レビュー アプリを使用して、AI アプリ (MLflow 2) の人間によるレビューを行う
Databricksでは、AIアプリの評価とモニタリングにMLflow 3を使用することをお勧めします。このページでは、MLflow 2 の Agent Evaluation について説明します。
- MLflow 3 での評価とモニタリングの概要については、エージェントの評価とモニタリングを参照してください。
- MLflow 3への移行に関する情報については、Agent EvaluationからMLflow 3への移行を参照してください。
- このトピックに関する MLflow 3 情報については、「ドメイン専門家のフィードバック」を参照してください。
この記事では、レビューアプリを使用して主題のエキスパート(SME)からフィードバックを収集する方法について説明します。レビューアプリを使用して、次のことができます。
- 利害関係者が本番運用前のAIアプリとチャットし、フィードバックを提供できるようにします。
- Unity Catalog の Delta テーブルによってサポートされる評価データセットを作成します。
- 専門家を活用して、その評価データセットを拡大および改善します。
- SMEを活用して本番運用のトレースにラベルを付け、AI アプリの品質を理解します。

人間による評価では何が行われますか?
Databricksレビューアプリは、関係者が対話できる環境を用意します。つまり、会話したり、質問したり、フィードバックを提供したりできます。
レビューアプリを使用する主な方法は 2 つあります:
- ボットとチャット :推論テーブルで質問、回答、フィードバックを収集して、AIアプリのパフォーマンスをさらに分析できます。このようにして、レビューアプリは、アプリケーションが提供する回答の品質と安全性を確保するのに役立ちます。
- セッション内の応答にラベル付けする :MLFlowの実行に保存されているラベル付けセッションで、対象分野の専門家(SME)から フィードバック と 期待 を収集します。これらのラベルを評価データセットに同期させることも可能です。
要件
- 開発者は、権限を設定し、レビューアプリを構成するために
databricks-agentsSDKをインストールする必要があります。
%pip install databricks-agents==0.16.0
dbutils.library.restartPython()
-
ボットとのチャットの場合:
- 推論テーブルは、エージェントを提供しているエンドポイントで有効にする必要があります。
- 各人間のレビュー担当者は、レビューアプリワークスペースにアクセスできるか、SCIMを使用してDatabricksアカウントに同期されている必要があります。次のセクション、レビューアプリを使用するためのアクセス許可を設定するを参照してください。
-
ラベリングセッションの場合:
- 各人間のレビュー担当者は、レビューアプリのワークスペースにアクセスできる必要があります。
レビューアプリを使用するためのアクセス許可を設定する
- ボットとチャットするには、人間のレビュー担当者はワークスペースへのアクセス権を必要としません。
- ラベル付けセッションの場合、人間のレビュアーはワークスペースへのアクセスを必要とします。
「Chat with the bot」の権限を設定する
- ワークスペースにアクセスできないユーザーの場合、アカウント管理者はアカウント レベルの SCIM プロビジョニングを使用して、ユーザーとグループを ID プロバイダーから Databricks アカウントに自動的に同期します。また、これらのユーザーとグループを手動で登録して、 Databricksで ID を設定するときにアクセス権を付与することもできます。 SCIM を使用して ID プロバイダーからユーザーとグループを同期するを参照してください。
- レビューアプリを含むワークスペースにすでにアクセスできるユーザーの場合、追加の構成は必要ありません。
次のコード例は、agents.deployを介してデプロイされたモデルに対してユーザーに権限を付与する方法を示しています。usersパラメーターは、Eメールアドレスのリストを受け取ります。
from databricks import agents
# Note that <user_list> can specify individual users or groups.
agents.set_permissions(model_name=<model_name>, users=[<user_list>], permission_level=agents.PermissionLevel.CAN_QUERY)
ワークスペース内のすべてのユーザーに権限を付与するには、users=["users"] を設定します。
ラベリングセッションの権限を設定します。
ラベル付けセッションを作成し、assigned_users引数を指定すると、ユーザーには適切な権限(エクスペリメントへの書き込みアクセスとデータセットへの読み取りアクセス)が自動的に付与されます。詳細については、以下のラベル付けセッションを作成してレビューのために送信するを参照してください。
レビューアプリを作成
自動的に使用する agents.deploy()
agents.deploy()を使用してAIアプリをデプロイすると、レビューアプリが自動的に有効化され、デプロイされます。コマンドからの出力には、レビューアプリのURLが表示されます。AIアプリ(「エージェント」とも呼ばれます)のデプロイに関する情報については、AIアプリケーション用のエージェントをデプロイする (Model Serving)を参照してください。
エンドポイントが完全にデプロイされるまで、エージェントはレビューアプリのUIに表示されません。
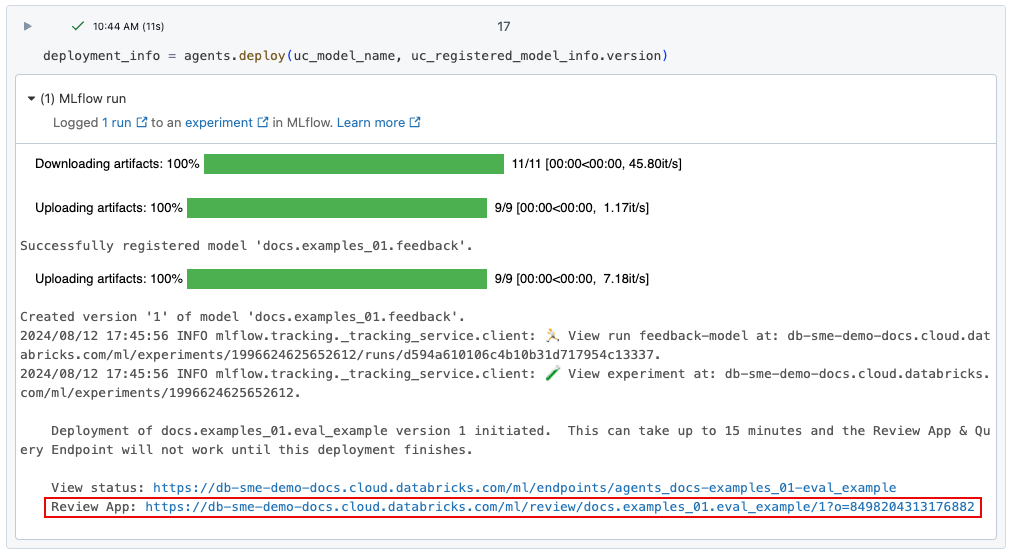
レビューアプリのUIへのリンクを失った場合は、get_review_app() を使用して見つけることができます。
import mlflow
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
mlflow.set_experiment("same_exp_used_to_deploy_the_agent")
my_app = review_app.get_review_app()
print(my_app.url)
print(my_app.url + "/chat") # For "Chat with the bot".
Python APIを手動で使用する
以下のコード スニペットは、レビューアプリを作成し、それをボットとのチャット用のモデルサービング エンドポイントに関連付ける方法を示しています。ラベリング セッションの作成については、以下を参照してください。
- 評価データセットにラベルを付けるため、ラベリングセッションを作成し、レビューのために送信します。
- トレースのラベリングについては、トレースに関するフィードバックを収集してください。このため、ライブエージェントは不要です。
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# TODO: Replace with your own serving endpoint.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
print(my_app.url + "/chat") # For "Chat with the bot".
コンセプト
データセット
データセットは、AI アプリケーションを評価するために使用される例のコレクションです。データセット レコードには、AI アプリケーションへの入力と、オプションで 期待 値 (expected_facts や guidelinesなどのグラウンド トゥルース ラベル) が含まれます。データセットは MLFlow エクスペリメントにリンクされており、mlflow.evaluate()への入力として直接使用できます。データセットは、Unity Catalog の Delta テーブルによってサポートされ、Delta テーブルによって定義されたアクセス許可を継承します。データセットを作成するには、データセットの作成を参照してください。
入力列とエクスペクテーション列のみを示す評価データセットの例:

評価データセットのスキーマは以下のとおりです。
列 | データ型 | 説明 |
|---|---|---|
dataset_record_id | string | レコードの一意の識別子。 |
inputs | string | 評価への入力としてJSONシリアル化された |
エクスペクテーション | string | JSONシリアル化された |
create_time | timestamp | レコードが作成された時間です。 |
作成者 | string | レコードを作成したユーザー。 |
last_update_time | timestamp | レコードが最後に更新された時刻です。 |
last_updated_by | string | レコードを最後に更新したユーザー。 |
source | struct | データセットレコードのソース。 |
source.human | struct | ソースが人間からの場合に定義されます。 |
source.human.user_name | string | レコードに関連付けられているユーザーの名前。 |
source.document | string | ドキュメントからレコードが合成されたときに定義されます。 |
source.document.doc_uri | string | ドキュメントの URI。 |
source.document.content | string | ドキュメントの内容。 |
source.trace | string | レコードがトレースから作成されたときに定義されます。 |
source.trace.trace_id | string | トレースの一意の識別子。 |
タグ | map | データセットレコードのキーと値のタグ。 |
ラベル付けセッション
LabelingSessionは、レビューアプリのUIでSMEによってラベル付けされるトレースまたはデータセットレコードの有限セットです。トレースは、本番運用のアプリケーションの推論テーブル、または MLFlow エクスペリメントのオフライン・トレースから取得できます。 結果は MLFlow 実行として保存されます。ラベルは MLFlow トレースに Assessment秒として保存されます。「エクスペクテーション」のラベルは、評価データセットに同期して戻すことができます。
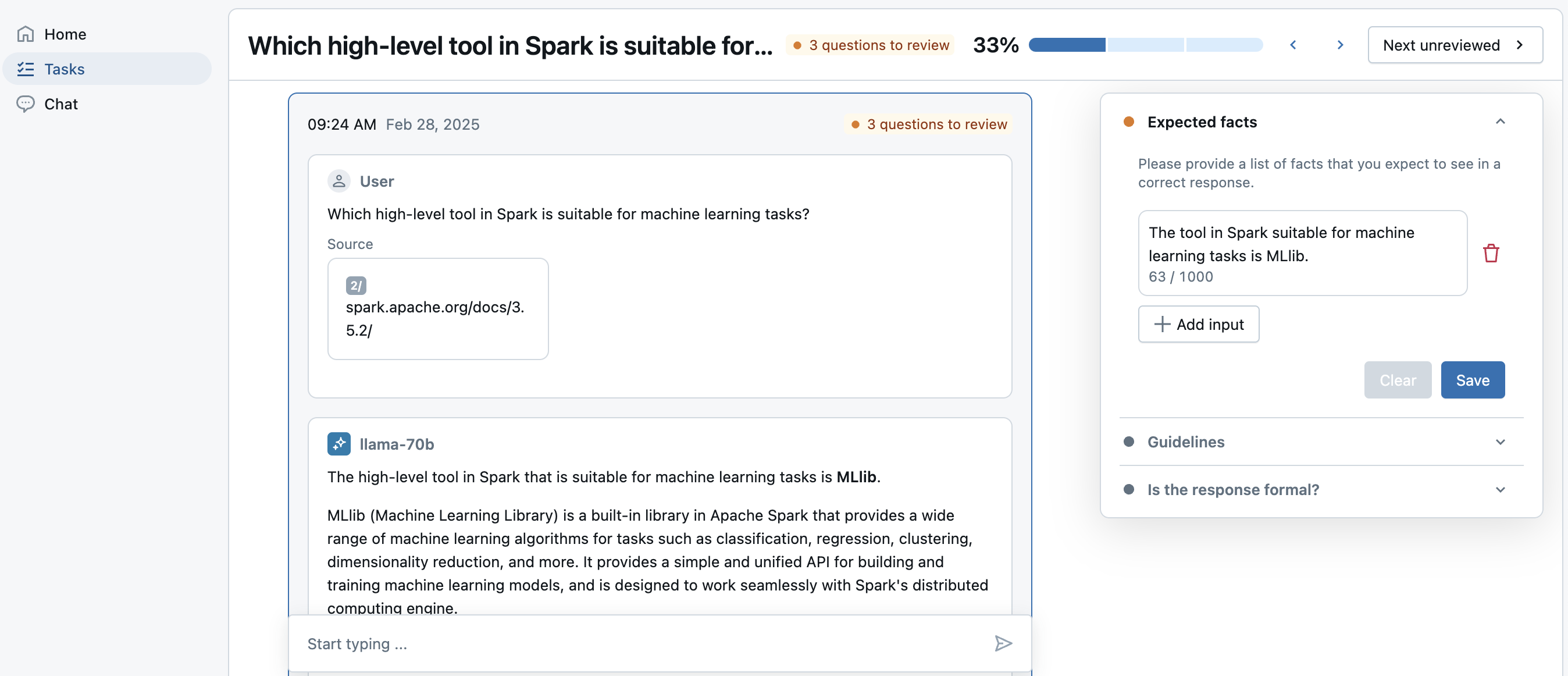
評価とラベル
専門家がトレースにラベルを付けると、評価がTrace.info.assessmentsフィールドの下にトレースに書き込まれます。Assessmentには2つのタイプがあります:
expectation:正しいトレースが持つべきものを表すラベル。例えば:expected_factsをexpectationラベルとして使用でき、これは理想的な応答に含まれるべき事実を表します。これらのexpectationラベルは評価データセットに同期して戻すことができ、それによりmlflow.evaluate()と共に使用できます。feedback:トレースに関する「高く評価」や「低く評価」のようなシンプルなフィードバック、または自由形式のコメントを表すラベル。特定のMLflowトレースの人間による評価であるため、タイプfeedbackのAssessmentは評価データセットでは使用されません。これらの評価はmlflow.search_traces()で読み取ることができます。
データセット
このセクションでは、次の操作を行う方法について説明します。
- データセットを作成し、専門家なしで評価に使用します。
- より良い評価データセットをキュレーションするために、専門家にラベリングセッションを依頼してください。
データセットを作成
次の例では、データセットを作成し、評価を挿入します。合成評価でデータセットにシードするには、「評価セットを合成する」を参照してください。
from databricks.agents import datasets
import mlflow
# The following call creates an empty dataset. To delete a dataset, use datasets.delete_dataset(uc_table_name).
dataset = datasets.create_dataset("cat.schema.my_managed_dataset")
# Optionally, insert evaluations.
# The `guidelines` specified here are saved to the `expectations` field in the dataset.
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the capital of France?"}]},
"guidelines": ["The response must be in English", "The response must be clear, coherent, and concise"],
}]
dataset.insert(eval_set)
このデータセットのデータは、Unity Catalog の Delta テーブルによってサポートされ、カタログエクスプローラ に表示されます。
名前付きガイドライン (辞書を使用) は、現在ラベル付けセッションではサポートされていません。
評価用データセットの使用
次の例では、Unity Catalog からデータセットを読み取り、評価データセットを使用してシンプルなシステムプロンプトエージェントを評価します。
import mlflow
from mlflow.deployments import get_deploy_client
# Define a very simple system-prompt agent to test against our evaluation set.
@mlflow.trace(span_type="AGENT")
def llama3_agent(request):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
*request["messages"]
]
}
)
evals = spark.read.table("cat.schema.my_managed_dataset")
mlflow.evaluate(
data=evals,
model=llama3_agent,
model_type="databricks-agent"
)
ラベル付けセッションを作成し、レビューのために送信する
次の例では、ReviewApp.create_labeling_session を使用して上記のデータセットからLabelingSession を作成します。セッションの構成
ReviewApp.label_schemasを利用して専門家からguidelines・expected_factsを回収するフィールド。また、ReviewApp.create_label_schema を使用してカスタムラベルスキーマを作成することもできます
-
ラベル付けセッションを作成する際、割り当てられたユーザーは次のとおりです:
- MLFlow エクスペリメントへの書き込み権限が付与されていること。
- レビューアプリに関連付けられているモデルサービングエンドポイントにQUERY権限が付与されている場合。
-
ラベリングセッションにデータセットを追加すると、割り当てられたユーザーには、ラベリングセッションのシードに使用されるデータセットのデルタテーブルへの SELECT 権限が付与されます。
ワークスペース内のすべてのユーザーに権限を付与するには、assigned_users=["users"] を設定します。
from databricks.agents import review_app
import mlflow
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# You can use the following code to remove any existing agents.
# for agent in list(my_app.agents):
# my_app.remove_agent(agent.agent_name)
# Add the llama3 70b model serving endpoint for labeling. You should replace this with your own model serving endpoint for your
# own agent.
# NOTE: An agent is required when labeling an evaluation dataset.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
# Create a labeling session and collect guidelines and/or expected-facts from SMEs.
# Note: Each assigned user is given QUERY access to the serving endpoint above and write access.
# to the MLFlow experiment.
my_session = my_app.create_labeling_session(
name="my_session",
agent="llama-70b",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas = [review_app.label_schemas.GUIDELINES, review_app.label_schemas.EXPECTED_FACTS]
)
# Add the records from the dataset to the labeling session.
# Note: Each assigned user above is given SELECT access to the UC delta table.
my_session.add_dataset("cat.schema.my_managed_dataset")
# Share the following URL with your SMEs for them to bookmark. For the given review app linked to an experiment, this URL never changes.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
この時点で、上記のURLを対象分野の専門家(SME)に送信できます。
専門家がラベリングを行っている間、以下のコードでラベリングのステータスを表示できます:
mlflow.search_traces(run_id=my_session.mlflow_run_id)
ラベリングセッションのエクスペクテーションをデータセットに同期する
専門家がラベリングを完了した後、LabelingSession.sync_expectationsを使用してexpectationラベルをデータセットに同期できます。タイプexpectationのラベルの例には、GUIDELINES、EXPECTED_FACTS、またはタイプexpectationを持つ独自のカスタムラベルスキーマがあります。
my_session.sync_expectations(to_dataset="cat.schema.my_managed_dataset")
display(spark.read.table("cat.schema.my_managed_dataset"))
この評価データセットを使用できます。
eval_results = mlflow.evaluate(
model=llama3_agent,
data=dataset.to_df(),
model_type="databricks-agent"
)
トレースに関するフィードバックを収集する
このセクションでは、次のいずれかから取得できるMLflowトレースオブジェクトのラベルを収集する方法について説明します:
- MLflow エクスペリメントまたは実行。
- 推論テーブル
- 任意のMLFlow Pythonトレースオブジェクト。
MLFlowエクスペリメントまたは実行からフィードバックを収集する
この例では、SMEによってラベル付けされる一連のトレースを作成します。
import mlflow
from mlflow.deployments import get_deploy_client
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Create a trace to be labeled.
with mlflow.start_run(run_name="llama3") as run:
run_id = run.info.run_id
llama3_agent([{"content": "What is databricks?", "role": "user"}])
llama3_agent([{"content": "How do I set up a SQL Warehouse?", "role": "user"}])
トレースのラベルを取得し、それらからラベリングセッションを作成できます。この例では、エージェントの応答に関する「フォーマリティ」フィードバックを収集するために、単一のラベルスキーマを持つラベリングセッションを設定します。専門家からのラベルは、MLFlow Trace 上に 評価 として保存されます。
スキーマ入力のその他のタイプについては、databricks-agents SDKを参照してください。
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# Use the run_id from above.
traces = mlflow.search_traces(run_id=run_id)
formality_label_schema = my_app.create_label_schema(
name="formal",
# Type can be "expectation" or "feedback".
type="feedback",
title="Is the response formal?",
input=review_app.label_schemas.InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True
)
my_session = my_app.create_labeling_session(
name="my_session",
# NOTE: An `agent` is not required. If you do provide an Agent, your SME can ask follow up questions in a converstion and create new questions in the labeling session.
assigned_users=["email1@company.com", "email2@company.com"],
# More than one label schema can be provided and the SME will be able to provide information for each one.
# We use only the "formal" schema defined above for simplicity.
label_schemas=["formal"]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
# Share the following URL with your SMEs for them to bookmark. For the given review app, linked to an experiment, this URL will never change.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
専門家によるラベリングが完了すると、結果のトレースと評価は、ラベリングセッションに関連付けられている実行の一部になります。
mlflow.search_traces(run_id=my_session.mlflow_run_id)
これらの評価を使用して、モデルを改善したり、評価データセットを更新したりできます。
推論テーブルでフィードバック応答を見つける
エンドポイントで推論テーブルが有効になっている場合、Databricks はフィードバック応答を評価ログビューの次の場所に書き込みます。
{catalog_name}.{schema_name}.{model_name}_payload_assessment_logs_view
このビューは、非推奨の_payload_assessment_logsテーブルを置き換えます。完全なスキーマと非推奨のステータスについては、「エージェント推論テーブル: リクエストおよび評価ログ (非推奨)」を参照してください。
推論テーブルからのフィードバックを収集する
この例では、推論テーブル(リクエストペイロードログ)から直接ラベル付けセッションにトレースを追加する方法を示します。
# CHANGE TO YOUR PAYLOAD REQUEST LOGS TABLE
PAYLOAD_REQUEST_LOGS_TABLE = "catalog.schema.my_agent_payload_request_logs"
traces = spark.table(PAYLOAD_REQUEST_LOGS_TABLE).select("trace").limit(3).toPandas()
my_session = my_app.create_labeling_session(
name="my_session",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas=[review_app.label_schemas.EXPECTED_FACTS]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
print(my_session.url)
ノートブックの例
次のノートブックは、Agent Evaluationにおけるデータセットとラベリングセッションのさまざまな使用方法を示しています。