Lakeflowコネクト のマネージド コネクタ
Lakeflowコネクト のマネージド コネクタは、さまざまなリリース状態にあります。
このページでは、 SaaSアプリケーションおよびデータベースからデータを取り込むためのDatabricks LakeFlow Connectのマネージド コネクタの概要を説明します。 結果として得られる取り込みパイプラインはUnity Catalogによって管理され、サーバレス コンピュートとLakeFlow Spark宣言型パイプラインによって強化されます。 マネージド コネクタは、効率的な増分読み取りと書き込みを活用して、データの取り込みをより高速かつスケーラブルでコスト効率の高いものにすると同時に、データを下流での使用に備えて最新の状態に維持します。
コネクタの種類
-
- SaaSコネクタ
- Salesforce、HubSpot、Jira、Workdayなど、エンタープライズ向けSaaSアプリケーションからデータを取り込みます。
-
- データベースコネクタ(CDC)
- チェンジデータ キャプチャを使用して、 MySQL 、 PostgreSQL 、 SQL Serverなどのリレーショナル データベースからデータを取り込みます。
アーキテクチャ
コネクタの種類ごとに、それぞれ異なる構成部品があります。SaaSコネクタは、接続、取り込みパイプライン、および宛先テーブルを使用します。データベースコネクタには、継続的な変更の捕捉をサポートするための取り込みゲートウェイとステージングストレージも含まれています。詳細については、 LakeFlow ConnectのSaaSコネクタおよびLakeFlow Connectのデータベース コネクタを参照してください。
オーケストレーション
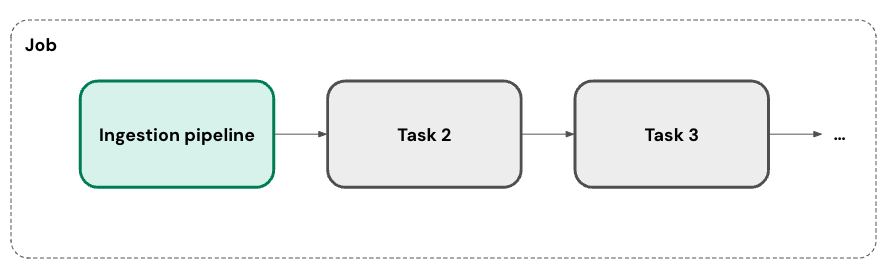
インジェスト パイプラインは、1 つ以上のカスタム スケジュールで実行できます。パイプラインに追加するスケジュールごとに、 Lakeflow Connect によってその ジョブ が自動的に作成されます。 インジェスト パイプラインは、ジョブ内のタスクです。オプションで、ジョブにタスクを追加できます。
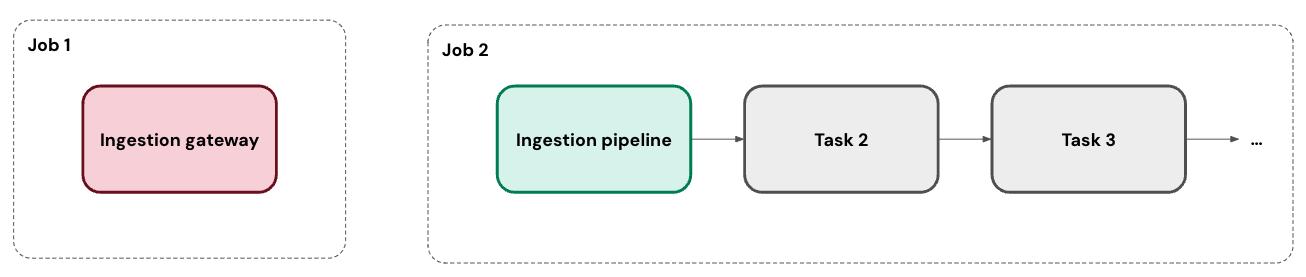
データベース コネクタの場合、取り込み ゲートウェイは、連続タスクとして独自のジョブで実行されます。
増分取り込み
Lakeflow Connect では、増分インジェストを使用してパイプラインの効率を向上させます。 パイプラインの最初の実行時に、選択したすべてのデータがソースから取り込まれます。並行して、ソース データへの変更を追跡します。パイプラインの後続の各実行では、その変更追跡を使用して、可能な場合は前の実行から変更されたデータのみを取り込みます。
正確なアプローチは、データソースで利用可能なものによって異なります。 たとえば、変更の追跡とチェンジデータキャプチャ (CDC) の両方を SQL Serverで使用できます。 これに対し、Salesforce コネクタは、設定されたオプションのリストからカーソル列を選択します。
一部のソースまたは特定のテーブルでは、現時点では増分取り込みはサポートされていません。Databricks は、増分サポートの対象範囲を拡大する予定です。
ネットワーキング
SaaS アプリケーションまたはデータベースに接続するには、いくつかのオプションがあります。
- SaaSアプリケーション用のコネクタは、ソースのAPIに手を差し伸べます。また、サーバレスのエグレスコントロールとも自動的に互換性があります。
- クラウド データベースのコネクタは、Private Link を介してソースに接続できます。あるいは、ワークスペースに、データベースをホストしている VNet または VPC とピアリングされている仮想ネットワーク (VNet) または仮想プライベート クラウド (VPC) がある場合は、その中にゲートウェイをデプロイできます。
- オンプレミス データベース用のコネクタは、AWS Direct Connect や Azure ExpressRoute などのサービスを使用して接続できます。
配備
宣言型自動化バンドルを使用すると、取り込みパイプラインをデプロイできます。これにより、ソース管理、コードレビュー、テスト、継続的インテグレーションおよびデリバリー(CI/CD)などのベストプラクティスが可能になります。バンドルはDatabricks CLIを使用して管理され、開発、ステージング、本番運用などのさまざまなターゲット ワークスペースで実行できます。
障害復旧
フルマネージドサービスとして、 Lakeflowコネクト は可能な限り問題から自動的に回復することを目指しています。 たとえば、コネクタに障害が発生すると、エクスポネンシャル バックオフで自動的に再試行されます。
ただし、エラーによって介入が必要になる可能性があります (たとえば、資格情報の有効期限が切れた場合など)。このような場合、コネクタはカーソルの最後の位置を格納することで、データの欠落を回避しようとします。その後、可能な場合は、パイプラインの次の実行でその位置から再開できます。
モニタリング
LakeFlow Connectパイプラインの維持に役立つ堅牢なアラートとモニタリングを提供します。 これには、イベント ログ、クラスター ログ、パイプライン ヘルス メトリクス、およびデータ品質メトリクスが含まれます。 system.billing.usageテーブルを使用してコストを追跡し、パイプラインの使用状況を監視することもできます。「マネージド インジェスチョン パイプラインのコストを監視する」を参照してください。
データベース コネクタの場合、イベント ログを使用してゲートウェイの進行状況をリアルタイムで監視できます。「イベント ログを使用してインジェスト ゲートウェイの進行状況を監視する」を参照してください。
外部サービスへの依存
DatabricksのSaaS、データベース、およびその他のフルマネージド コネクタは、接続先のアプリケーション、データベース、または外部サービスのアクセシビリティ、互換性、安定性に依存します。Databricks はこれらの外部サービスを制御していないため、変更、更新、およびメンテナンスに対する影響力は (あったとしても) 制限されています。
外部サービスに関連する変更、中断、または状況により、コネクタの運用が妨げられたり、非現実的になったりした場合、Databricks はそのコネクタの保守を中止または中止することができます。Databricksは、該当するドキュメントの更新を含む、メンテナンスの中止または中止を顧客に通知するために合理的な努力を払います。