ジョブの失敗のトラブルシューティングと修復
たとえば、Eメール 通知、モニタリング ソリューション、 Lakeflow ジョブ UI などを通じてジョブの実行でタスクが失敗したという通知を受け取ったとします。 この記事の手順では、エラーの原因を特定するためのガイダンス、見つけた問題を修正するための提案、失敗したジョブ実行を修復する方法を提供します。
障害の原因を特定する
LakeflowジョブUIで失敗したタスクを見つけるには:
-
サイドバーで
 **ジョブ & パイプライン** をクリックします。
**ジョブ & パイプライン** をクリックします。 -
名前 列で、ジョブ名をクリックします。 実行 タブには、アクティブな実行と完了した実行 (失敗した実行を含む) が表示されます。 実行 タブのマトリックス ビューには、各ジョブ タスクの成功と失敗の実行など、ジョブの実行履歴が表示されます。タスクの実行が失敗したか、依存タスクが失敗したためにスキップされたために失敗する可能性があります。 マトリックス ビューを使用すると、ジョブ実行のタスクの失敗をすばやく特定できます。
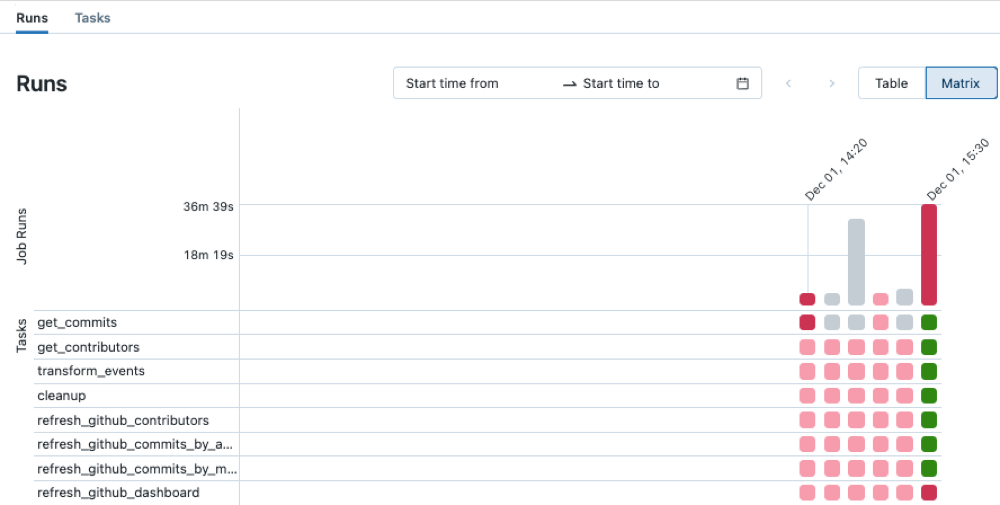
-
失敗したタスクにカーソルを合わせると、関連するメタデータが表示されます。 このメタデータには、開始日と終了日、ステータス、期間クラスターの詳細、場合によってはエラーメッセージが含まれます。
-
失敗の原因を特定するには、失敗したタスクをクリックします。 タスク実行の詳細 ページが表示され、タスクの出力、エラー メッセージ、および関連するメタデータが表示されます。
失敗の原因を修正する
タスクは、データ品質の問題、構成の誤り、コンピュート リソースの不足など、いくつかの理由で失敗した可能性があります。 タスクの失敗の一般的な原因を修正するために推奨される手順を次に示します。
-
失敗がタスク設定に関連している場合は、[ タスクの編集 ] をクリックします。 タスク設定が新しいタブで開きます。 必要に応じてタスク設定を更新し、[ タスクの保存 ] をクリックします。
-
問題がクラスター リソースに関連している場合 (インスタンスの不足など) は、いくつかのオプションがあります。
- ジョブがジョブ クラスターを使用するように構成されている場合は、共有の 汎用クラスターの使用を検討してください。
- クラスター構成を変更します。**タスクを編集**をクリックします。 ジョブの詳細 パネルの コンピュート で、 構成 をクリックしてクラスターを構成します。ワーカーの数、インスタンスタイプ、またはその他のクラスター設定オプションを変更できます。また、 スワップ をクリックして、別の利用可能なクラスターに切り替えることもできます。利用可能なリソースを最適に使用していることを確認するには、クラスター構成のベスト プラクティスを確認してください。
- 必要に応じて、管理者にリソースクォータのクラウド上で アカウントとワークスペースがデプロイされているリージョンを増やすように依頼します。
-
最大並列実行を超えたことが障害の原因である場合は、次のいずれかを実行します。
- 他の実行が完了するまで待ちます。
- **タスクを編集**をクリックします。**ジョブの詳細**パネルで、**並列実行の編集**をクリックし、**最大 並列 実行数**に新しい値を入力して、**確認**をクリックします。
場合によっては、エラーの原因がジョブの上流にあることがあります。たとえば、外部データソースが使用できない場合があります。 外部の問題が解決された後も、次のセクションで説明する修復実行機能を利用できます。
失敗したタスクとスキップされたタスクの再実行
失敗の原因を特定したら、失敗したタスクのサブセットと依存タスクのみを実行することで、失敗またはキャンセルされたマルチタスク ジョブを修復できます。 成功したタスクとそれに依存するタスクは再実行されないため、この機能により、失敗したジョブ実行からの回復に必要な時間とリソースが削減されます。
ジョブの実行を修復する前に、ジョブまたはタスクの設定を変更することができます。 失敗したタスクは、現在のジョブとタスクの設定で再実行されます。 たとえば、パスをノートブックまたはクラスター設定に変更すると、更新されたノートブックまたはクラスター設定でタスクが再実行されます。
修復は、失敗した各タスクを最初から再実行します。Lakeflow Jobs はタスクを冪等にしないため、タスクが失敗する前に出力の一部を書き込んだ場合、それを再実行するとデータが重複する可能性があります。修復が安全かどうかは、タスク自身のロジックに依存します。実行を修復する前に、各タスクが書き込む内容を確認し、重複データが懸念される場合は冪等操作 (追加ではなく上書きやマージなど) を使用してください。
タスク実行の詳細ページで 、 すべてのタスク実行の履歴 を表示します。
- 1 つ以上のタスクがジョブ クラスターを共有している場合、修復の実行によって新しいジョブ クラスターが作成されます。 たとえば、元の実行で ジョブ クラスター [
my_job_cluster] が使用されていた場合、最初の修復実行では新しいジョブ クラスターmy_job_cluster_v1が使用され、初期実行と修復実行で使用されたクラスターとクラスターの設定を簡単に確認できます。my_job_cluster_v1の設定は、現在のmy_job_clusterの設定と同じです。 - 修復は、2 つ以上のタスクをオーケストレーションするジョブのみでサポートされています。失敗した単一タスクのジョブを再実行するには、 今すぐ実行 で再度トリガーしてください。単一のジョブ実行をトリガーするを参照してください。
- 実行 タブに表示される 期間 の値には、最初の実行が開始された時刻から、最新の修復実行が終了した時刻までが含まれます。たとえば、実行が 2 回失敗し、3 回目の実行で成功した場合、実行時間には 3 回すべての実行の時間が含まれます。
- 修復処理では、各タスクの実行状態に基づいて修復対象を判断し、無効化状態は判断しません。修復中に無効化されたタスクを強制的に実行するには、修復要求の
rerun_tasksにそのタスクを含めます。LakeFlowジョブの無効なタスクを参照してください。
失敗したジョブを修復するには、次のコマンドを実行します。
- ジョブ実行テーブルの 開始時刻 列で失敗した実行のリンクをクリックするか、マトリックス・ビューで失敗した実行をクリックします。 ジョブ実行の詳細 ページが表示されます。
- 実行の修復 をクリックします。 ジョブ実行の修復 ダイアログが表示され、失敗したすべてのタスクと、再実行される依存タスクが一覧表示されます。
- 修復するタスクのパラメーターを追加または編集するには、 ジョブ実行の修復 ダイアログにパラメーターを入力します。 ジョブ実行の修復 ダイアログに入力するパラメーターは、既存の値を上書きします。その後の修復実行では、 ジョブ実行の修復 ダイアログでキーと値をクリアすることで、パラメーターを元の値に戻すことができます。
- ジョブ実行の修復 ダイアログで 実行の修復 をクリックします。
- 修復実行が完了すると、マトリックス ビューは修復された実行の新しい列で更新されます。 赤で表示された失敗したタスクは緑になり、ジョブ全体で実行が成功したことを示します。
継続的なジョブの失敗を表示および管理する
連続したジョブの連続した失敗がしきい値を超えると、Lakeflow ジョブは 指数バックオフ を使用してジョブを再試行します。ジョブが指数関数的バックオフ状態の場合、 ジョブの詳細 パネルに次のような情報が表示されます。
- 連続した失敗の数。
- ジョブがエラーなく実行される期間で、成功と見なされる期間。
- 現在アクティブな実行がない場合の次の再試行までの時間。
アクティブな実行をキャンセルし、再試行期間をリセットして、新しいジョブ実行を開始するには、 実行の再開 をクリックします。
Genie Codeを使用してエラーを診断する
Genie Code はジョブ内のエラーの診断に役立ちます。
Genie Code を使用してジョブを診断するには:
- ジョブUIから失敗したジョブを開きます。
- エラーの診断 を選択します。
![[エラーの診断] ボタンで失敗したジョブ。](/aws/ja/assets/images/assistant-diagnose-jobs-278da88ebf2f66551dfcba02a3f6cc76.png)