カスタムLLMを使用して、テキスト用の汎用AIエージェントを作成します(従来型)。
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。「Databricks プレビューの管理」を参照してください。
この記事では、 Custom LLMを使用してカスタムのテキストベースのタスク用の生成AIエージェントを作成する方法について説明します。
カスタムLLMで何ができますか?
カスタムLLMを使用すると、要約、分類、テキスト変換、コンテンツ生成など、あらゆるドメイン固有のタスクで高品質な結果を生成できます。
カスタムLLMは、以下のユースケースに最適です。
- 顧客からの電話の問題と解決策をまとめます。
- 顧客レビューのセンチメントを分析します。
- 研究論文をトピックごとに分類する。
- 新機能のプレス リリースを生成します。
高度な指示と例が与えられると、Custom LLMはユーザーに代わってプロンプトを最適化し、評価基準を自動的に推論し、提供されたデータからシステムを評価し、モデルを実運用可能なエンドポイントとして展開します。
カスタムLLMは、MLflowやエージェント評価などの自動評価機能を活用し、特定の抽出タスクにおけるコストと品質のトレードオフを迅速に評価できるようにします。この評価により、精度とリソース投資のバランスについて、十分な情報に基づいた意思決定を行うことができます。
カスタムLLMは、デフォルトのストレージを使用して、一時的なデータ変換、モデルチェックポイント、および各エージェントを動作させる内部メタデータを保存します。エージェントを削除すると、エージェントに関連付けられたすべてのデータがデフォルトのストレージから削除されます。
必要条件
-
次のものを含むワークスペース。
- サーバレスコンピュート利用可能(ワークスペースでUnity Catalog使用することで有効になります)。
- Unity Catalog が有効になっている。「Unity Catalog のワークスペースを有効にする」を参照してください。
- モデルサービングへアクセスします。
- ゼロ以外の予算でサーバーレス使用ポリシーにアクセスします。
-
サポートされているリージョン内のワークスペース。
-
ai_querySQL関数を使用する機能。 -
入力データを使用する準備ができている必要があります。次のいずれかを選択できます。
-
Unity Catalog テーブル。テーブル名には、特殊文字 (
-など) を含めることはできません。- PDFファイルを使用する場合は、 Unity Catalogテーブル形式に変換してください。 カスタムLLMでのPDFの使用方法を参照してください。
-
少なくとも 3 つの入力と出力の例。このオプションを選択する場合は、エージェントの Unity Catalog スキーマの宛先パスを指定する必要があり、このスキーマに対する CREATE REGISTERED MODEL と CREATE TABLE のアクセス許可が必要です。
-
-
エージェントを最適化するには、少なくとも 100 個の入力 (Unity Catalog テーブルの 100 行、または手動で提供された 100 個の例) が必要です。
カスタム LLM エージェントを作成する
へ移動![]() ワークスペースの左側のナビゲーション ペインにある エージェント 。 カスタム LLM タイルから、 [ビルド] をクリックします。
ワークスペースの左側のナビゲーション ペインにある エージェント 。 カスタム LLM タイルから、 [ビルド] をクリックします。
ステップ 1: エージェントを構成する
[ビルド] タブで [例を表示 >] をクリックして、カスタム LLM エージェントの入力例とモデル応答を展開します。
下のペインで、エージェントを設定します。
-
「タスクの説明」 に、専門化タスクの目的や望ましい結果など、明確で詳細な説明を入力します。
-
ラベル付きデータセット、ラベルなしデータセット、またはエージェントの作成に使用するいくつかの例を提供します。
PDFファイルを使用する場合は、まずUnity Catalogテーブル形式に変換してください。 カスタムLLMでのPDFの使用方法を参照してください。
サポートされているデータ型は、
string、int、およびdoubleです。
- Labeled dataset
- Unlabeled dataset
- A few examples
[ラベル付きデータセット] を選択した場合:
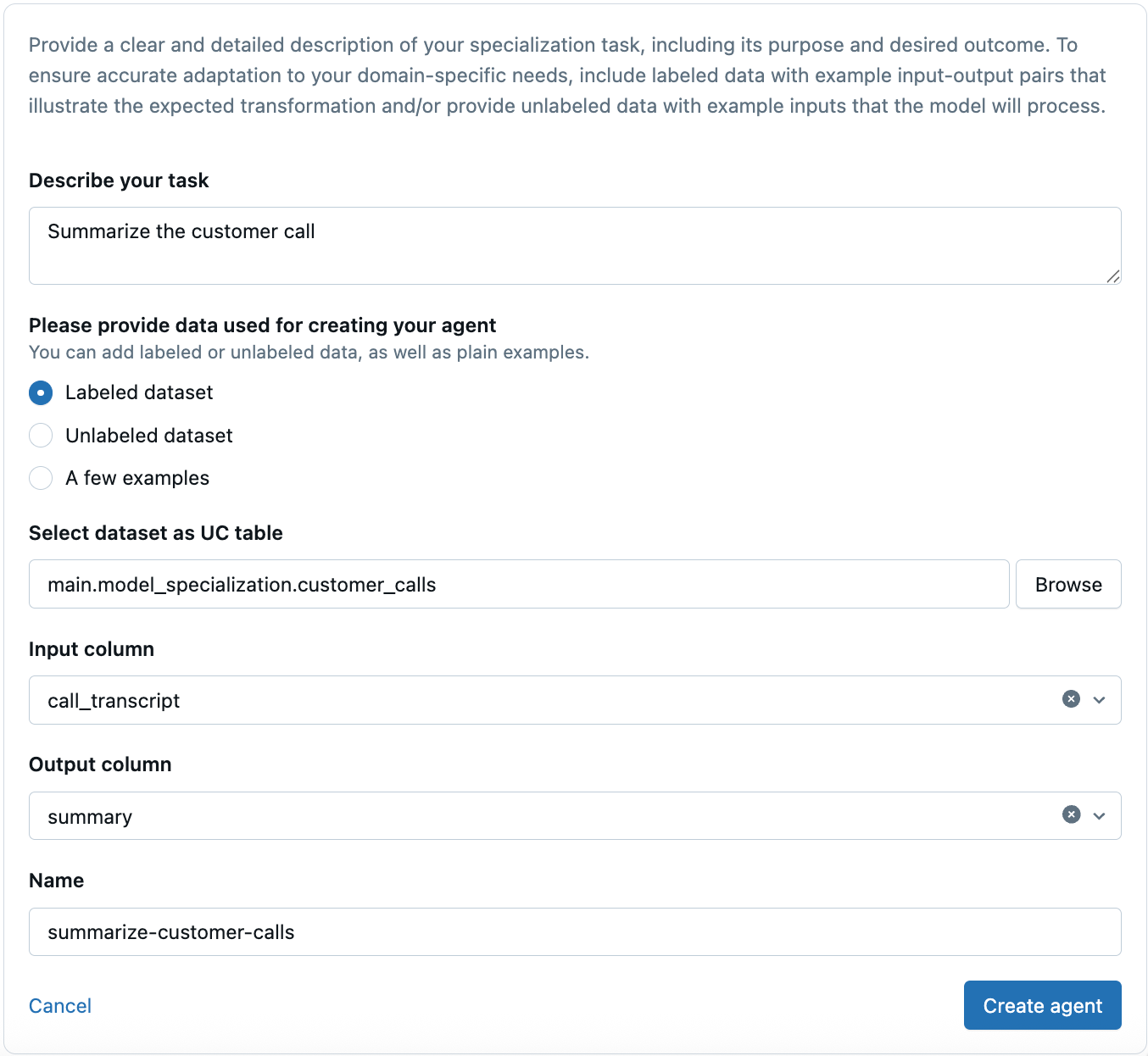
-
[データセットを UC テーブルとして選択] で [ 参照 ] をクリックし、使用する Unity Catalog のテーブルを選択します。テーブル名には、特殊文字 (
-など) を含めることはできません。次に例を示します。
main.model_specialization.customer_call_transcripts -
入力列 フィールドで、入力テキストとして使用する列を選択します。ドロップダウンメニューには、選択したテーブルの列が自動的に入力されます。
-
出力列 で、予期される変換の出力例として提供する列を選択します。このデータを提供すると、ドメイン固有のニーズにより正確に適応するようにエージェントを構成するのに役立ちます。
[ ラベルなしデータセット ] を選択した場合:
-
[データセットを UC テーブルとして選択] で [ 参照 ] をクリックし、使用する Unity Catalog のテーブルを選択します。テーブル名には、特殊文字 (
-など) を含めることはできません。 -
入力列 フィールドで、入力テキストとして使用する列を選択します。ドロップダウンメニューには、選択したテーブルの列が自動的に入力されます。
いくつかの例 を選択した場合:
- 専門化タスクの入力と期待されるアウトプットの例を少なくとも3つ提供してください。 高品質の例を提供することで、専門化エージェントを設定して要件をより深く理解することができます。
- さらに例を追加するには、[ + 追加 ] をクリックします。
- 「エージェントの宛先」 で、Custom LLM が評価データを含むテーブルを作成する際に使用する Unity Catalog スキーマを選択します。このスキーマに対して、CREATE REGISTERED MODEL権限とCREATE TABLE権限が必要です。
-
エージェントに名前を付けます。
-
エージェントの作成 をクリックします。
ステップ 2: エージェントを構築して改善する
[ビルド] タブでは、エージェントを改善するための推奨事項を確認し、サンプル モデルの出力を確認し、タスクの指示と評価基準を調整します。
-
[推奨事項] ペインでは、Databricks はサンプル応答を最適化し、良いか悪いかを評価するのに役立つ推奨事項を提供します。
- エージェントのパフォーマンスを最適化するための Databricks の推奨事項を確認します。
- 応答を改善するためのフィードバックを提供します。それぞれの回答に対して、 「これは良い回答ですか?」 と答えます。 Yes または No で回答します。 いいえ の場合は、応答に関するオプションのフィードバックを提供し、 「保存」 をクリックして次の応答に進みます。
- 推奨事項を 無視する こともできます。
-
右側の [ガイドライン] で、エージェントが適切な出力を生成できるように明確なガイドラインを設定します。これらは品質を自動的に評価するためにも使用されます。
- 提案されたガイドラインを確認します。ガイドラインの提案は自動的に推測され、エージェントの最適化に役立ちます。これらを絞り込んだり削除したりすることができます。
- カスタムLLMでは、追加のガイドラインを提案する場合があります。新しいガイドラインを追加するには 「承認」を 選択し、却下するには 「 却下」を選択するか、テキストをクリックして最初にガイドラインを編集してください。
- 独自のガイドラインを追加するには、
 追加 。
追加 。 - エージェントを更新するには、 [保存して更新] をクリックします。
-
(オプション) 右側の [指示] の下で、タスクについて説明します。エージェントが応答を生成するときに従う追加の指示を追加します。指示を適用するには、 「保存して更新」 をクリックします。
-
エージェントを更新すると、新しいサンプル応答が生成されます。これらの回答を確認し、フィードバックを提供します。
ステップ 3: エージェントを評価する
ガイドラインから、少数の評価結果を含む品質レポートが自動的に生成されます。このレポートを 「品質」 タブで確認します。
承認された各ガイドラインは評価メトリクスとして使用されます。 生成されたリクエストごとに、ガイドラインを使用して応答が評価され、合格/不合格の評価が行われます。これらの評価は、上部に表示される評価スコアを生成するために使用されます。評価結果をクリックすると、詳細が表示されます。
品質レポートを使用して、エージェントをさらに最適化する必要があるかどうかを判断します。
(オプション)エージェントを最適化する
カスタムLLMは、エージェントのコスト最適化に役立ちます。Databricks 、エージェントを最適化するために、少なくとも100個の入力( Unity Catalogテーブルの100行、または手動で提供する100個のサンプル)を用意することを推奨しています。 入力データを増やすと、エージェントが学習できる知識ベースが拡大し、エージェントの品質と応答精度が向上します。
エージェントを最適化すると、Databricks は複数の異なる最適化戦略を比較して、最適化されたエージェントを構築およびデプロイします。これらの戦略にはDatabricks Geosを使用する基盤モデルのファインチューニングが含まれます。
エージェントを最適化するには:
-
[最適化] をクリックします。
-
[最適化の開始] をクリックします。
最適化には数時間かかる場合があります。最適化の進行中は、現在アクティブなエージェントへの変更はブロックされます。
-
最適化が完了したら、現在アクティブなエージェントとコストが最適化されたエージェントの比較を確認します。
-
これらの結果を確認したら、[ Deploy best model to an endpoint ] で最適なモデルを選択し、 Deploy をクリックします。
ステップ 4: エージェントを使用する
Databricks 全体のワークフローでエージェントをお試しください。
エージェントの使用を開始するには、 [使用] をクリックします。次のオプションがあります。
-
[ SQL で試す ] をクリックして SQL エディターを開き、
ai_queryを使用して新しいカスタム LLM エージェントに要求を送信します。 -
「パイプラインの作成」 をクリックして、スケジュールされた間隔で実行されるパイプラインをデプロイし、新しいデータに対してエージェントを使用します。パイプラインの詳細については、 LakeFlow Spark宣言型パイプラインを参照してください。
-
AI Playgroundを使用してチャット環境でエージェントをテストするには、 [Playground で開く] をクリックします。
権限を管理する
デフォルトでは、エージェントの作成者とワークスペース管理者のみがエージェントへのアクセス権限を持っています。他のユーザーがエージェントを編集したり照会したりできるようにするには、明示的に権限を付与する必要があります。
エージェントの権限を管理するには:
-
エージェント ページで、担当エージェントを開いてください。
-
上部の
 ケバブメニュー。
ケバブメニュー。 -
[権限の管理] をクリックします。
-
[権限設定] ウィンドウで、ユーザー、グループ、またはサービスプリンシパルを選択します。
-
付与する権限を選択してください:
- 管理可能 :エージェントの管理が可能で、権限の設定、エージェント構成の編集、品質の向上などを行うことができます。
- クエリ可能 : AI Playgroundおよび API を介してエージェントエンドポイントにクエリを実行できます。この権限しか持たないユーザーは、エージェントページでエージェントを表示または編集することはできません。
-
[ 追加 ] をクリックします。
-
保存 をクリックします。
2025 年 9 月 16 日より前に 作成されたエージェント エンドポイントの場合は、 [サービス エンドポイント] ページからエンドポイントに クエリ可能 権限を付与できます。
エージェント エンドポイントをクエリする
エージェントページで、右上の ![]() エージェント ステータス を参照して、デプロイされたエージェント エンドポイントを取得し、エンドポイントの詳細を確認します。
エージェント ステータス を参照して、デプロイされたエージェント エンドポイントを取得し、エンドポイントの詳細を確認します。
作成されたエージェント エンドポイントをクエリする方法は複数あります。AI Playground で提供されているコード例を開始点として使用します。
- エージェント ページで、 [使用] をクリックします。
- [プレイグラウンドで開く] をクリックします。
- Playground から コードを取得 をクリックします。
- エンドポイントの使用方法を選択します。
- データに適用 を選択して、エージェントを特定のテーブル列に適用する SQL クエリを作成します。
- curl を使用してエンドポイントをクエリするコード例として、 Curl API を選択します。
- Python を使用してエンドポイントと対話するためのコード例として、 Python API を選択します。
カスタムLLMでPDFを使用する
情報抽出およびカスタムLLMでは、PDFはまだネイティブにサポートされていません。ただし、UI 拡張機能を使用して PDF ファイルのフォルダをマークダウンに変換し、結果として得られるUnity Catalogテーブルをエージェント構築時の入力として使用することができます。 このワークフローでは、変換にai_parse_documentを使用します。次のステップに従ってください:
-
左側のナビゲーションペインで 「エージェント」 をクリックします。
-
情報抽出またはカスタム LLM ユースケースで、 [PDF の使用] をクリックします。
-
開いたサイドパネルで、次のフィールドを入力して、PDF を変換するための新しいワークフローを作成します。
- PDF または画像を含むフォルダーを選択 : 使用する PDF が含まれているUnity Catalogフォルダーを選択します。
- 宛先テーブルの選択 : 変換されたマークダウン テーブルの宛先スキーマを選択し、必要に応じて、下のフィールドのテーブル名を調整します。
- アクティブな SQLウェアハウスの選択 : ワークフローを実行する SQLウェアハウスを選択します。
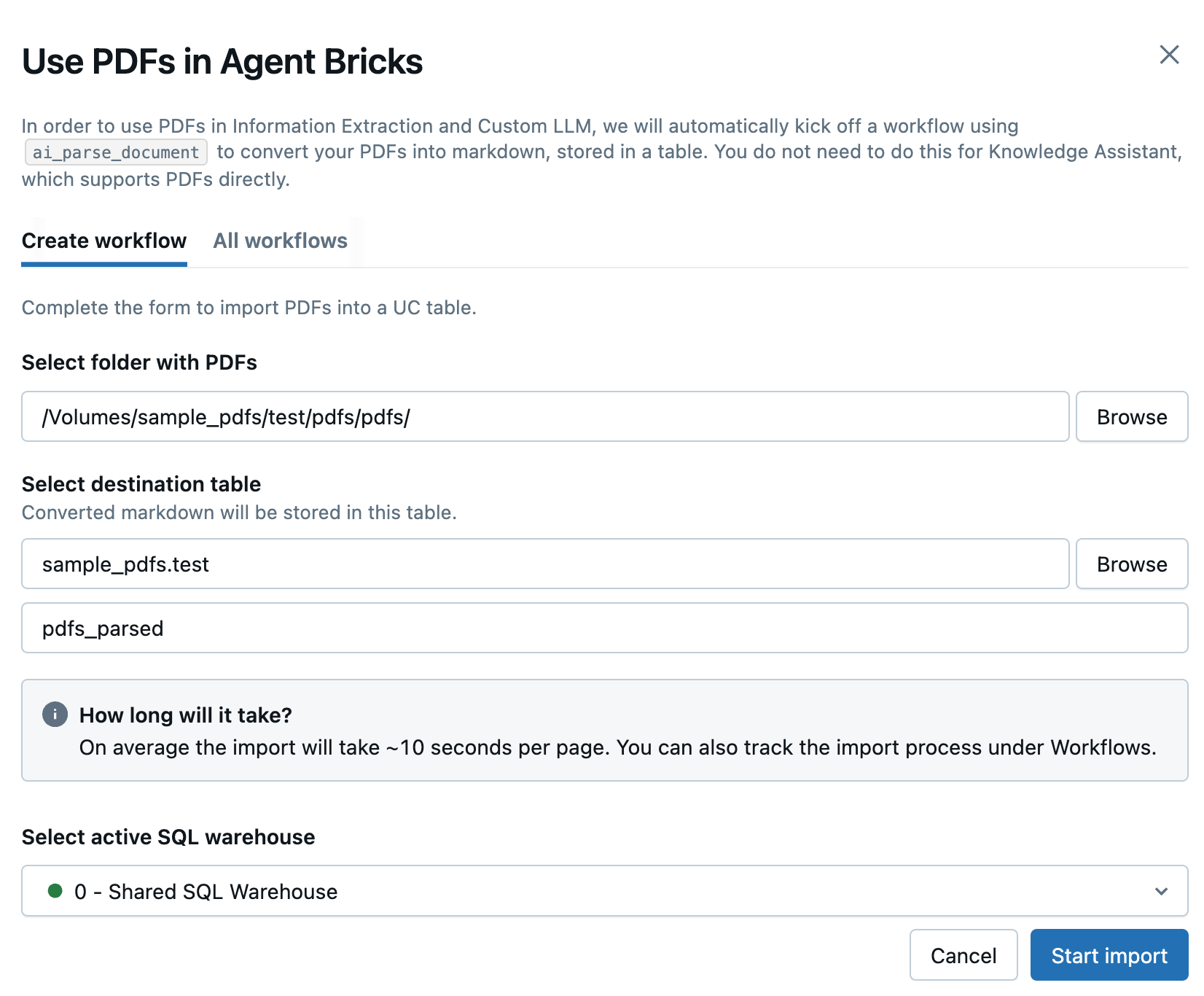
-
インポートの開始 をクリックします。
-
[ すべてのワークフロー ] タブにリダイレクトされ、すべての PDF ワークフローが一覧表示されます。このタブを使用して、ジョブのステータスを監視します。
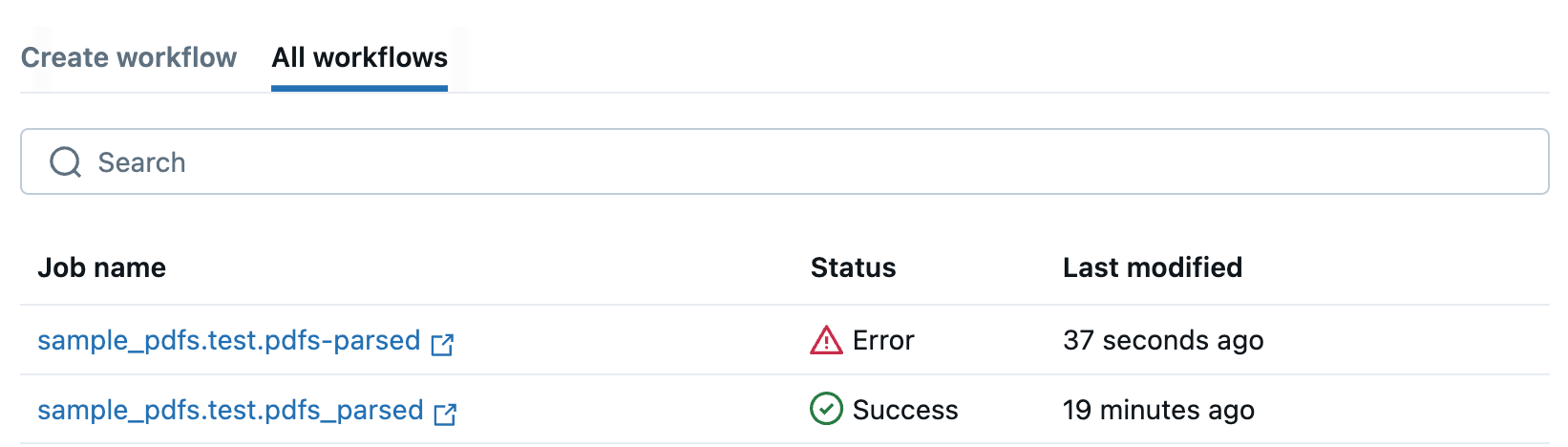
ワークフローが失敗した場合は、ジョブ名をクリックして開き、デバッグに役立つエラーメッセージを表示します。
-
ワークフローが正常に完了したら、ジョブ名をクリックしてカタログエクスプローラーでテーブルを開き、列を探索して理解します。
-
エージェントを設定する際は、 Unity Catalogテーブルを入力データとして使用してください。
制限
- Databricks では、エージェントを最適化するために、少なくとも 100 個の入力 ( Unity Catalog テーブルの 100 行または手動で提供された 100 個のサンプル) を推奨しています。 入力を追加すると、エージェントが学習できるナレッジ ベースが増え、エージェントの品質と応答精度が向上します。
- Unity Catalogテーブルを指定する場合、テーブル名に特殊文字 (
-など) を含めることはできません。 - 入力としてサポートされているデータ型は、
string、int、およびdoubleのみです。 - 現在、使用容量は 1 分あたり 100k の入力トークンと出力トークンに制限されています。
- セキュリティとコンプライアンスの強化が有効になっているワークスペースはサポートされていません。
- サーバレス出力制御ネットワークポリシーが制限されたアクセスモードでは、最適化が失敗する可能性があります。