Google スプレッドシートで Databricks データをクエリする
このページでは、Databricks ワークスペースからデータをクエリし、 Google スプレッドシート用の Databricks コネクタ を使用して Google スプレッドシートにインポートする方法について説明します。テーブルを直接選択し、 SQLクエリを作成し、追加し、ピボット テーブルを作成できます。 コネクタはすべてのクエリを自動的にインポートとして保存するため、結果を更新して既存のクエリを再利用できます。
前提条件
インポート方法を選択する
DatabricksからGoogleスプレッドシートにデータをインポートするには、テーブルを選択するか、SQLクエリを記述します。データがインポートされると、クエリがシートに紐付けられます。このコネクタは、Google スプレッドシートの制限である 1,000 万セル までのインポートをサポートしています。
シート名を変更すると、マッピングが壊れます。名前の変更を処理する方法については、 「制限事項」を参照してください。
「データの選択」を使用してUnity Catalogメトリクス ビューをインポートする場合、 Unity Catalogメトリクスはピボットされたデータを表すため、ビューはピボット テーブルとしてのみインポートできます。
適用済みの表の書式設定を削除したり変更したりしないでください。Googleスプレッドシートのテーブル識別子は、インポートを更新するために使用されます。書式設定を削除すると、更新エラーが発生します。
開始するには、インポート方法を選択してください:
- Select data
- Write a SQL query
Databricks のテーブルからデータをインポートするには、次の手順を実行します。
-
Google Sheets Databricks Connector のサイドバーで、 [新規インポート] の下の [インポート方法] で [データの選択] を選択します。
-
[カタログ] の下で、カタログ、スキーマ、およびテーブルのドロップダウン メニューを使用して、インポートするテーブルを検索します。
-
必要に応じて、 アセット名 を更新してこのインポートの名前を変更します。
-
オプションで、 [フィールド] で、含める列または除外する列を選択します。
-
オプションでピボット テーブルとしてインポートすることもできます。
-
フィルターを追加するには、 [フィルター] の下の [+ フィルター] をクリックします。フィルターを適用する 列 と フィルター タイプ を選択します。
-
必要に応じて、 「行数の制限」 をオンにして、インポートする行数の上限を設定できます。この制限はデフォルトで有効になっており、1,000行に設定されています。
-
「出力先」 で、クエリ結果を新しいシートに保存するか、現在のシートに保存するかを選択します。
- 新しいシートを選択した場合は、シートの名前を入力してください。
- 現在のシートを選択した場合は、データの追加を開始するセルを指定してください。
-
シートにデータを入力するには、 [保存してインポート] をクリックします。
新しい SQL クエリを記述するには、次の手順を実行します。
-
Google Sheets Databricks Connector のサイドバーで、 [新規インポート] の下にある [SQL を書き込む] を選択します。
-
Databricks では、クエリを識別できるように名前を入力することをお勧めします。
-
カタログ、スキーマ、テーブルを参照できます。
-
クエリ テキスト に SQL クエリを入力します。
-
オプションでクエリを追加できます。
-
「出力先」 で、クエリ結果を新しいシートに保存するか、現在のシートに保存するかを選択します。
- 新しいシートを選択した場合は、シートの名前を入力してください。
- 現在のシートを選択した場合は、データの追加を開始するセルを指定してください。
-
[保存してインポート] をクリックしてクエリを実行し、シートに入力します。
クエリの実行が15分後にタイムアウトしました。クエリがこの制限を超えた場合、自動的にキャンセルされます。大規模な結果セットの場合、最初の1,000行は即座に書き込まれ、残りのデータは段階的に取得されます。データ取得が中断された場合、部分的な結果がシートに残りますが、クエリを再実行することでクリアできます。
クエリの追加 (オプション)
SQLクエリにクエリを追加するには:
-
クエリに
:parameter_nameの形式のクエリが少なくとも 1 つ含まれていることを確認してください。 クエリの問題の詳細については、 「名前付きの問題マーカーを使用する」を参照してください。 -
[+追加] をクリックします。
-
最初のボックスにパラメーターを入力します。 パラメーター名がクエリ エディターに入力したものと一致していることを確認してください。
-
2 番目のボックスに、シート名の後の感嘆符を含めて、シート名の値のセル位置を入力します。
-
さらにクエリを追加するには、 [+ 追加] を再度クリックします。
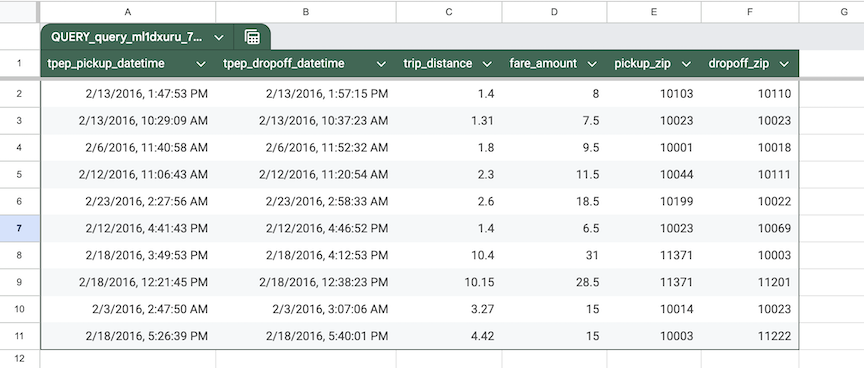
たとえば、次のクエリには、シート
sheet_1のセル H1 で定義されているクエリ パラメーター:trip_distanceが含まれています。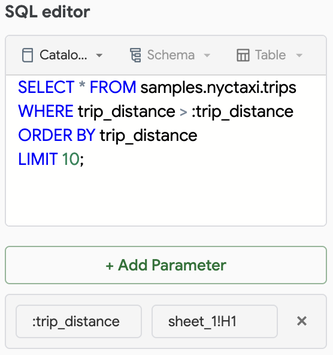
ピボットテーブルとしてインポート(オプション)
データをピボット テーブルとしてインポートするには、次の手順を実行します。
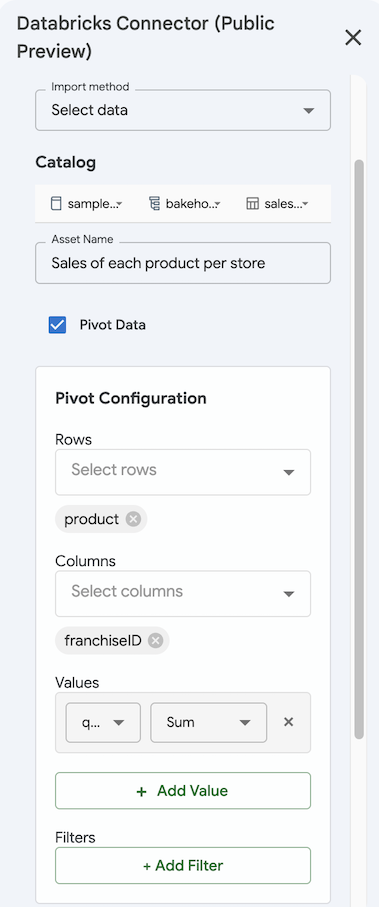
- データの選択 方法を使用してデータをインポートするには、 ピボット テーブル チェックボックスをオンにします。
- [ピボット構成] で、ピボット テーブルのディメンションの 行 と 列 を選択します。
- 集計する値を指定します。 [+ 値の追加] をクリックし、列と集計方法を選択します。
- 必要に応じて、 「+ フィルターを追加」を クリックして 列 と フィルターの種類 を選択し、フィルターを追加します。
- [保存してインポート] をクリックして、結果をピボット テーブルとしてインポートします。インポート ピボット テーブルは新しいシートに自動的にインポートされます。
インポートしたデータの管理
Databricks からインポートしたデータを管理するには、次の手順を実行します。
-
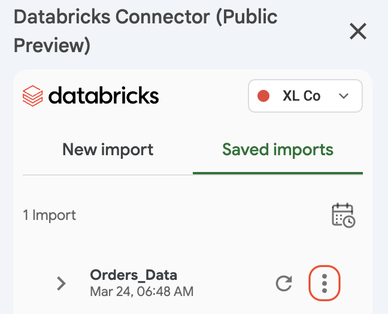
コネクタのサイドバーにある 「保存済みインポート」 タブをクリックします。
-
インポートしたデータを手動で更新するには:
- 単一のインポートを更新するには 、クエリ名の横にある更新アイコンをクリックします。
- すべてのインポートを更新する : [保存されたインポート] タブの上部、カレンダー アイコンの横にある [更新] アイコンをクリックします。
定期的なスケジュールでインポートを自動的に更新するには、 「Google スプレッドシートでデータ更新をスケジュールする」を参照してください。
-
インポートが接続されているシートを確認するには、
 > クエリ名の横にあるシートに移動します 。
> クエリ名の横にあるシートに移動します 。 -
インポートを編集するには、クエリ名の横にある
> [編集] をクリックします。 -
インポートを削除するには、クエリ名の横にある
> [削除] をクリックします。これにより、Google スプレッドシートにインポートされたデータではなく、クエリが削除されます。インポートしたデータは手動で削除する必要があります。
共有の意味
アドオンは、Google スプレッドシートを共有する機能には影響しません。ただし、ファイルを共有する方法によって、受信者がアドオンを使用して実行できるアクションが影響を受けます。
- 閲覧者またはコメント投稿者の役割を持つ受信者はアドオンにアクセスできません。
- 編集者の役割と同等のデータアセットアクセス権を持つ受信者は、Google アカウントでアドオンを使用できます。所有者と同じようにコネクタを使用できます。
- 編集者ロールを持ち、基礎となるリソースへの同じアクセス権を持つ受信者は、同じ Databricks ワークスペースにログインしている場合、インポートを更新できます。
インポートされたデータを移動する
インポートされたテーブルを標準のコピー・アンド・ペーストまたはカット・アンド・ペーストコマンドを使用して移動します:
- コピーして貼り付けると、テーブルデータが重複します。
- 切り取りと貼り付けで、インポートされたテーブルが移動します。
Databricksはテーブルデータのエクスポートを妨げません。
制限事項
-
既存のインポートに添付されているシートの名前を変更したり削除したりすると、インポートを更新できなくなります。これを修正するには、次の いずれか を実行します。
- まったく同じ名前でシートを再作成します。
- ソースとして クエリを選択 を選択し、インポートを再利用して、 新規として保存 をクリックして、新しいインポートを作成します。
-
2 つのクエリが同じ範囲または重複する範囲にマップされている場合、アドオンは最後に実行されたクエリの結果を表示します。これにより、以前にインポートされたデータが上書きされます。