Knowledge Assistantを使用して、ドキュメントに対して高品質のチャットボットを作成します
このページでは、Knowledge Assistant を使用して、ドキュメントに対してQ&Aチャットボットを作成し、対象分野の専門家からの自然言語フィードバックに基づいてその品質を向上させる方法について説明しています。
ナレッジアシスタントとは?
Knowledge Assistant を使用して、ドキュメントに関する質問に回答し、引用を含む高品質の応答を提供できるチャットボットを作成します。Knowledge Assistant は高度なAIを使用し、Instructed Retriever アプローチに従って、従来のRetrieval-augmented generation (RAG) アプローチの制限に対処し、提供されたドキュメントに基づいて最高品質の回答を提供します。複数の言語のドキュメントをサポートしています。
ナレッジアシスタント は、次のユースケースをサポートするのに最適です。
- 製品ドキュメントに基づいてユーザーの質問に回答します。
- 人事ポリシーに関する従業員の質問に回答します。
- サポートナレッジベースに基づいて顧客の問い合わせに回答します。
ナレッジアシスタントを使用すると、チャットエージェントの品質を向上させ、主題専門家からの自然言語フィードバックに基づいてその動作を調整できます。エクスペリエンスで直接質問とガイドラインを提供し、エージェントを共有することで、他のユーザーが共同作業してエージェントのパフォーマンスを向上できるようにします。
ナレッジアシスタントは、アプリケーションのダウンストリームで使用できるエージェントエンドポイントを作成します。例えば、以下の画像は、AI Playground でチャットしてエンドポイントと対話する方法を示しています。エージェントにドキュメントに関連する質問をすると、エージェントが引用で回答します。
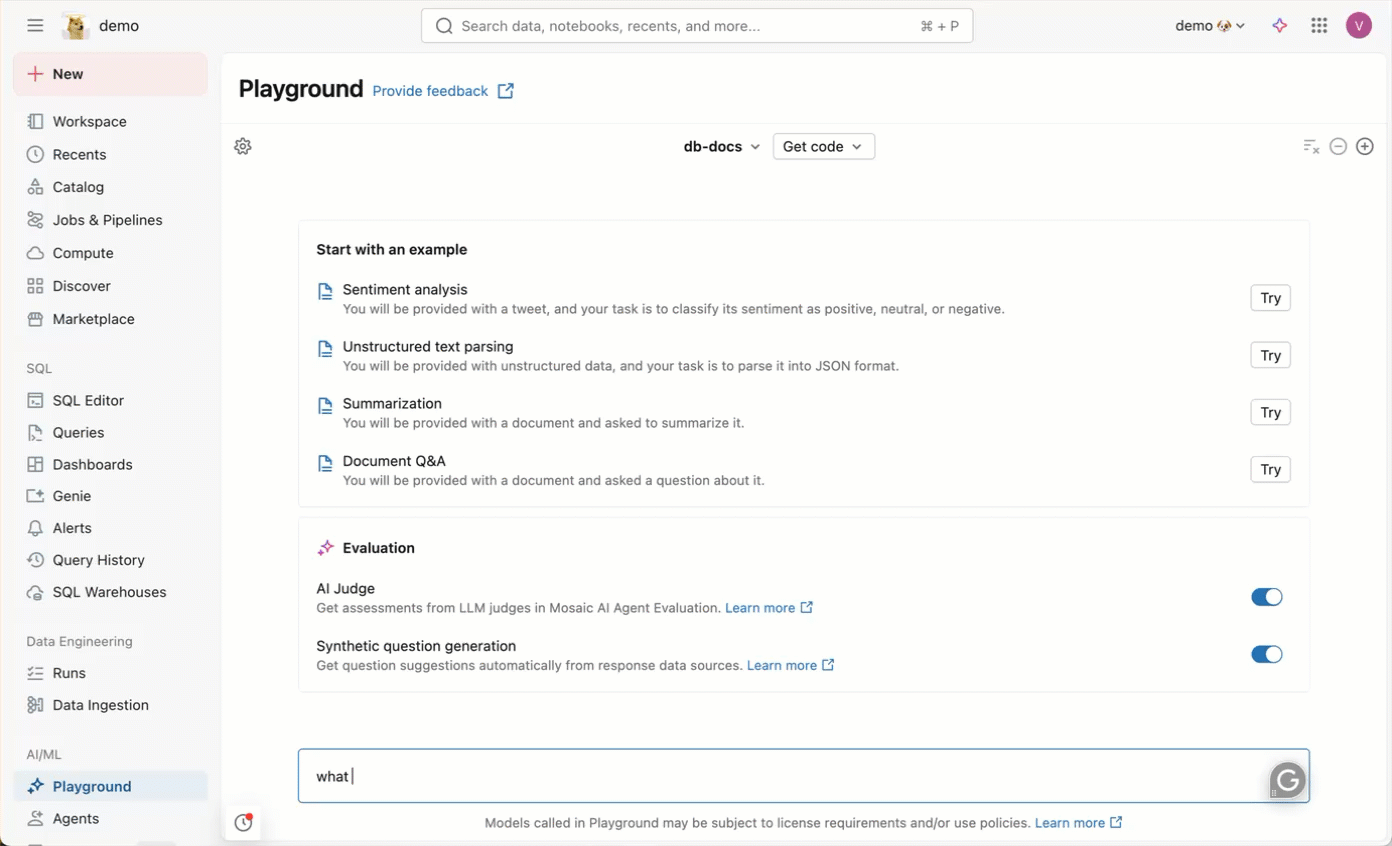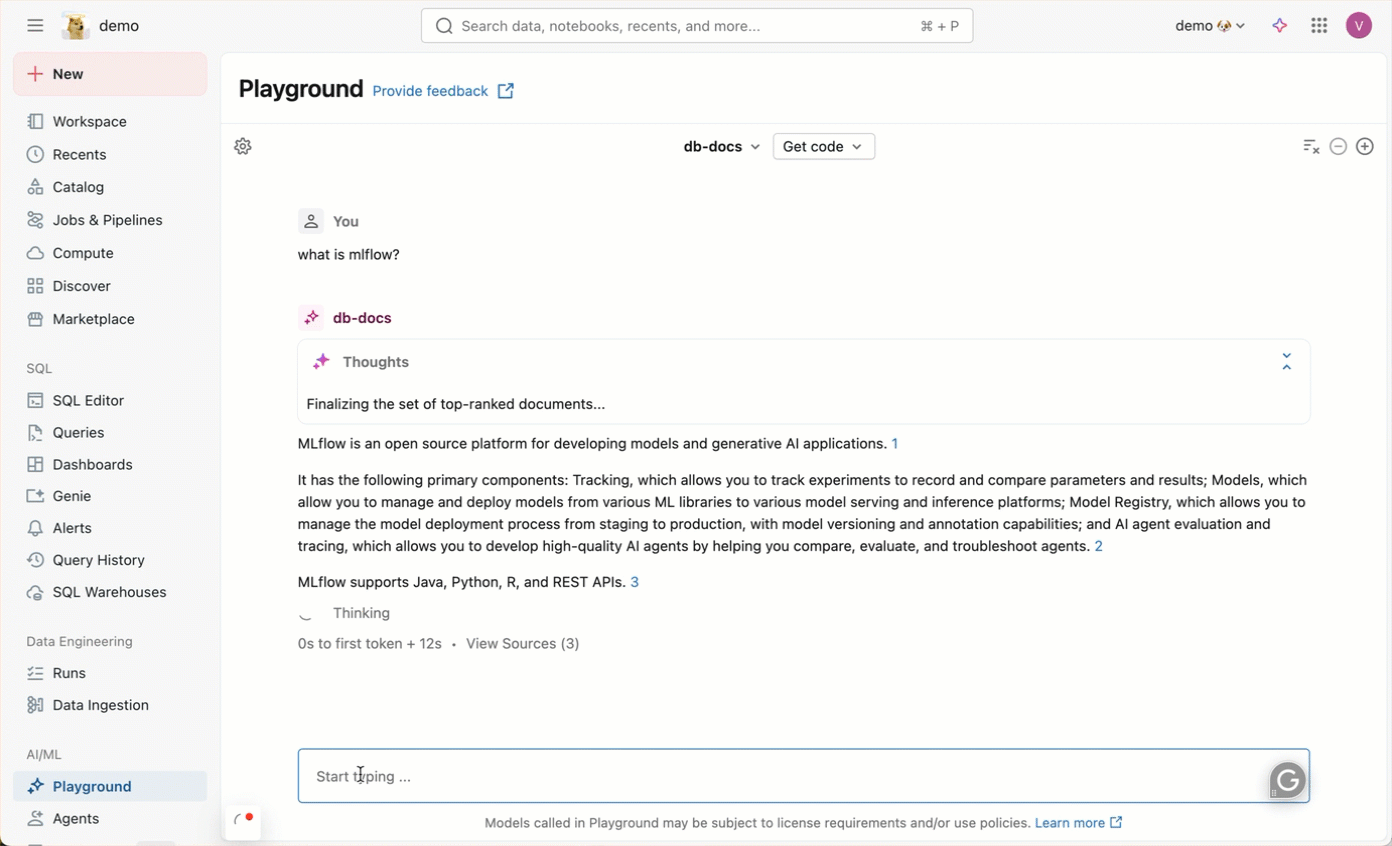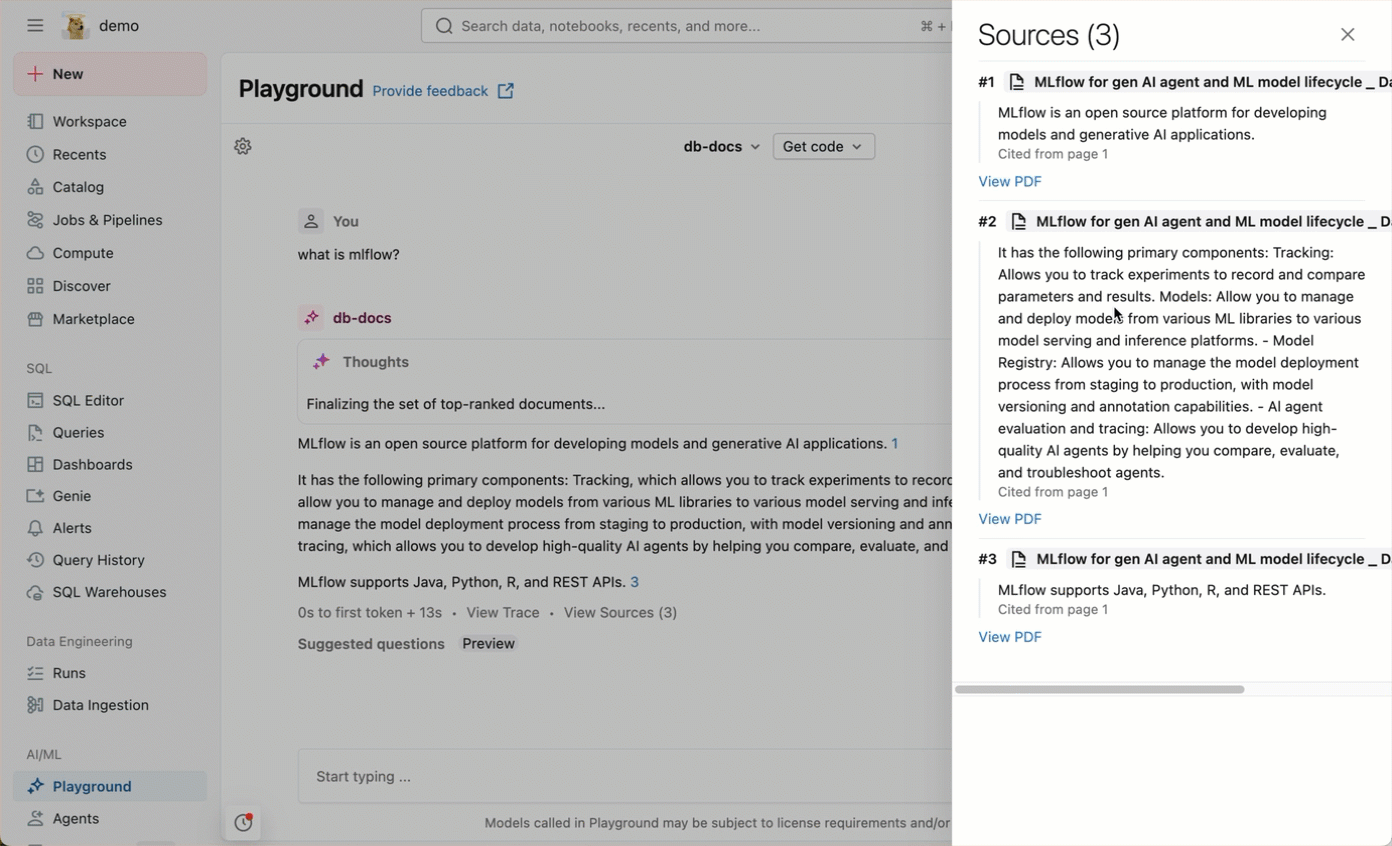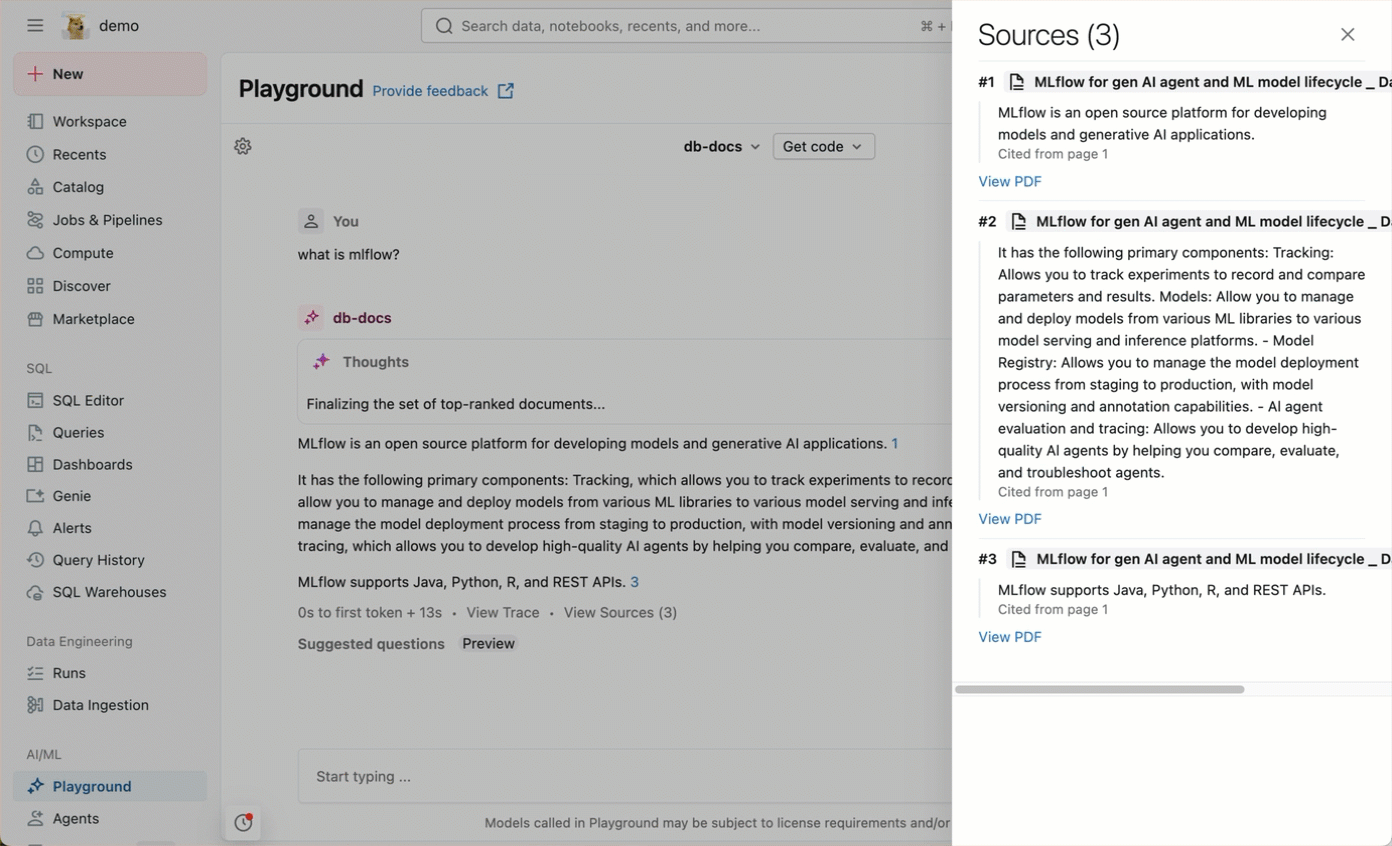
Knowledge Assistant は、デフォルトストレージを使用して、各エージェントを動かす一時的なデータ変換、モデル チェックポイント、および内部メタデータを保存します。エージェントが削除されると、エージェントに関連付けられているすべてのデータはデフォルトストレージから削除されます。
要件
-
以下を含むワークスペースです。
- サーバレスコンピュートが利用可能です(Unity Catalogが有効なワークスペースではデフォルトで有効になっています)。
- Unity Catalogが有効です。「Unity Catalog のワークスペースを有効にする」を参照してください。
- Model Servingへのアクセス。
- 非ゼロの予算を持つサーバレス使用ポリシーへのアクセス。
-
サポートされているいずれかのリージョンにあるワークスペース。
-
使用準備ができた入力データが必要です。以下から選択できます。
- Unity Catalogボリュームまたはボリュームディレクトリ内のファイル。サポートされているファイル形式は、txt、pdf、md、ppt/pptx、およびdoc/docxです。
- ファイル列を持つ Unity Catalog テーブルです。スキーマの要件と構成の詳細については、ステップ 1: エージェントを構成する を参照してください。
- 次の埋め込みモデルのいずれかを使用するAI Searchインデックス:
databricks-gte-large-en、databricks-bge-large-en、またはdatabricks-qwen3-embedding-0-6b。AI Searchインデックスの作成を参照してください。
ナレッジアシスタントエージェントの作成
ワークスペースの左側のナビゲーションペインで、![]() エージェント に移動します。 [エージェントを作成] をクリックし、 [ナレッジアシスタント] を選択します。
エージェント に移動します。 [エージェントを作成] をクリックし、 [ナレッジアシスタント] を選択します。
ステップ 1: エージェントを構成します
エージェントを構成し、質問に回答するために使用するナレッジソースを提供します。
-
名前 フィールドに、エージェントの名前を入力します。
-
説明 フィールドで、エージェントが実行できる操作を説明します。
-
ナレッジソース パネルで、ナレッジソースを追加します。ボリューム内のファイル、テーブル内のファイル、またはAI Searchインデックスを提供することを選択できます。
- Files in a Volume
- Files in a Table
- AI Search Index
Unity Catalogボリュームまたはディレクトリ内のファイルについては、次のファイルタイプがサポートされています:txt、pdf、md、ppt/pptx、およびdoc/docx。50 MBを超えるファイルは、取り込み中に自動的にスキップされ、ナレッジベースには含まれません。500ページを超えるPDF、DOC、DOCX、PPT、およびPPTXファイルもスキップされます。PowerPointファイルの場合、各スライドは1ページとしてカウントされます。TXTおよびMDファイルにはページ制限はありません。
- 「 タイプ 」で、「 ボリューム内のファイル 」を選択します。
- ソース フィールドで、Unity Catalog のボリュームまたはファイルを含むボリューム ディレクトリを選択します。
- 名前 フィールドに、ナレッジ ソースの名前を入力します。
- 「 コンテンツの説明 」で、ナレッジソースに含まれるコンテンツを説明し、このデータソースをいつ使用するかをエージェントが理解できるようにします。
Unity Catalogテーブル内のファイルを知識ソースとして使用できます。Databricksコネクタを使用してSharePointまたはGoogle Driveから取り込まれたテーブルは、自動的に想定される形式で生成されます。JiraやConfluenceなどの他のソースから取り込まれたテーブルの場合、必要なスキーマに合わせてデータを変換する必要がある場合があります。
The Unity Catalog table must meet the following requirements:
- The table is either a streaming table or a table with Change data feed enabled.
- The table contains a content column of
BINARYorSTRINGtype. - The table contains a
metadataor_metadatacolumn ofSTRUCTtype with the following fields:file_path: stringfile_name: stringfile_size: longfile_modification_time: timestamp
- タイプ で、 テーブル内のファイル を選択します。
- ソース フィールドで、データを含む Unity Catalog テーブルを選択します。
- (オプション) ファイルコンテンツ列 フィールドで、ファイルコンテンツを含む列を選択します。指定しない場合、これは
content列にデフォルト設定されます。BINARYとSTRINGタイプの列のみが表示されます。 - 名前 フィールドに、ナレッジ ソースの名前を入力します。
- 「 コンテンツの説明 」で、ナレッジソースに含まれるコンテンツを説明し、このデータソースをいつ使用するかをエージェントが理解できるようにします。
AI Search indexes are only supported if the index uses one of the following embedding models: databricks-gte-large-en, databricks-bge-large-en, or databricks-qwen3-embedding-0-6b. When creating your index, ensure you select one of these embedding models. For more information, see Create an AI Search index.
- **タイプ**で、**AI Searchインデックス**を選択します。
- ソース フィールドで、エージェントに提供するインデックスを選択します。
- 名前 フィールドに、ナレッジ ソースの名前を入力します。
- Doc URI Column で、情報のソースへのリンクまたは参照を含む列を選択します。エージェントは、これを引用に使用します。
- テキスト列 フィールドで、エージェントに取得させる生のテキストを含む列を指定します。
- 「 コンテンツの説明 」で、ナレッジソースに含まれるコンテンツを説明し、このデータソースをいつ使用するかをエージェントが理解できるようにします。
-
(オプション)さらに知識ソースを追加する場合は、[**知識ソースの追加**]をクリックします。最大10個の知識ソースを提供できます。
-
(オプション) 指示 フィールドで、エージェントが応答する方法のガイドラインを指定します。
-
エージェントの作成 をクリックします。
エージェントを作成し、提供したナレッジソースを同期するまで、最大数時間かかる場合があります。エージェントの準備が整うと、右側のパネルに同期されたナレッジソースが表示されます。
ナレッジソースにファイルを更新または追加した場合、エージェントが変更を反映できるように、** ![]() 同期**をクリックする必要があります。同期は増分で実行されます。例えば、以前に同期された Unity Catalog ボリュームに新しいファイルを追加した場合、同期は新しく追加されたファイルのみを処理します。
同期**をクリックする必要があります。同期は増分で実行されます。例えば、以前に同期された Unity Catalog ボリュームに新しいファイルを追加した場合、同期は新しく追加されたファイルのみを処理します。
ナレッジアシスタントに対してCAN MANAGE権限を持つユーザーは、ナレッジソースを同期できます。
ステップ 2:エージェントをテストします。
エージェントのビルドが完了したら、チャットしてテストしてください。エージェントは、そのナレッジソースに関連する質問に対して引用で応答する必要があります。
- ビルド タブでエージェントと直接チャットを開始します。
- (省略可能) [Playground で開く] をクリックして、AI Playgroundでチャットすることもできます。
- エージェントの質問を入力します。
- その応答を評価します:
- 「 View thoughts 」をクリックすると、エージェントが質問にどのように回答したかを確認できます。
- 完全なトレースを表示するには、**[トレースを表示]** をクリックしてください。開発プロセス中に品質評価を追跡するために、UIでトレースにラベルを追加できます。
- エージェントが参照として引用しているファイルを確認するには、**[ソースを表示]**をクリックします。これにより、確認できるソースのリストが表示されたサイドパネルが開きます。
エージェントのパフォーマンスに満足している場合は、エージェントをそのまま使用し続けてください。
ステップ 3: 品質を改善する
ナレッジアシスタントは、自然言語フィードバックに基づいてエージェントの動作を調整できます。構成ページを通じて専門家からのフィードバックを収集し、エージェントの品質を向上させます。エージェントのラベル付きデータを収集すると、その品質と動作を向上させることができます。
例 タブで、ユーザーが質問する質問やエージェントが過去に間違った質問を追加します。または、Unity Catalogのテーブルから直接ラベル付きデータをインポートすることも可能です。
-
ラベル付けする質問を追加します:
- 質問を追加するには、 + 追加 をクリックします。
- 「**質問の追加**」モーダルで、質問を入力します。
- 追加 をクリックします。質問がUIに表示されます。
- 評価したいすべての質問を追加するまで繰り返します。
- 質問を削除するには、ケバブメニューをクリックし、 削除 をクリックします。
-
質問を追加し終えたら、エージェントを他の人と共有してレビューしてもらうことで、高品質なラベル付きデータセットの構築に役立てることができます。右上隅で、ケバブメニュー
 をクリックして、権限を管理します。
をクリックして、権限を管理します。専門家がアクセスしてフィードバックを提供できるように、次の権限を付与する必要があります。
- エージェント構成ページからのCAN_MANAGE権限
-
ナレッジアシスタントの構成ページへのリンクを共有して、専門家からフィードバックを収集してください。
-
データをラベル付けするには、質問をクリックし、表示されるペインで ガイドライン を追加します。ガイドラインは保存されるとすぐに適用されます。
-
パフォーマンスの向上を確認するために、構成ページまたはAI Playgroundでエージェントを再度テストします。必要に応じて、動作の改善を続けるためにさらに質問とガイドラインを追加します。
(オプション) ラベル付けされたデータのインポートとエクスポート
Unity Catalogテーブルから新しい質問やフィードバックを直接インポートするには:
-
「 インポート 」をクリックします。
-
**ソース**フィールドで、ラベル付けされたデータを含むUnity Catalogテーブルを選択します。
テーブルは次のスキーマを持つ必要があります。
-
eval_id:string -
request:string -
guidelines:arrayitems:string
-
metadata:string -
tags:string
-
-
「 インポート 」をクリックします。
新しい質問とガイドラインは、右側のラベル付けされたデータテーブルにマージされます。
ラベル付きデータをUnity Catalogテーブルとしてエクスポートするには:
- 「**エクスポート**」をクリックします。
- スキーマ フィールドで、データを保存するUnity Catalogスキーマの場所を選択します。
- **テーブル名**フィールドに、テーブル名を入力します。
- エクスポートをクリックします。
ラベル付けされたデータで新しいテーブルが作成されます。
ナレッジソースを管理
ナレッジアシスタントを作成した後、エージェントを再作成することなく、ナレッジソースの追加、削除、更新が可能です。ナレッジアシスタントの作成者のみがナレッジソースの追加または削除を行うことができます。CAN MANAGE権限を持つすべてのユーザーは、ナレッジソースの名前と説明を更新し、ナレッジソースを同期できます。
新しいソースの追加、既存のソースの削除、別の説明の更新など、複数の変更を一度に下書きし、 保存して更新 をクリックすると、すべての変更を同時に適用できます。
ナレッジソースを追加
- エージェント設定ページで、 ソース タブに移動します。
- 既存のナレッジ ソースカードの下にある「 + 追加 」をクリックします。
- 追加するナレッジソースのタイプ(Unity Catalogボリューム内のファイル、Unity Catalogテーブル内のファイル、またはAI Searchインデックス)を選択し、ステップ1: エージェントを構成するの説明に従って構成します。
- [保存して更新] をクリックします。
エージェントは新しいナレッジソースの同期を開始します。既存のナレッジソースとそのデータは影響を受けません。
ナレッジアシスタントごとに最大10個のナレッジソースを提供できます。ファイルソースを追加すると取り込みジョブが開始され、データ量によっては時間がかかる場合があります。
ナレッジソースを削除する
- エージェント設定ページで、 ソース タブに移動します。
- 削除したいナレッジ ソースカードにカーソルを合わせ、右上のごみ箱アイコン
 をクリックします。
をクリックします。 - 確認ダイアログで、 [確認] をクリックしてソースを削除します。
- [保存して更新] をクリックします。
ナレッジソースおよびそれに関連付けられたデータはエージェントから削除されます。この操作は、ソースを再追加するとデータの再取り込みが必要になるため、簡単に元に戻せません。
最後に残ったナレッジソースは削除できません。ナレッジアシスタントには、常に少なくとも1つのナレッジソースが必要です。
ナレッジ・ソースの詳細を更新します
既存のナレッジソースの名前と説明を更新できます。これらの詳細は、エージェントが各ソースをいつ使用すべきかを理解するのに役立ちます。
- エージェント設定ページで、 ソース タブに移動します。
- 編集したいナレッジソースカードにカーソルを合わせ、鉛筆アイコンをクリックします。
- 名前 または 説明 フィールドを更新します。
- [保存して更新] をクリックします。
権限を管理します。
デフォルトでは、エージェントの作成者とワークスペースの管理者のみがエージェントに対する権限を持っています。他のユーザーがエージェントを編集またはクエリできるようにするには、明示的に権限を付与する必要があります。
エージェントの権限を管理するには:
-
[**エージェント**] ページで、エージェントを開きます。
-
上部の
ケバブメニューをクリックします。 -
[アクセス許可を管理] をクリックします。
-
**権限設定** ウィンドウで、ユーザー、グループ、またはサービスプリンシパルを選択します。
-
付与する権限を選択してください:
- 管理可能 : 権限の設定、エージェント構成の編集、品質の向上など、エージェントの管理が可能です。
- クエリ可能 : AI Playground および API を介したエージェントエンドポイントのクエリを許可します。この権限のみを持つユーザーは、エージェントページでエージェントを表示または編集できません。
-
[ 追加 ] をクリックします。
-
保存 をクリックします。
ナレッジアシスタントの作成者のみがナレッジソースを追加または削除できます。ナレッジアシスタントに対するCAN MANAGE権限を持つ任意のユーザーは、ナレッジソースを同期し、ナレッジソース名と説明を更新できます。
エージェントエンドポイントをクエリする
エージェントページで、**Endpoint**をクリックしてエージェントエンドポイントを開き、詳細を確認します。
作成されたナレッジアシスタントエンドポイントをクエリするには複数の方法があります。AI Playgroundで提供されているコード例を開始点として使用してください:
- プレイグラウンドで開く をクリックします。
- Playground から コードを取得 をクリックします。
- エンドポイントの使用方法を選択してください:
- curl を使用してエンドポイントをクエリするコード例として、 Curl API を選択します。
- Pythonを使用してエンドポイントを操作するコード例については、 Python API を選択してください。
Databricks SDKを使用してナレッジアシスタントを管理
Databricks SDK for Python を使用して、ナレッジアシスタントとそれらのナレッジソースをプログラムで作成および管理できます。利用可能なAPI操作の完全なリストについては、Knowledge Assistants APIリファレンスを参照してください。
ナレッジアシスタントを作成する
次の例は、表示名、説明、および指示を使用して新しいナレッジアシスタントを作成します。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.knowledgeassistants import KnowledgeAssistant
w = WorkspaceClient()
knowledge_assistant = KnowledgeAssistant(
display_name="<display-name>",
description="<description>",
instructions="<instructions>",
)
created = w.knowledge_assistants.create_knowledge_assistant(knowledge_assistant=knowledge_assistant)
print(created)
<display-name>、<description>、および<instructions>をナレッジアシスタントの値に置き換えます。
ナレッジソースを管理
SDKを使用して、既存のナレッジアシスタント上でナレッジソースを追加、削除、更新できます。
ナレッジソースを追加
次の例では、Unity Catalog ボリューム内のファイルから既存のナレッジソースアシスタントにナレッジソースを追加します。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.knowledgeassistants import KnowledgeSource, FilesSpec
w = WorkspaceClient()
files_source = KnowledgeSource(
display_name="<knowledge-source-name>",
description="<knowledge-source-description>",
source_type="files",
files=FilesSpec(
path="<volume-path>",
),
)
created_source = w.knowledge_assistants.create_knowledge_source(
parent="knowledge-assistants/<knowledge-assistant-id>",
knowledge_source=files_source,
)
print(created_source)
代わりにAI Searchインデックスのソースを追加するには、IndexSpecを使用します:
from databricks.sdk.service.knowledgeassistants import KnowledgeSource, IndexSpec
index_source = KnowledgeSource(
display_name="<knowledge-source-name>",
description="<knowledge-source-description>",
source_type="index",
index=IndexSpec(
index_name="<catalog.schema.index-name>",
text_col="<text-column>",
doc_uri_col="<doc-uri-column>",
),
)
created_source = w.knowledge_assistants.create_knowledge_source(
parent="knowledge-assistants/<knowledge-assistant-id>",
knowledge_source=index_source,
)
print(created_source)
ナレッジソースを削除する
次の例では、ナレッジアシスタントからナレッジソースを削除します。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w.knowledge_assistants.delete_knowledge_source(
name="knowledge-assistants/<knowledge-assistant-id>/knowledge-sources/<knowledge-source-id>",
)
ナレッジソースを更新
次の例は、既存のナレッジ ソースの表示名と説明を更新します。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.knowledgeassistants import KnowledgeSource
w = WorkspaceClient()
updated_source = w.knowledge_assistants.update_knowledge_source(
name="knowledge-assistants/<knowledge-assistant-id>/knowledge-sources/<knowledge-source-id>",
knowledge_source=KnowledgeSource(
display_name="<new-name>",
description="<new-description>",
),
update_mask="display_name,description",
)
print(updated_source)
update_maskで許可されているフィールド:display_name、description。
ナレッジソースの同期
ファイルベースのナレッジソース (Unity Catalogボリュームやテーブルなど) でファイルを追加または更新した後、同期をトリガーして、ナレッジアシスタントのインデックスを最新のファイルコンテンツで更新します。
インデックスベースのナレッジソースは自動的に更新されるため、手動での同期は必要ありません。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w.knowledge_assistants.sync_knowledge_sources(
name="knowledge-assistants/<knowledge-assistant-id>",
)
複数のワークスペース間でナレッジアシスタントを移行する
SDKを使用して、ナレッジアシスタントをあるワークスペースから別のワークスペースにレプリケートできます。次の例では、ソースワークスペースからナレッジアシスタントを取得し、そのナレッジソースとともにターゲットワークスペースで再作成します。
ターゲット ワークスペースで参照されるナレッジ ソース (AI Search インデックスや Unity Catalog ボリュームなど) は、ナレッジ ソースを作成する前にターゲット ワークスペースに存在している必要があります。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.knowledgeassistants import (
Example,
KnowledgeAssistant,
KnowledgeSource,
IndexSpec,
FilesSpec,
)
# Retrieve the knowledge assistant from the source workspace
source_client = WorkspaceClient()
ka = source_client.knowledge_assistants.get_knowledge_assistant(name="<source-knowledge-assistant-name>")
print(ka.display_name, ka.description, ka.instructions)
# Set up the client for the target workspace
target_client = WorkspaceClient(
host="<target-workspace-url>",
token="<target-workspace-token>",
)
# Create the knowledge assistant in the target workspace
knowledge_assistant = KnowledgeAssistant(
display_name=ka.display_name,
description=ka.description,
instructions=ka.instructions,
)
created = target_client.knowledge_assistants.create_knowledge_assistant(knowledge_assistant=knowledge_assistant)
print(created)
# Re-create knowledge sources in the target workspace
index_source = KnowledgeSource(
display_name="<knowledge-source-name>",
description="<knowledge-source-description>",
source_type="index",
index=IndexSpec(
index_name="<catalog.schema.index-name>",
text_col="<text-column>",
doc_uri_col="<doc-uri-column>",
),
)
files_source = KnowledgeSource(
display_name="<knowledge-source-name>",
description="<knowledge-source-description>",
source_type="files",
files=FilesSpec(
path="<volume-path>",
),
)
created_index_source = target_client.knowledge_assistants.create_knowledge_source(
parent=created.name,
knowledge_source=index_source,
)
print(created_index_source)
created_files_source = target_client.knowledge_assistants.create_knowledge_source(
parent=created.name,
knowledge_source=files_source,
)
print(created_files_source)
# Re-create examples in the target knowledge assistant
for ex in source_client.knowledge_assistants.list_examples(parent=ka.name):
example = source_client.knowledge_assistants.get_example(name=ex.name)
target_client.knowledge_assistants.create_example(
parent=created.name,
example=Example(
question=example.question,
guidelines=example.guidelines,
),
)
ソースおよびターゲットワークスペースの適切な値で、プレースホルダーの値を置き換えてください。<source-knowledge-assistant-name> は knowledge-assistants/<knowledge-assistant-id> の形式に従います。
ナレッジアシスタントを評価する
このノートブックでは、キュレーションされた評価データセットとカスタムスコアラーを使用して、ナレッジアシスタントを評価する方法をデモンストレーションします。
制限事項
- 50 MBを超えるファイルは、取り込み中に自動的にスキップされ、知識ベースには含まれません。
- 500ページを超える PDF、DOC、DOCX、PPT、および PPTX ファイルは、取り込み中にスキップされます。PowerPoint ファイル(PPT、PPTX)の場合、各スライドは1ページとしてカウントされます。TXT および MD ファイルにはページ制限がありません。取り込みには
ai_parse_documentを使用します。これはドキュメントあたり500ページの制限があります。 - アンダースコア (
_) またはピリオド (.) で始まる名前のファイルは、インジェスト中に自動的にスキップされ、ナレッジベースには含まれません。 - Unity Catalog テーブルのファイルを使用するナレッジソースでは、選択したコンテンツ列のみが取り込まれます。テーブルのナレッジソース内の他の列は使用されません。
- 次の埋め込みモデルのいずれかを使用するAI Searchインデックスのみがサポートされています:
databricks-gte-large-en、databricks-bge-large-en、またはdatabricks-qwen3-embedding-0-6bです。