開発言語を選択する
Databricks は、開発とデータエンジニアリングのためのさまざまなプログラミング言語の使用をサポートしています。 この記事では、使用可能なオプション、それらの言語を使用できる場所、およびそれらの制限事項について概説します。
推奨 事項
Databricks では、新しいプロジェクトには Python と SQL をお勧めします。
- Python は非常に人気のある汎用プログラミング言語です。 PySpark データフレーム を使用すると、テスト可能なモジュール式変換を簡単に作成できます。 Pythonエコシステムは、ソリューションを拡張するための幅広いライブラリもサポートし、幅広いライブラリをサポートします。
- SQL は、データのクエリ、更新、挿入、削除などの操作を実行してリレーショナルデータセットを管理および操作するための非常に一般的な言語です。 SQL は、バックグラウンドが主にデータベースまたはデータウェアハウジングにある場合に適しています。 SQL は、
spark.sqlを使用して Python に埋め込むこともできます。
次の言語はサポートが限られているため、新しいデータエンジニアリング プロジェクトには Databricks お勧めしません。
- Scala は、Apache Spark™ の開発に使用される言語です。
- R は Databricks ノートブックでのみ完全にサポートされています。
言語サポートは、データパイプラインやその他のソリューションの構築に使用される機能によっても異なります。たとえば、LakeFlow PipelinesはPythonとSQLをサポートしていますが、ワークフローではPython、SQL、Scala、Javaを使用してデータパイプラインを作成できます。
他の言語を使用して、Databricks と対話してデータをクエリしたり、データ変換を実行したりできます。 ただし、これらの相互作用は、主に外部システムとの統合のコンテキストで行われます。 このような場合、開発者はほぼすべてのプログラミング言語を使用して、 Databricks REST API、 ODBC/JDBC ドライバー、 Databricks SQL コネクタ をサポートする特定の言語 (Go、Python、Javascript/Node.js)、 または Spark Connect が実装されている言語 (Go や Rust など) を介して Databricks と対話できます。
ワークスペース開発とローカル開発
ローカル マシン上の Databricks ワークスペースまたは IDE (統合開発環境) を使用してデータ プロジェクトとパイプラインを開発できますが、新しいプロジェクトは Databricks ワークスペースで開始することをお勧めします。ワークスペースは Web ブラウザーを使用してアクセスでき、Unity Catalog のデータに簡単にアクセスできるほか、強力なデバッグ機能や Genie Code などの機能もサポートされています。
Databricks ノートブックまたは SQL エディターを使用して、Databricks ワークスペースでコードを開発します。 Databricks ノートブックは、同じノートブック内でも複数のプログラミング言語をサポートしているため、 Python、 SQL、 Scalaを使用して開発できます。
Databricks ワークスペースで直接コードを開発することには、いくつかの利点があります。
- フィードバックループが高速になります。 実際のデータで記述されたコードをすぐにテストできます。
- 組み込みのコンテキスト認識型 Genie Code により、開発がスピードアップし、問題の解決に役立ちます。
- ノートブックとクエリは、Databricks ワークスペースから直接簡単にスケジュールできます。
- Python 開発では、ワークスペース内のファイルを Python パッケージとして使用することで、Python コードを正しく構造化できます。
ただし、IDE 内のローカル開発には、次の利点があります。
- IDEs 、ナビゲーション、コード リファクタリング、静的コード分析など、ソフトウェア プロジェクトを操作するためのより優れたツールがあります。
- ソースの管理方法を選択でき、Git を使用する場合は、Git フォルダーを使用するワークスペースよりもローカルでより高度な機能を利用できます。
- サポートされている言語の範囲が広がります。 たとえば、Java を使用してコードを開発し、それを JAR タスクとしてデプロイできます。
- コードのデバッグのサポートが向上しました。
- 単体テストの操作に対するサポートが向上しました。
言語選択の例
データエンジニアリングの言語選択は、次の決定木を使用して視覚化されます。
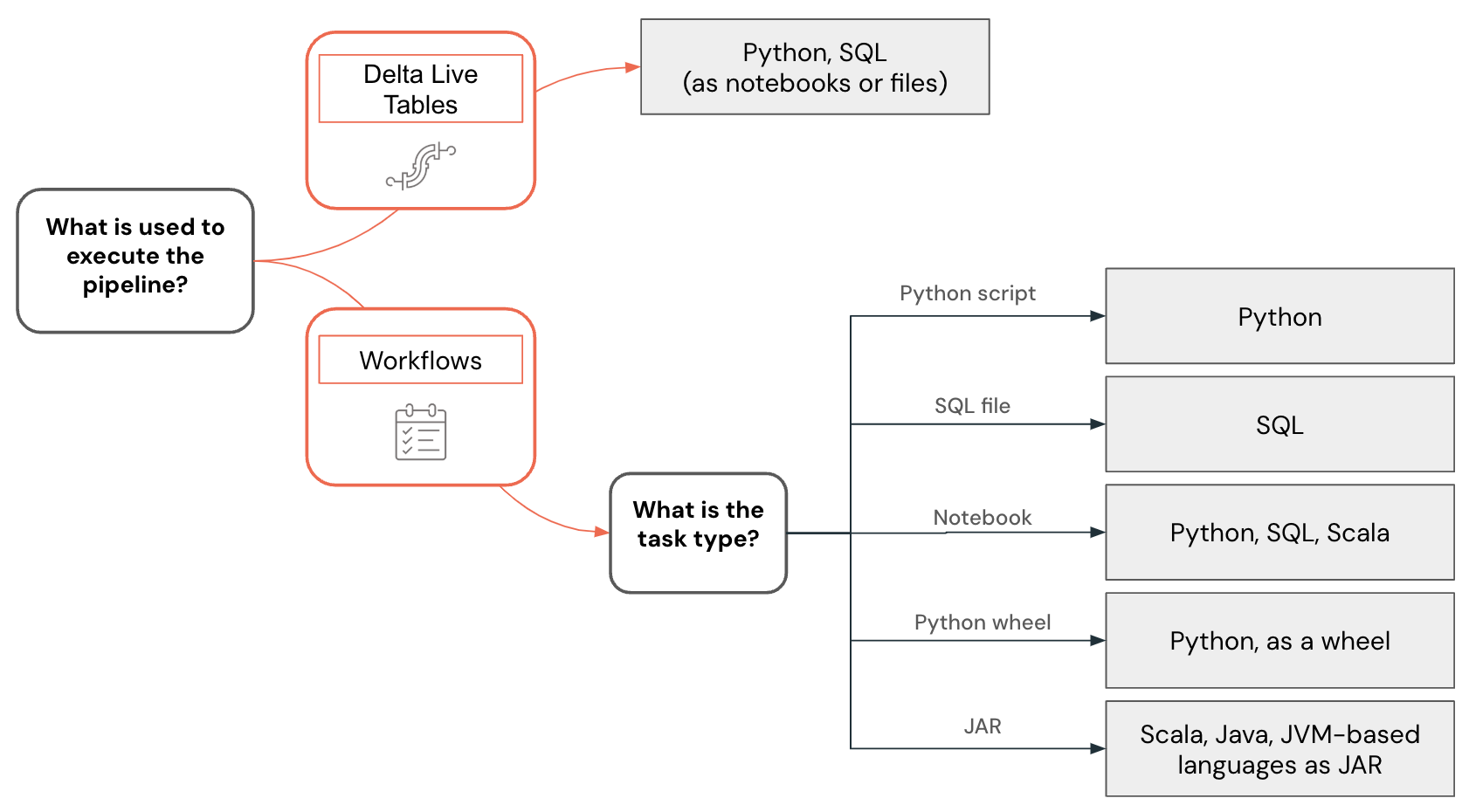
Python コードの開発
Python言語はDatabricksで第一級のサポートを受けています。これをDatabricks ノートブック、LakeFlow Pipelines、ワークフローで使用して、UDFを開発したり、Pythonスクリプトやホイールとしてデプロイしたりできます。
Databricks ワークスペースで Python プロジェクトを開発する場合、ノートブックとしてでもファイルとしてでも、Databricks には、コード補完、ナビゲーション、構文検証、Genie Code を使用したコード生成、対話型デバッグなどのツールが用意されています。開発されたコードは、インタラクティブに実行したり、Databricks ワークフローやLakeFlow Pipelinesとしてデプロイしたり、あるいはUnity Catalogの関数としてデプロイすることもできます。コードを個別の Python パッケージに分割することで、複数のパイプラインやジョブで使用できるように構造化できます。
Databricks Visual Studio Code の拡張機能を提供し、JetBrains はPyCharmのプラグインを提供します。これらを使用すると、IDE でPythonコードを開発し、コードをDatabricksワークスペースに同期し、ワークスペース内で実行し、 Databricks Connectを使用して段階的なデバッグを実行できます。 開発されたコードは、宣言型自動化バンドルを使用して、Databricksのジョブまたはパイプラインとしてデプロイできます。
SQL コードの開発
SQL 言語は、Databricks ノートブック内で使用することも、SQL エディターを使用して Databricks クエリとして使用することもできます。どちらの場合も、開発者はコード補完などのツールや、コード生成や問題の修正に使用できるコンテキスト認識型の Genie Code にアクセスできます。開発されたコードはジョブまたはパイプラインとしてデプロイできます。
Databricks ワークフローでは、ファイルに格納された SQL コードを実行することもできます。 IDE を使用してこれらのファイルを作成し、ワークスペースにアップロードできます。 SQLのもう一つの一般的な使い方は、 dbt(データビルドツール)を使用して開発されたデータエンジニアリングパイプラインです。 Databricks ワークフローでは、dbt プロジェクトのオーケストレーションがサポートされています。
Scala コードの開発
Scala は Apache Spark™ の元の言語です。強力な言語ですが、学習曲線が急です。Scala は Databricks ノートブックでサポートされている言語ですが、Scala のクラスとオブジェクトの作成方法と保守方法に関連するいくつかの制限があり、複雑なパイプラインの開発がより困難になる可能性があります。通常、IDEs ScalaJARDatabricksは コードの開発をより適切にサポートし、 ワークフローの タスクを使用してデプロイできます。
その他のリソース
- Databricks での開発は 、Databricks のさまざまな開発オプションに関するドキュメントのエントリ ポイントです。
- 開発者ツールページでは、宣言型自動化バンドルやIDEs用プラグインなど、 Databricksのローカル開発に使用できるさまざまな開発ツールについて説明しています。
- Databricks ノートブックでのコードの開発では 、Databricks ノートブックを使用して Databricks ワークスペースで開発する方法について説明します。
- SQL エディターでクエリを記述し、データを探索します。 この記事では、Databricks SQL エディターを使用して SQL コードを操作する方法について説明します。
- Develop LakeFlow Pipelines describes the development process for LakeFlow Pipelines.
- Databricks Connect を使用すると、Databricks クラスターに接続し、ローカル環境からコードを実行できます。
- Genie Code を使用して開発を高速化し、コードの問題を解決する方法を学びます。