AIエージェントメモリ
メモリにより、AI エージェントは会話の前の部分や以前の会話の情報を記憶できます。これにより、エージェントはコンテキストに応じた応答を提供し、時間の経過とともにパーソナライズされたエクスペリエンスを構築できるようになります。フルマネージド Postgres OLTP データベースであるDatabricks Lakebase を使用して、会話の状態と履歴を管理します。
要件
- ワークスペースでDatabricks Apps有効にします。 Databricks Appsワークスペースと開発環境をセットアップするを参照してください。
- Lakebase インスタンス。Postgres データベースを取得を参照してください。
短期記憶と長期記憶
短期記憶は単一の会話セッション内のコンテキストをキャプチャしますが、長期記憶は複数の会話にわたる重要な情報を抽出して保存します。どちらか一方または両方のタイプのメモリを使用してエージェントを構築できます。
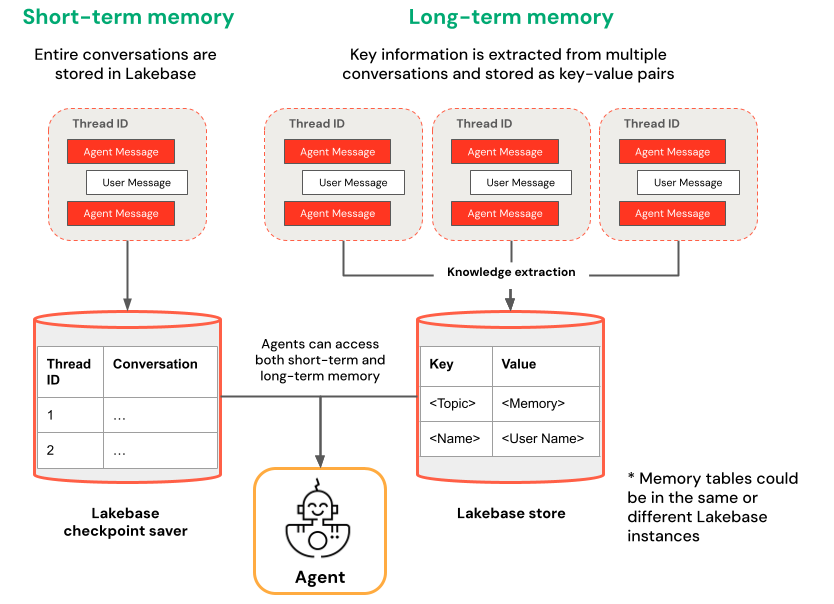
短期記憶 | 長期記憶 |
|---|---|
スレッドIDとチェックポイントを使用して、単一の会話セッションでコンテキストをキャプチャします。 セッション中のフォローアップの質問の文脈を維持する | 複数のセッションにわたって重要な知識を自動的に抽出して保存 過去の好みに基づいてやり取りをパーソナライズする 時間の経過とともに応答を改善するユーザーに関する知識ベースを構築する |
始めましょう
Databricks Appsでメモリを備えたエージェントを作成するには、事前に構築されたアプリ テンプレートを複製し、 「 AIエージェントを作成してアプリにデプロイする」で説明されている開発ワークフローに従います。 次のテンプレートは、一般的なフレームワークを使用してエージェントに短期および長期のメモリを追加する方法を示しています。
LangGraph
短期記憶と長期記憶の両方を備えたLangGraphエージェントを構築するには、 agent-langgraph-advancedテンプレートをクローンします。このテンプレートは、スレッドベースの会話コンテキストやセッション全体にわたる永続的なユーザー情報などの永続的な状態管理のために、LangGraph とLakebaseの組み込みチェックポイントを使用します。
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-langgraph-advanced
OpenAI エージェント SDK
短期記憶機能を備えた OpenAI Agents SDK を使用したエージェントを構築するには、 agent-openai-advancedテンプレートをクローンします。このテンプレートは、永続的な状態管理にLakebaseを使用しており、自動的な会話履歴管理機能を備えたステートフルな複数ターン会話を可能にします。
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-advanced
長時間実行されるエージェントのバックグラウンド実行
Databricks Appsは、HTTP接続のタイムアウトを約300秒に設定しています。バックグラウンド実行により、この制限を超えたエージェントタスクは、接続が切断された後も実行を継続できます。クライアントは別のエンドポイントから結果を取得するか、再接続してストリーミングを再開します。
高度なテンプレート( agent-langgraph-advancedとagent-openai-advanced )は、 databricks-ai-bridgeのLongRunningAgentServerを介して、短期記憶と長時間バックグラウンド実行で基本テンプレートを拡張し、以下の機能を提供します。
- バックグラウンドモード :リクエスト本文に
background=trueを設定すると、レスポンスIDが即座に返され、エージェントが非同期で実行されます。 - エンドポイントの取得 :最終結果を取得するには
GET /responses/{id}を送信するか、進行中の実行へのストリーミング接続を開きます。 - 再開可能なストリーミング : サーバーから送信されるすべてのイベントには
sequence_numberが含まれます。接続が切断された場合は、starting_after=Nで再接続して次のイベントから再開してください。 - TASK_TIMEOUT_SECONDS バックグラウンドタスクの実行時間を制限する環境変数。これは、単一のHTTPリクエストにのみ適用される、Databricks Appsの120秒のHTTP接続タイムアウトとは無関係です。(デフォルト:1時間)
高度なテンプレートのREADMEには、5つのクライアントモードのリクエスト例が示されています。
- Invoke : 標準の非ストリーミング POST。
- ストリーム : 標準のストリーミング POST。
- バックグラウンド、次にポーリング :
background=trueで POST し、完了するまでGET /responses/{id}ポーリングします。 - バックグラウンドストリーミング、ストリーム経由で再開 :
background=trueとstream=trueで POST ; 接続が切断された場合は、stream=trueでGET /responses/{id}に再接続します。 - バックグラウンドストリーミング、ポーリングによる再開 :同じ開始条件。接続が切断された場合は、最終結果を取得するために
GET /responses/{id}をポーリングします。
エージェントをデプロイしてクエリする
エージェントにメモリを構成したら、 「 AIエージェントを作成してアプリにデプロイする」の手順に従ってエージェントをローカルで実行し、評価して、 Databricks Appsにデプロイします。