パイプラインのエクスペクテーションによるデータ品質の管理
エクスペクテーションを使用して、ETL パイプラインを流れるデータを検証する品質制約を適用します。 エクスペクテーションにより、データ品質メトリクスに関するより深い知見が得られ、無効なレコードを検出したときに更新を失敗させたり、レコードを削除したりできます。
より高度なユース ケースと推奨されるベスト プラクティスについては、「エクスペクテーションの推奨事項と高度なパターン」を参照してください。
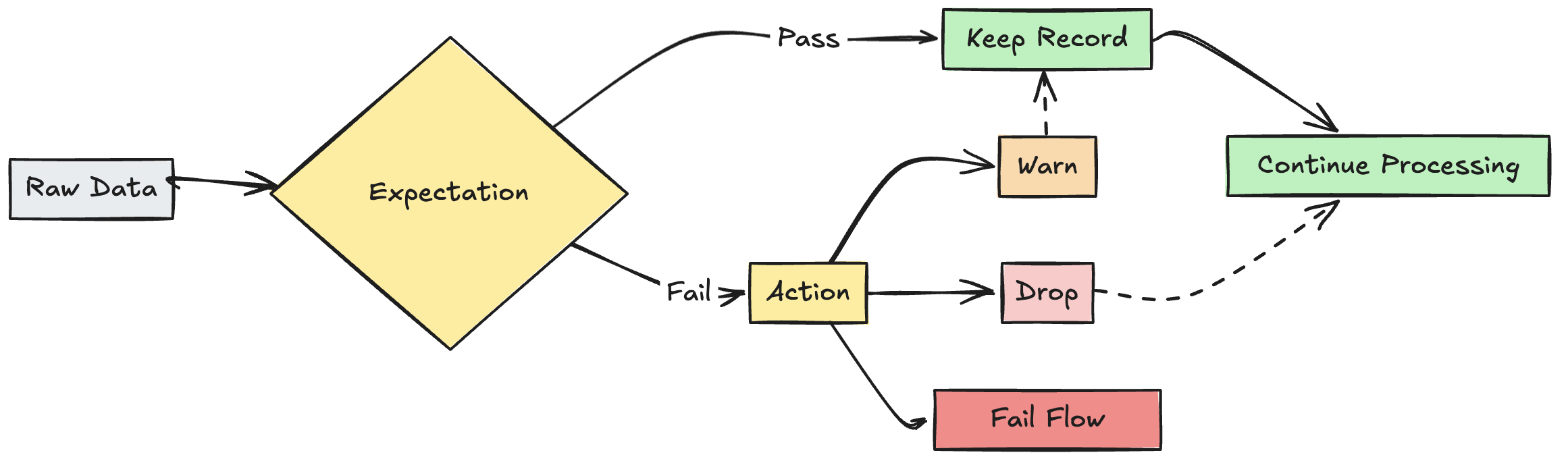
エクスペクテーションとは?
エクスペクテーションは、パイプラインのマテリアライズドビュー、ストリーミング テーブル、またはビュー作成ステートメントの省略可能な句で、クエリを通過する各レコードにデータ品質チェックを適用します。 エクスペクションは、標準の SQL Boolean ステートメントを使用して制約を指定します。 1 つのデータセットに対して複数のエクスペクテーションを組み合わせて、パイプライン内のすべてのデータセット宣言にエクスペクテーションを設定できます。
Databricks SQLで作成されたスタンドアロンのパイプラインによってサポートされているストリーミングテーブルとマテリアライズドビューに対して、期待値を定義することもできます。CREATE STREAMING TABLEおよびCREATE MATERIALIZED VIEWでCONSTRAINT expectation_name EXPECT (expectation_expr)句を使用します。
次のセクションでは、エクスペクテーションの 3 つのコンポーネントを紹介し、構文の例を示します。
エクスペクテーションの名前
各エクスペクテーションには名前が必要であり、これはエクスペクテーションを追跡および監視するための識別子として使用されます。 検証されるメトリクスを伝える名前を選択します。 次の例では、年齢が 0 歳から 120 歳までであることを確認する valid_customer_age エクスペクテーションを定義しています。
エクスペクテーション名は、特定のデータセットに対して一意である必要があります。 パイプライン内の複数のデータセット間で期待を再利用できます。 ポータブルで再利用可能な期待を参照してください。
- Python
- SQL
@dp.table
@dp.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
評価のための制約
制約句は、各レコードに対して true または false に評価される必要がある SQL 条件ステートメントです。 制約には、検証対象の実際のロジックが含まれています。レコードがこの条件に満たない場合、エクスペクテーションがトリガーされます。
制約には有効な SQL 構文を使用する必要があり、次のものを含めることはできません。
- カスタム Python 関数
- 外部サービス呼び出し
- 他のテーブルを参照するサブクエリ
以下は、データセット作成ステートメントに追加できる制約の例です。
- Python
- SQL
Python における制約の構文は次のとおりです。
@dp.expect(<constraint-name>, <constraint-clause>)
複数の制約を指定できます。
@dp.expect(<constraint-name>, <constraint-clause>)
@dp.expect(<constraint2-name>, <constraint2-clause>)
例:
# Simple constraint
@dp.expect("non_negative_price", "price >= 0")
# SQL functions
@dp.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dp.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dp.expect("non_negative_price", "price >= 0")
@dp.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dp.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dp.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL における制約の構文は次のとおりです。
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> )
複数の制約はコンマで区切る必要があります。
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> ),
CONSTRAINT <constraint2-name> EXPECT ( <constraint2-clause> )
例:
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0),
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
無効なレコードに対するアクション
レコードが検証チェックに失敗した場合に何が起こるかを決定するアクションを指定する必要があります。次の表では、利用可能なアクションについて説明します。
また、データを失敗させたり削除したりすることなく、無効なレコードを隔離する高度なロジックを実装することもできます。 無効なレコードの検疫を参照してください。
エクスペクテーションの追跡メトリクス
パイプライン UI から、 warnまたはdropアクションの追跡メトリクスを確認できます。 failでは無効なレコードが検出されると更新が失敗するため、メトリックは記録されません。
Databricks SQL で作成されたスタンドアロンのパイプラインによってサポートされるストリーミングテーブルとマテリアライズドビューの場合、パイプライン UI の **Data quality** タブは利用できません。 期待メトリクスを表示するには、イベントログをクエリしてください。「クエリ データの品質または期待メトリクス」を参照してください。
エクスペクテーション メトリクスを表示するには、以下のステップを実行します。
- Databricks ワークスペースのサイドバーで、 ジョブとパイプライン をクリックします。
- パイプラインの 名前 をクリックします。
- エクスペクテーションが定義されているデータセットをクリックします。
- 右側のサイドバーにある データ品質 タブを選択します。
LakeFlow Pipelines イベント log をクエリーすることで、データ品質メトリクスを表示できます。データ品質またはエクスペクテーションメトリクスをクエリーする を参照してください。
無効なレコードを保持する
無効なレコードの保持は、エクスペクテーションのデフォルトの動作です。 expect演算子は、エクスペクテーションに反するレコードを保持しながら、制約に合格したレコードまたは失敗したレコードの数に関するメトリクスを収集する場合に使用します。期待に違反するレコードは、有効なレコードとともにターゲットデータセットに追加されます:
- Python
- SQL
@dp.expect("valid timestamp", "timestamp > '2012-01-01'")
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
無効なレコードを削除する
無効なレコードがそれ以上処理されないようにするには、expect_or_drop演算子を使用します。期待に反するレコードは、ターゲットデータセットから削除されます:
- Python
- SQL
@dp.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
無効なレコードで失敗する
無効なレコードを許容できない場合は、expect_or_fail演算子を使用して、レコードがバリデーションに失敗したときに直ちに実行を停止します。操作がテーブル更新の場合、システムはトランザクションをアトミックにロールバックする:
- Python
- SQL
@dp.expect_or_fail("valid_count", "count > 0")
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
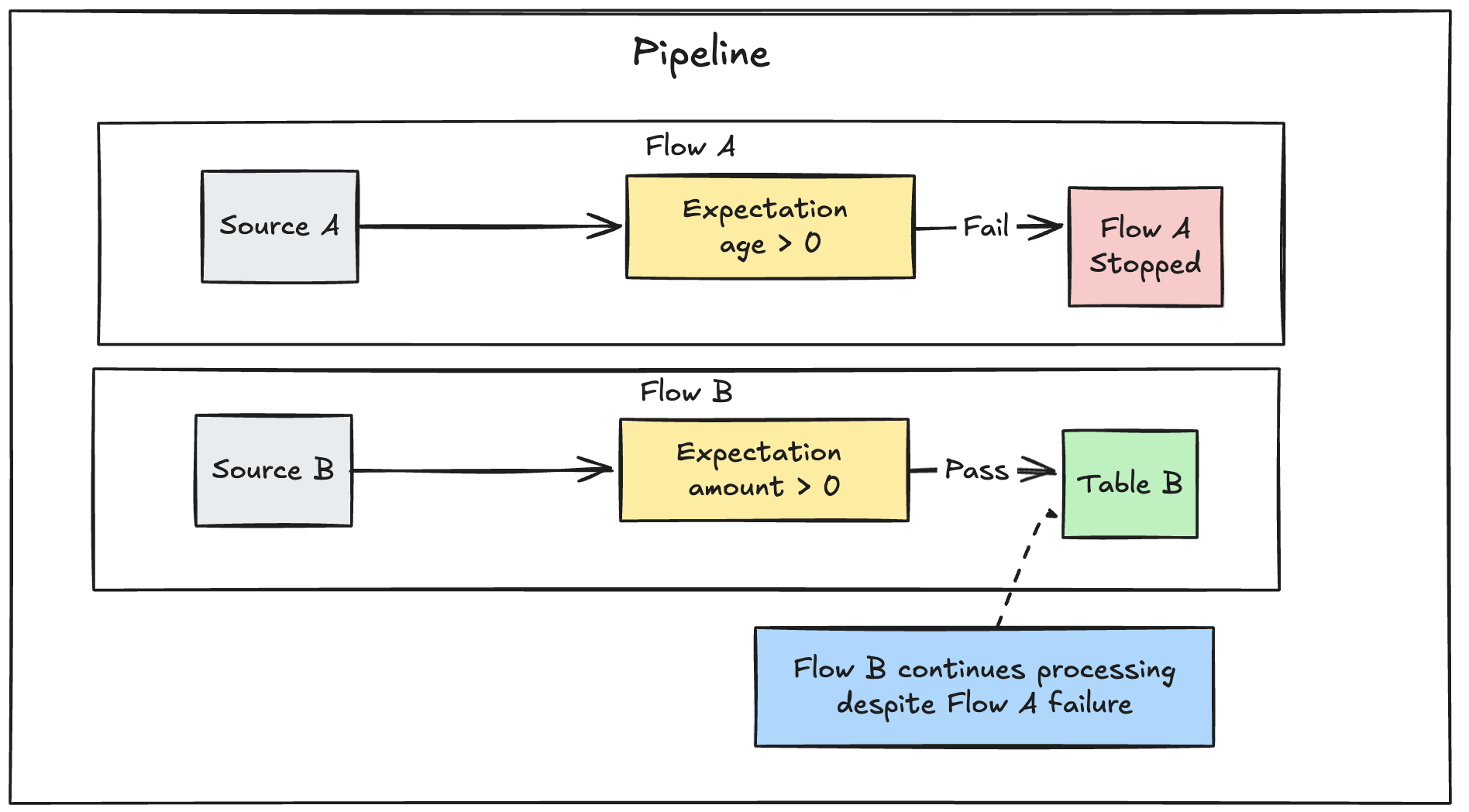
Triggerされたパイプラインでは、単一のフローの失敗によって他の並列フローが失敗することはありません。連続パイプラインでは、期待される条件が満たされないと、フローとそれに依存するすべてのフローが停止し、パイプラインは停止理由を説明するメッセージを出力します。
検証が失敗した場合のワークフローオーケストレーションをより詳細に制御するには、検証とダウンストリーム作業を個別のパイプラインに分割し、パイプラインタスク間の制御フローで調整します。検証テーブルとパイプライン制御フローを参照してください。
エクスペクテーションから失敗した更新のトラブルシューティング
エクスペクテーション違反によりパイプラインが失敗した場合は、パイプラインを再実行する前に、無効なデータを正しく処理できるようにパイプラインコードを修正する必要があります。
パイプラインが失敗するように構成されたエクスペクテーションは、違反を検出して報告するために必要な情報を追跡するために、変換のSparkクエリープランを変更します。この情報を使用して、多くのクエリーでどの入力レコードが違反の原因となったかを特定できます。LakeFlow Pipelinesは、そのような違反を報告するための専用のエラーメッセージを提供します。エクスペクテーション違反のエラーメッセージの例を次に示します。
[EXPECTATION_VIOLATION.VERBOSITY_ALL] Flow 'sensor-pipeline' failed to meet the expectation. Violated expectations: 'temperature_in_valid_range'. Input data: '{"id":"TEMP_001","temperature":-500,"timestamp_ms":"1710498600"}'. Output record: '{"sensor_id":"TEMP_001","temperature":-500,"change_time":"2024-03-15 10:30:00"}'. Missing input data: false
複数のエクスペクテーションを管理
SQL と Python はどちらも単一のデータセット内で複数の期待値をサポートしていますが、複数の期待値をグループ化して集合的なアクションを指定できるのは Python だけです。
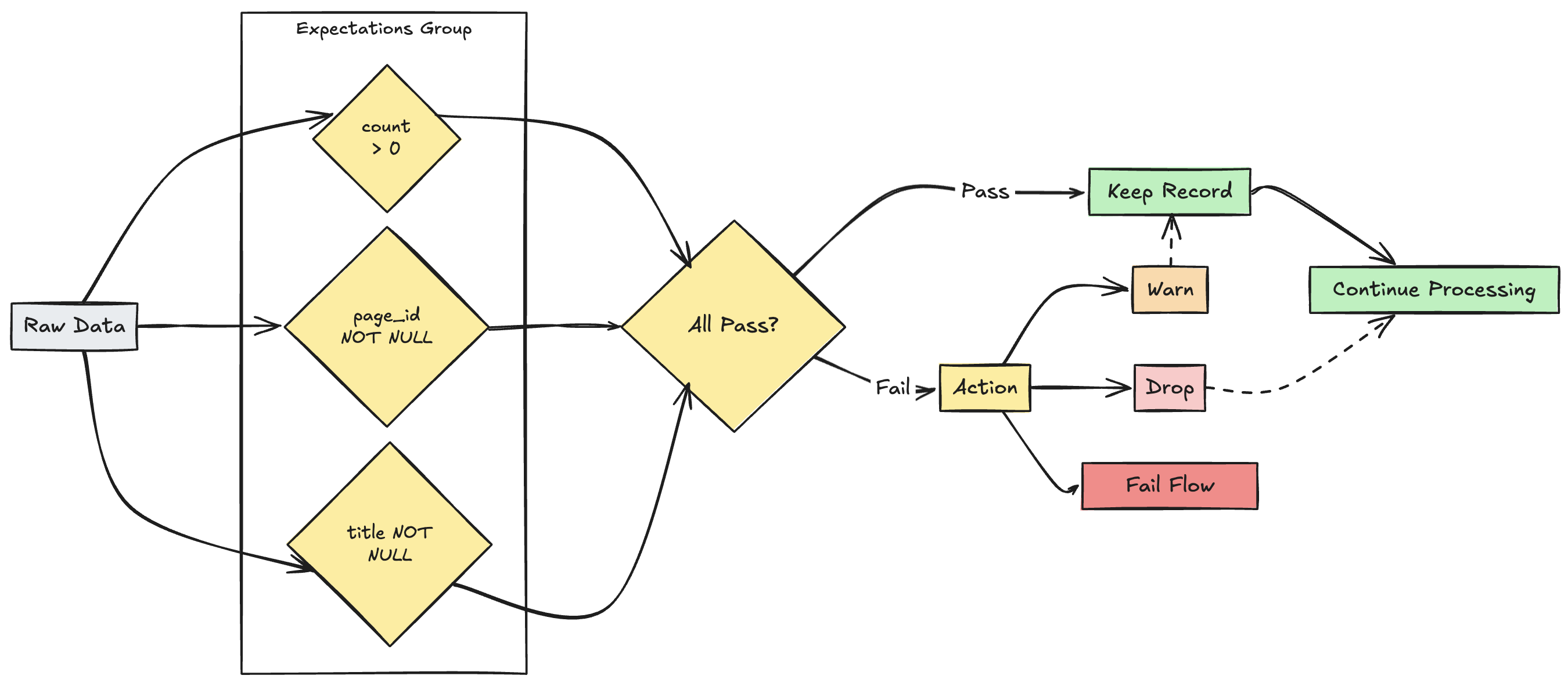
複数のエクスペクテーションをグループ化し、 expect_all、 expect_all_or_drop、および expect_all_or_fail機能を使用して集合アクションを指定できます。
これらのデコレータは、Python ディクショナリを引数として受け入れ、キーはエクスペクテーションの名前で、値はエクスペクテーション制約です。 パイプライン内の複数のデータセットで同じエクスペクテーションセットを再利用できます。 次に、 expect_all Python の各演算子の例を示します。
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dp.table
@dp.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dp.table
@dp.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dp.table
@dp.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset
制限事項
-
期待をサポートしているのはストリーミング テーブル、マテリアライズドビュー、および一時ビューのみであるため、データ品質メトリクスはこれらのオブジェクト タイプでのみサポートされています。
-
データ品質メトリクスは、次の場合には使用できません。
- クエリに期待値が定義されていません。
- フローでは期待値をサポートしない演算子が使用されています。
- sinksなどのフロー タイプは期待値をサポートしていません。
- 特定のフロー実行に関連付けられたストリーミング テーブルまたはマテリアライズドビューへの更新はありません。
- パイプライン構成には、メトリクスのキャプチャに必要な設定 (
pipelines.metrics.flowTimeReporter.enabledなど) が含まれていません。
-
場合によっては、
COMPLETEDフローにメトリクスが含まれない場合があります。 代わりに、メトリクスは、ステータスRUNNINGのflow_progressイベントの各マイクロバッチで報告されます。 -
ビューはクエリ実行時にのみ計算されるため、定義されたビューではデータ品質メトリックが利用できない場合があります。 あるいは、複数のダウンストリーム データセットでクエリされるビューには、複数のデータ品質メトリクス セットが含まれる場合があります。
-
AUTO CDC FROM SNAPSHOTでは期待値はサポートされていません。