データプロファイリング
この記事ではデータプロファイリングについて説明します。 データプロファイリングのコンポーネントと使用法の概要を説明します。
データプロファイリングは、テーブルの概要統計を提供し、長期にわたるプロファイリング メトリクスを計算して、過去の傾向を簡単に確認できます。 これは、選択したテーブルのすべての主要なメトリクスを詳細にモニタリングするのに役立ちます。 また、これを使用して、モデルの入力と予測を含む推論テーブルをプロファイリングすることにより、機械学習モデルおよびモデルサービング エンドポイントのパフォーマンスを追跡することもできます。 この図は、 Databricksのデータと機械学習パイプラインを通るデータの流れと、プロファイリングを使用してデータ品質とモデルのパフォーマンスを継続的に追跡する方法を示しています。
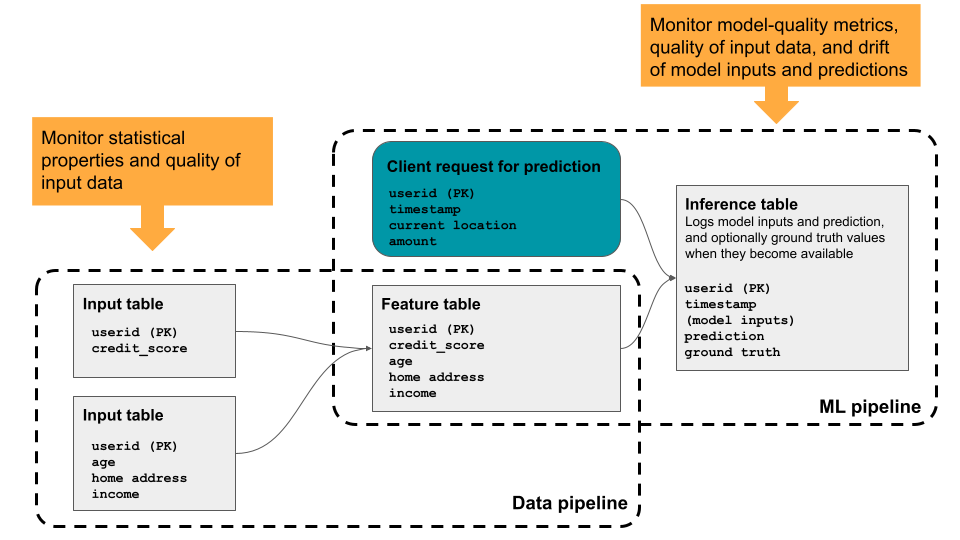
データプロファイリングを使用する理由
定量的メトリクスは、データの品質と一貫性を長期にわたって追跡および確認するのに役立ちます。 テーブルのデータ分布または対応するモデルのパフォーマンスの変化を検出すると、データプロファイリングによって作成されたテーブルがその変化を把握してアラートし、原因を特定するのに役立ちます。
データプロファイリングは、次のような質問に答えるのに役立ちます。
- データの完全性はどうなっていて、時間とともにどのように変化しているのか。たとえば、現在のデータに含まれるNULL値または0値の割合はどのくらいなのか。また増加しているのか。
- データの統計的分布はどうなっていて、時間とともにどのように変化しているのか。たとえば、ある数値列の90パーセンタイルはどこにあるのか。カテゴリー列の値の分布はどうなっていて、前日からどう変化しているのか。
- 現在のデータと既知のベースラインの間、またはデータの経時的変化の中に、ドリフトはあるのか。
- データのサブセットまたはスライスの統計的分布やドリフトはどうなっているのか。
- 機械学習モデルの入力および予測は、時間とともにどのように変化しているのか。
- モデルのパフォーマンスはどのように推移しているのか。モデルバージョンAのパフォーマンスはバージョンBよりも優れているのか。
さらに、データプロファイリングを使用すると、観測の時間粒度を制御し、カスタム メトリクスを設定できます。
要件
- ワークスペースで Unity Catalog が有効になっており、Databricks SQL にアクセスできる必要があります。
- データプロファイリングを有効にするには、次の権限が必要です。
USE CATALOGカタログではUSE SCHEMA、テーブルを含むスキーマではです。SELECT:テーブル上。MANAGEカタログ、スキーマ、またはテーブルに対して。
データプロファイリングはジョブにサーバレス コンピュートを使用しますが、アカウントがサーバレス コンピュートに対して有効になっている必要はありません。 経費の追跡に関する情報については、 「データ品質モニタリング経費の表示」を参照してください。
データプロファイリングの仕組み
テーブルをプロファイルするには、テーブルに添付されたプロファイルを作成します。機械学習モデルのパフォーマンスをプロファイルするには、モデルの入力と対応する予測を保持する推論テーブルにプロファイルを添付します。
データプロファイリングは、時系列、推論、スナップショットのタイプの分析を提供します。
プロファイルのタイプ | 説明 |
|---|---|
時系列 | タイムスタンプ列に基づく時系列データセットを含むテーブルに使用します。時系列の時間ベースのウィンドウ全体でコンピュート データ品質メトリクスをプロファイリングします。 |
推論 | モデルのリクエスト ログを含むテーブルに使用します。各行はリクエストであり、タイムスタンプ、モデル入力、対応する予測、および(オプションの)グラウンドトゥルースラベルの列が含まれます。プロファイリングでは、リクエスト ログの時間ベースのウィンドウ全体でモデルのパフォーマンスとデータ品質メトリクスを比較します。 |
スナップショット | 他のすべての種類のテーブルに使用します。プロファイリングでは、テーブル内のすべてのデータに対してデータ品質メトリクスが計算されます。 更新のたびにテーブル全体が処理されます。スナップショット プロファイルの最大テーブル サイズは 4 TB です。より大きなテーブルの場合は、代わりに時系列プロファイルを使用します。 |
このセクションでは、データプロファイリングで使用される入力テーブルと、データプロファイリングによって生成されるメトリクス テーブルについて簡単に説明します。 この図は、入力テーブル、メトリクス テーブル、プロファイル、ダッシュボード間の関係を示しています。
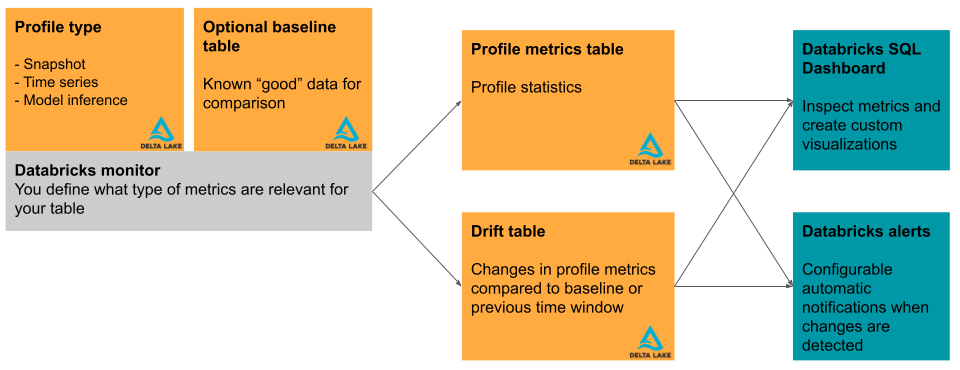
プライマリテーブルとベースラインテーブル
「プライマリ テーブル」と呼ばれるプロファイリング対象のテーブルに加えて、ドリフト、つまり時間の経過に伴う値の変化を測定するための参照として使用するベースライン テーブルをオプションで指定できます。ベースライン テーブルは、データがどのようになると予想されるかのサンプルがある場合に役立ちます。その考え方は、ドリフトが予想されるデータ値と分布に対して相対的にコンピュートされるということです。
ベースライン テーブルには、統計分布、個々の列の分布、欠損値、その他の特性の観点から、入力データの予想される品質を反映するデータセットが含まれている必要があります。プロファイルされたテーブルのスキーマと一致する必要があります。例外は、時系列または推論プロファイルで使用されるテーブルのタイムスタンプ列です。プライマリ テーブルまたはベースライン テーブルのいずれかで列が欠落している場合、プロファイリングではベスト エフォート ヒューリスティックを使用して出力メトリクスを計算します。
スナップショット プロファイルを使用するプロファイルの場合、ベースライン テーブルには、分布が許容可能な品質基準を表すデータのスナップショットが含まれている必要があります。たとえば、成績分布データでは、成績が均等に分布していた前のクラスを基準として設定する場合があります。
時系列プロファイルを使用するプロファイルの場合、ベースライン テーブルには、データ分布が許容可能な品質基準を表す時間ウィンドウを表すデータが含まれている必要があります。たとえば、天気データでは、気温が予想される平年気温に近かった週、月、または年にベースラインを設定できます。
推論プロファイルを使用するプロファイルの場合、ベースラインとして適切な選択は、プロファイル対象のモデルのトレーニングまたは検証に使用されたデータです。 このようにして、ユーザーは、モデルがトレーニングされ検証された内容に比べてデータが変動した場合にそれを察知することができます。 このテーブルには、プライマリ テーブルと同じ特徴列が含まれている必要があり、さらに、データが一貫して集計されるように、プライマリ テーブルの InferenceLog に指定されたものと同じmodel_id_colが含まれている必要があります。理想的には、モデルを評価するために使用されるテスト セットまたは検証セットは、同等のモデル品質メトリクスを保証するために使用する必要があります。
メトリクスのテーブルとダッシュボード
プロファイリングにより、2 つのメトリクス テーブルと 1 つのダッシュボードが作成されます。 メトリクス値は、テーブル全体、およびプロファイルの作成時に指定した時間枠とデータ サブセット (または「スライス」) のコンピュートです。 また、推論解析のためにモデルIDごとにメトリクスをコンピュートしています。 メトリクス テーブルの詳細については、 「データプロファイリング メトリクス テーブル」を参照してください。
- プロファイル メトリクス テーブルには、概要統計が含まれています。 プロファイル メトリクス テーブル スキーマを参照してください。
- ドリフト メトリクス テーブルには、時間の経過に伴うデータのドリフトに関連する統計が含まれています。 ベースライン テーブルが提供されている場合は、ベースライン値に対するドリフトもプロファイリングされます。ドリフト メトリクス テーブル スキーマを参照してください。
メトリクステーブルはDeltaテーブルで、ユーザーが指定したUnity Catalogスキーマに保存されます。Databricks UIを使用してこれらのテーブルを表示したり、Databricks SQLを使用してクエリを実行したり、それらに基づいてダッシュボードやアラートを作成したりすることができます。
各プロファイルについて、Databricks はプロファイルの結果を視覚化して提示するダッシュボードを自動的に作成します。ダッシュボードは完全にカスタマイズ可能です。「ダッシュボード」を参照してください。
制限事項
- プロファイリングではDeltaテーブルのみがサポートされており、テーブルはマネージドテーブル、外部テーブル、ビュー、マテリアライズドビュー、またはストリーミング テーブルのいずれかのテーブル タイプである必要があります。
- マテリアライズドビューで作成されたプロファイルは、増分処理をサポートしません。
- すべての地域がサポートされているわけではありません。地域サポートについては、AI および機械学習機能の利用可能性」 の表の 「データプロファイリング」 列を参照してください。
- 時系列または推論分析モードを使用して作成されたプロファイルは、過去 30 日間のメトリクスのみをコンピュートします。 これを調整する必要がある場合は、Databricks アカウント チームにお問い合わせください。
- スナップショット プロファイルの最大テーブル サイズは 4 TB です。より大きなテーブルの場合は、代わりに時系列プロファイルを使用します。
データプロファイリングの使用を開始する
始めるには以下の記事を参照してください。