Lakeflowコネクトの標準コネクタ
このページでは、 Databricks Lakeflow Connectの標準コネクタについて説明し、マネージド コネクタと比較してより高いレベルのインジェスト パイプラインのカスタマイズを提供します。
ETLスタックのレイヤー
一部のコネクタは ETL スタックの 1 つのレベルで動作します。たとえば、 Databricks 、Salesforce などのエンタープライズ アプリケーションやSQL Serverなどのデータベース用のフルマネージド コネクタを提供します。 その他のコネクタは、ETL スタックの複数のレイヤーで動作します。たとえば、構造化ストリーミングで標準コネクタを使用して完全なカスタマイズを行うことも、 Lakeflow Spark宣言型パイプラインでより管理されたエクスペリエンスを使用することもできます。
Databricks では、最も管理されたレイヤーから始めることをお勧めします。要件を満たさない場合 (たとえば、データソースをサポートしていない場合) は、次のレイヤーにドロップダウンします。
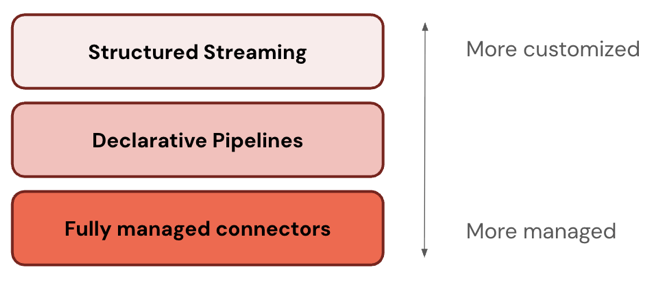
次の表では、インジェスト製品の 3 つのレイヤーを、最もカスタマイズ可能なものから最も管理しやすいものの順に説明しています。
層 | 説明 |
|---|---|
Apache Spark 構造化ストリーミングは、 Spark APIsを使用した exactly-once 処理保証を備えたエンドツーエンドのフォールト トレランスを提供するストリーミング エンジンです。 | |
Lakeflow Spark宣言型パイプラインは構造化ストリーミングに基づいて構築されており、データパイプラインを作成するための宣言型フレームワークを提供します。 データに対して実行する変換を定義でき、 Lakeflow Spark宣言型パイプラインがオーケストレーション、モニタリング、データ品質、エラーなどを管理します。 したがって、構造化ストリーミングよりも自動化が進み、オーバーヘッドが少なくなります。 | |
フルマネージド コネクタはLakeflow Spark宣言型パイプライン上に構築されており、最も人気のあるデータ ソースのさらなる自動化を提供します。 これらは、 Lakeflow Spark宣言型パイプライン機能を拡張し、ソース固有の認証、 CDC 、エッジケース処理、長期APIメンテナンス、自動再試行、自動スキーマ進化なども組み込みます。 したがって、サポートされているデータ ソースに対してさらに高度な自動化が提供されます。 |
コネクタを選択する
次の表に、データソースとパイプラインのカスタマイズのレベル別の標準インジェスト コネクタを示します。 完全に自動化されたインジェスト エクスペリエンスを実現するには、代わりに マネージド コネクタ を使用します。
クラウドオブジェクトストレージからの増分取り込みの SQL 例では CREATE STREAMING TABLE 構文を使用します。SQL ユーザーにスケーラブルで堅牢なインジェスト エクスペリエンスを提供するため、 COPY INTOの代替手段として推奨されます。
ソース | その他のカスタマイズ | いくつかのカスタマイズ | さらなる自動化 |
|---|---|---|---|
クラウドオブジェクトストレージ |
| Lakeflow Spark宣言型パイプラインを使用したAuto Loader
|
|
SFTPサーバー | (Python、SQL) | N/A | N/A |
Apache Kafka |
| Kafkaソースを使用したLakeflow Spark宣言型パイプライン
|
|
Amazon Kinesis |
| Kinesisソースを使用したLakeflow Spark宣言型パイプライン
|
|
Google Pub/Sub |
| Lakeflow Spark宣言型パイプライン (Pub/Sub ソース付き)
|
|
Apache パルサー |
| Lakeflow Spark宣言型パイプライン with Pulsar ソース
|
|
インジェスト スケジュール
インジェスト パイプラインは、定期的なスケジュールで実行するか、継続的に実行するように構成できます。