Databricks とは
Databricks は、エンタープライズ レベルの大規模なデータ分析やAIソリューションを構築、デプロイ、共有、保守するための統合されたオープンな分析プラットフォームです。Databricksデータインテリジェンスプラットフォームは、クラウドアカウントのクラウドストレージとセキュリティと統合し、クラウドインフラストラクチャを管理およびデプロイします。
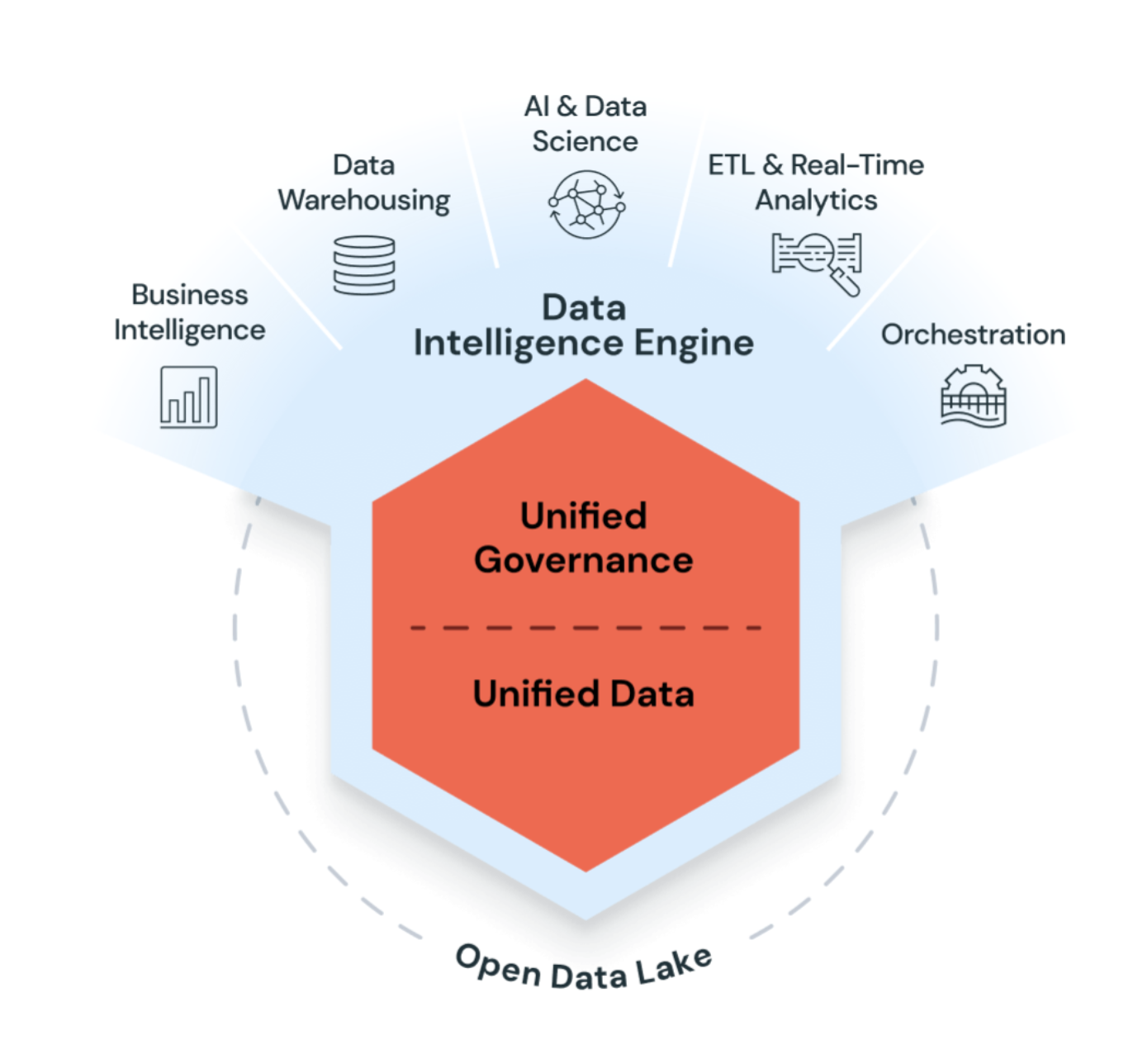
Databricksは、生成AIとデータレイクハウスを使用して、データの一意のセマンティクスを理解します。その後、パフォーマンスを自動的に最適化し、ビジネスニーズに合わせてインフラストラクチャを管理します。
自然言語処理はビジネスの言語を学習するため、自分の言葉で質問することでデータを検索して発見できます。自然言語アシスタンスは、コードの記述、エラーのトラブルシューティング、ドキュメントでの回答の検索に役立ちます。
マネージドなオープンソースインテグレーション
Databricks はオープンソースコミュニティにコミットしており、Databricks Runtime リリースとのオープンソース統合の更新を管理しています。次のテクノロジーは、もともと Databricks の従業員によって作成されたオープンソースプロジェクトです。
一般的な使用例
次の使用例では、重要なビジネス機能と意思決定を推進するデータの処理、保存、分析に不可欠なタスクを達成するために、顧客が Databricks を使用する方法の一部に焦点を当てています。
エンタープライズデータレイクハウスの構築
このデータレイクハウスは、エンタープライズデータウェアハウスとデータレイクを組み合わせて、エンタープライズデータソリューションを高速化、簡素化、統合します。データエンジニア、 データサイエンティスト、アナリスト、および本番運用システムはすべて、データレイクハウスを単一の真実のソースとして使用でき、一貫性のあるデータへのアクセスを提供し、多くの分散データシステムの構築、保守、同期の複雑さを軽減します。 データレイクハウスとはを参照してください。
ETLとデータエンジニアリング
ダッシュボードを生成する場合でも、人工知能アプリケーションを強化する場合でも、データエンジニアリングは、データが利用可能でクリーンで、効率的な検出と使用のためにデータモデルに保存されていることを確認することで、データ中心の企業にバックボーンを提供します。Databricks は、 Apache Spark のパワーと Delta およびカスタム ツールを組み合わせて、比類のない ETL エクスペリエンスを提供します。SQL、Python、Scalaを使用してETLロジックを作成し、スケジュールされたジョブのデプロイを数回のクリックでオーケストレーションします。
Lakeflow Spark宣言型パイプラインは、データセット間の依存関係をインテリジェントに管理し、本番運用インフラストラクチャを自動的にデプロイおよびスケーリングすることで、 ETLさらに簡素化し、仕様に合わせたタイムリーで正確なデータ配信を保証します。
Databricksは、クラウドオブジェクトストレージとデータレイクからデータ レイクハウスにデータを段階的かつ、べき等的に読み込むための効率的でスケーラブルなツールである Auto Loaderなど、データ取り込み用のツールを提供します。
機械学習、AI、データサイエンス
Databricksにおける機械学習は、Databricks機械学習ランタイムやMLflowなど、データサイエンティストやMLエンジニアのニーズに合わせた一連のツールによって、プラットフォームのコア機能を拡張します。
大規模言語モデルと生成AI
Databricks機械学習ランタイムには、既存の事前トレーニング済みモデルやその他のオープンソースライブラリをワークフローに統合できる Hugging Face Transformers などのライブラリが含まれています。Databricks MLflow の統合により、トランスフォーマー パイプライン、モデル、処理コンポーネントと共に MLflow 追跡サービスを簡単に使用できます。OpenAIモデルやJohn Snow LabsのようなパートナーのソリューションをDatabricks ワークフローに統合します。
Databricks を使用して、特定のタスクに合わせてデータの LLM をカスタマイズします。Hugging Face や DeepSpeed などのオープンソース ツールのサポートにより、基礎 LLM を効率的に取得し、独自のデータでトレーニングを開始して、ドメインとワークロードの精度を高めることができます。
さらに、 Databricks 、 SQLデータ アナリストがデータパイプラインやワークフロー内で直接、 OpenAIからなどの LLM にアクセスするために使用できるAI関数を提供します。 「 AI Functionsを使ったエンリッチデータ」をご覧ください。
データウェアハウス、アナリティクス、BI
Databricksは、ユーザー フレンドリーな UI とコスト効率の高いコンピュート リソース、および無限にスケーラブルで手頃なストレージを組み合わせて、分析クエリを実行するための強力なプラットフォームを提供します。 管理者はスケーラブルなコンピュート クラスターをSQLウェアハウスとして構成し、エンド ユーザーがクラウド上での作業の複雑さを気にすることなくクエリを実行できるようにします。 SQL ユーザーは、SQL クエリ エディターまたはノートブックを使用して、レイクハウス内のデータに対してクエリを実行できます。ノートブックはSQL に加えて Python、R、Scala をサポートしており、ユーザーはダッシュボード で利用できるものと同じビジュアライゼーションを、 リンク、画像、マークダウンで記述されたコメントとともに埋め込むことができます。
データガバナンスと安全なデータ共有
Unity Catalogは、データレイクハウスに統合されたデータガバナンスモデルを提供します。クラウド管理者はUnity Catalogの大まかなアクセス制御権限を構成して統合し、Databricks管理者はチームや個人の権限を管理できます。権限は、ユーザーフレンドリーなUIまたはSQL構文のいずれかを介してアクセス制御リスト(ACL)で管理されます。これにより、データベース管理者は、クラウドネイティブのIDアクセス管理(IAM)やネットワーキングを使用する必要なく、データへのアクセスを簡単に保護することできます。
Unity Catalog により、安全なアナリティクス クラウド上での運用が簡単になり、プラットフォームの管理者とエンドユーザーの両方に必要な再教育やスキルアップを制限する責任分担が可能になります。 Unity Catalog とはを参照してください。
レイクハウスを使用すると、テーブルやビューへのクエリ アクセスを許可するのと同じくらい簡単に、組織内でのデータ共有が可能になります。 セキュリティで保護された環境の外部で共有するために、Unity Catalog には マネージド バージョンの Delta Sharing が用意されています。
DevOps、CI/CD、タスクのオーケストレーション
ETL パイプライン、MLモデル、アナリティクスダッシュボードの開発ライフサイクルには、それぞれ独自の課題があります。Databricks では、すべてのユーザーが 1 つのデータソースを活用できるため、重複する作業やレポートの同期がずれていることが削減されます。 さらに、バージョン管理、自動化、スケジューリング、コードデプロイ、本番運用リソースのための一連の共通ツールを提供することで、モニタリング、オーケストレーション、運用のオーバーヘッドを簡素化できます。
ジョブはDatabricksノートブック、 SQLクエリ、その他の任意のコードをスケジュールします。 宣言型オートメーション バンドルを使用すると、ジョブやパイプラインなどのDatabricksリソースをプログラムで定義、デプロイ、実行できます。 Gitフォルダを使用すると、Databricksプロジェクトを多数の一般的なGitプロバイダーと同期できます。
CI/CD のベスト プラクティスと推奨事項については、Databricks のベスト プラクティスと推奨される CI/CD ワークフローを参照してください。開発者向けツールの完全な概要については、Databricks での開発を参照してください。
リアルタイム分析とストリーミング分析
Databricks Apache Spark構造化ストリーミングを活用して、ストリーミング データと増分データ変更を処理します。 構造化ストリーミングはDelta Lakeと緊密に統合されており、これらのテクノロジーはLakeflow Spark宣言型パイプラインとAuto Loaderの両方の基盤を提供します。 構造化ストリーミングの概念を参照してください。
オンライン取引処理
Lakebase は、Databricks データ インテリジェンス プラットフォームと完全に統合されたオンライン トランザクション処理 (OLTP) データベースです。このフルマネージド Postgres データベースを使用すると、 Databricksが管理するストレージに保存された OLTP データベースを作成および管理できます。 Lakebase Provisionedとは何ですか?を参照してください。 。