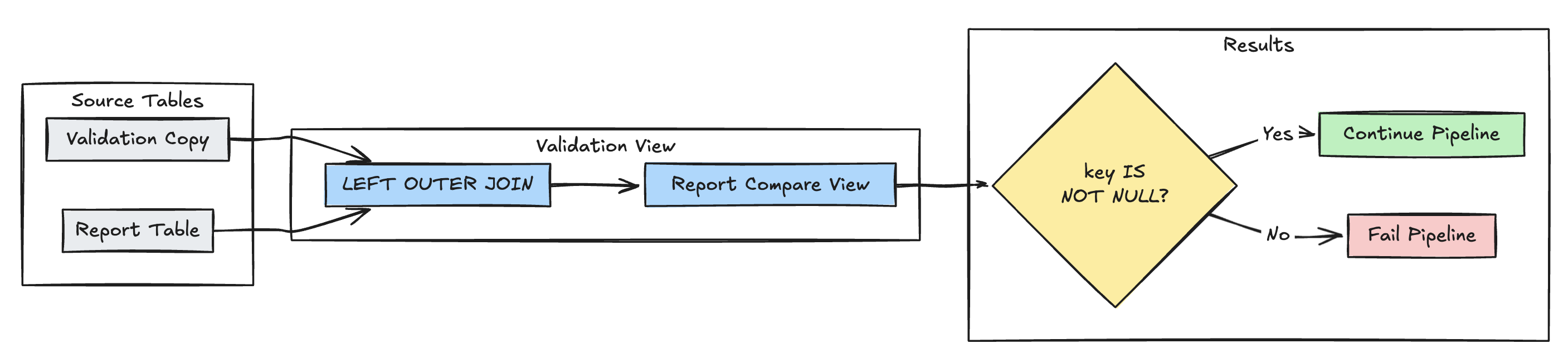
- Python
- SQL
@dp.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dp.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
spark.read.table("validation_copy").alias("v")
.join(
spark.read.table("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
主キーの一意性
次の例では、テーブル間の主キー制約を検証します。
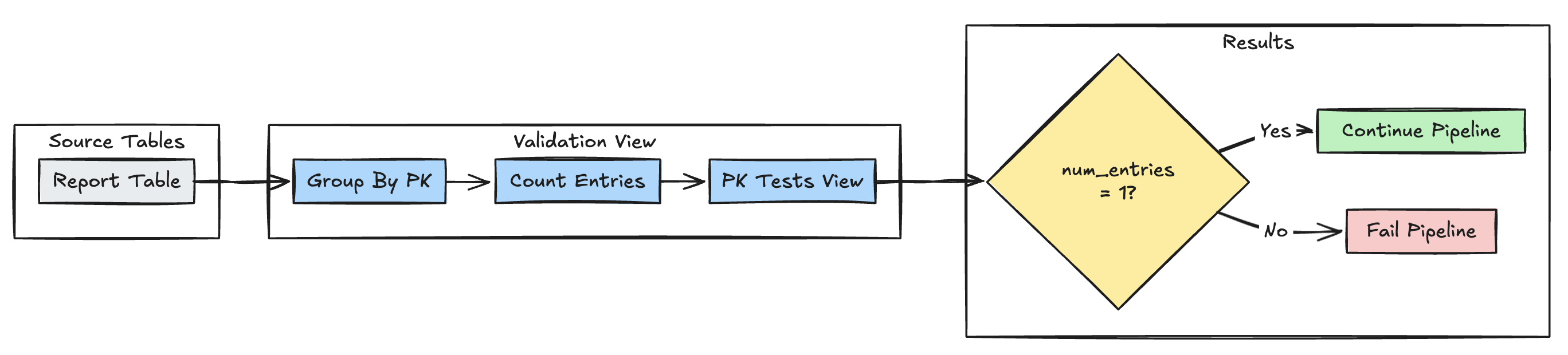
- Python
- SQL
@dp.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dp.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
spark.read.table("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
スキーマ進化パターン
次の例は、追加の列のスキーマ進化を処理する方法を示しています。 データソースを移行する場合や、アップストリーム データの複数のバージョンを処理する場合は、このパターンを使用して、データ品質を強化しながら下位互換性を確保します。
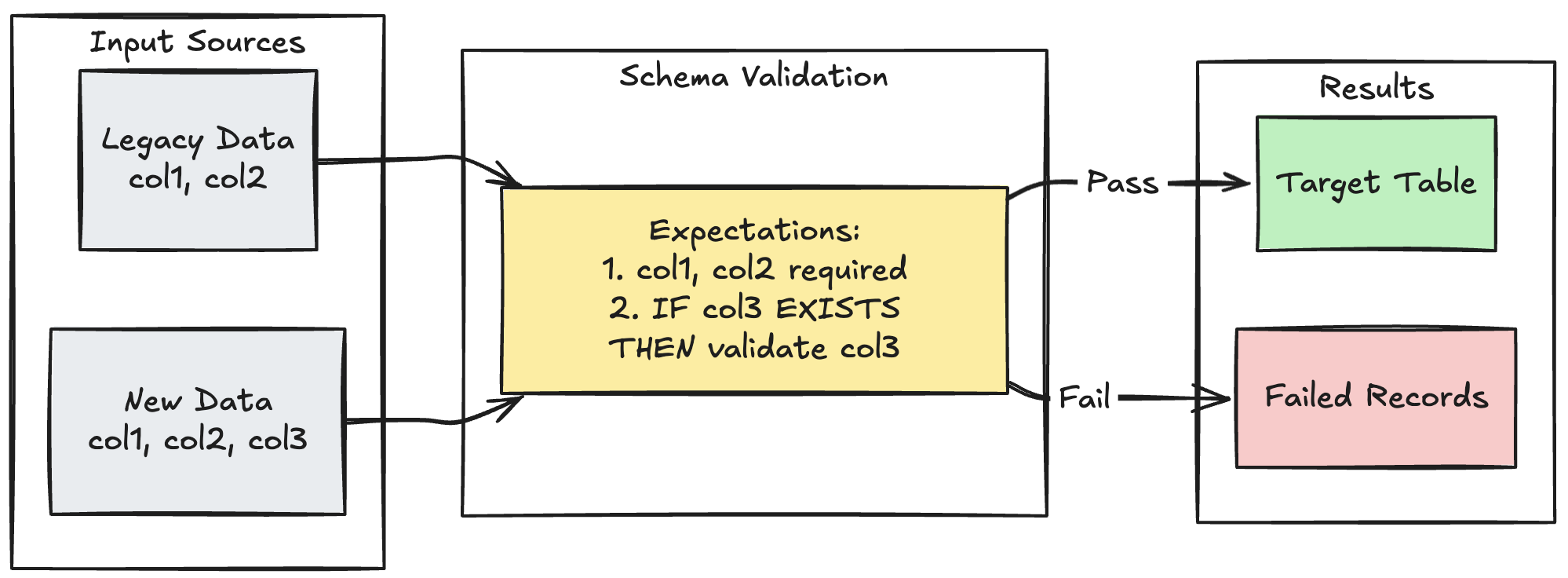
- Python
- SQL
@dp.table
@dp.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
範囲ベースの検証パターン
次の例は、過去の統計範囲に対して新しいデータポイントを検証し、データ フロー内の外れ値や異常を特定する方法を示しています。
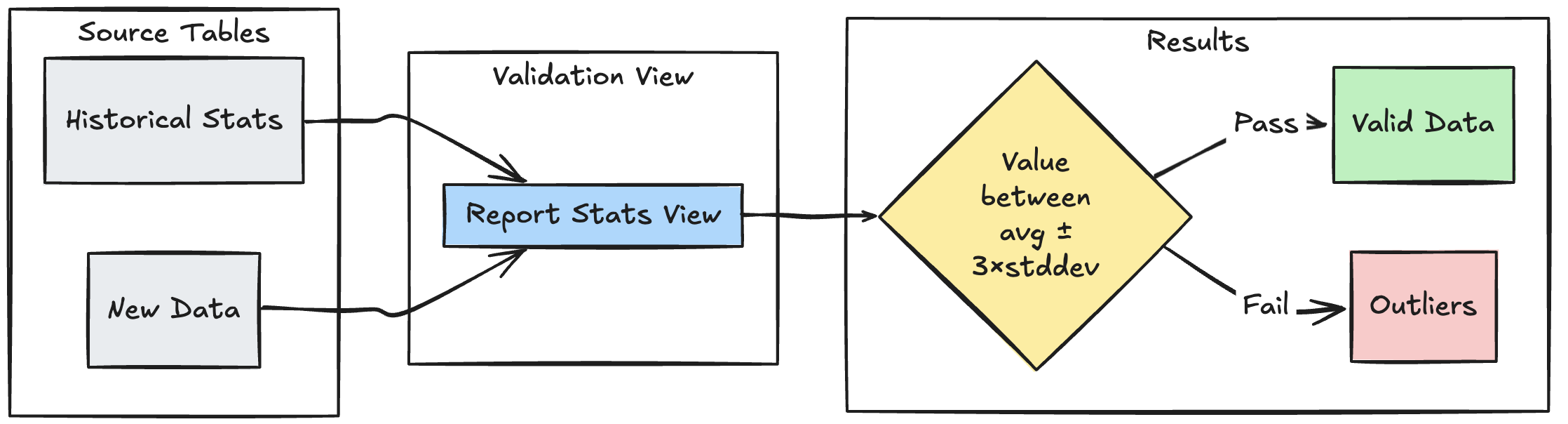
- Python
- SQL
@dp.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dp.table
@dp.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return spark.read.table("stats_validation_view")
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
無効なレコードを隔離する
このパターンは、エクスペクテーションと一時テーブルおよびビューを組み合わせて、パイプラインの更新中にデータ品質メトリクスを追跡し、ダウンストリーム操作で有効なレコードと無効なレコードに対して別々の処理パスを有効にします。
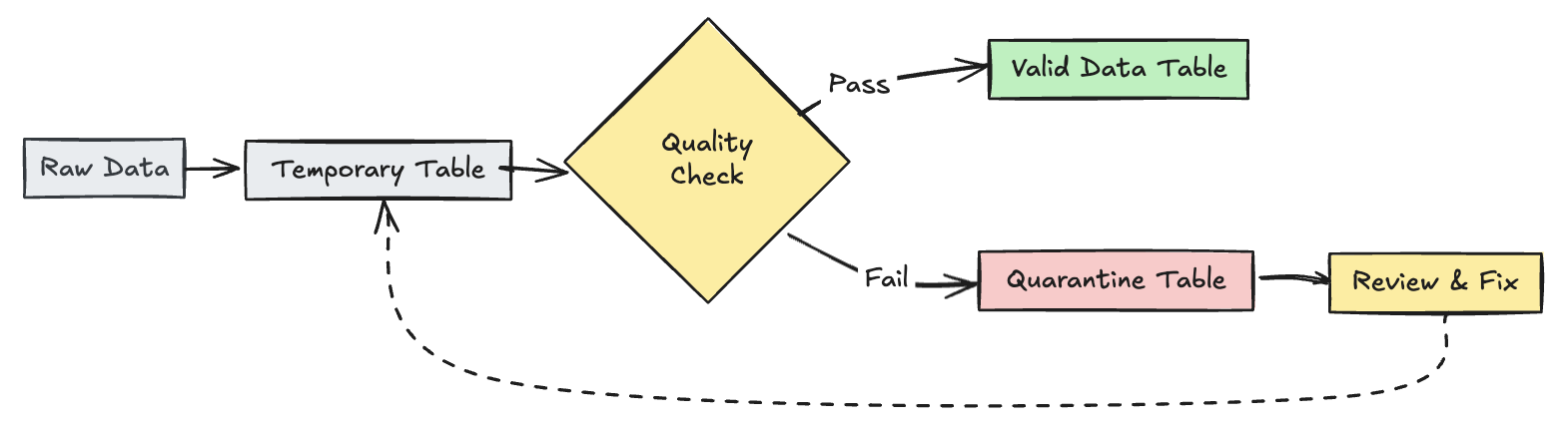
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dp.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dp.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dp.expect_all(rules)
def trips_data_quarantine():
return (
spark.readStream.table("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dp.view
def valid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=false")
@dp.view
def invalid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=true")
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;