基盤モデル ファインチューニング UI を使用してトレーニング ランを作成 (非推奨)
基盤モデル ファインチューニングは非推奨であり、2026年8月14日に廃止される予定です。既存のファインチューニング実行は引き続き動作し、再トレーニング可能ですが、その日付以降、databricks_genaiパッケージおよび基盤モデル ファインチューニング UI の新規インストールはブロックされます。
Databricksは、基盤モデルのトレーニングとファインチューニングのためのサーバレスかつGPU対応の環境を提供するAI Runtimeへの移行をお勧めします。
プレビュー
この機能は、us-east-1 と us-west-2でパブリック プレビュー段階です。
この記事では、基盤モデル ファインチューニング(現在は Databricks Model Training の一部)UI を使用してトレーニング実行を作成および設定する方法について説明します。APIを使用して実行を作成することもできます。手順については、「基盤モデル ファインチューニング API を使用してトレーニング 実行を作成 (非推奨)」を参照してください。
必要条件
「要件」を参照してください。
UI を使用してトレーニング実行を作成する
UIを使用してトレーニング実行を作成するには、次のステップに従います。
-
左のサイドバーで エクスペリメント をクリックします。
-
基盤モデル ファインチューニング カードで、 [基盤モデル エクスペリメントの作成] をクリックします。
-
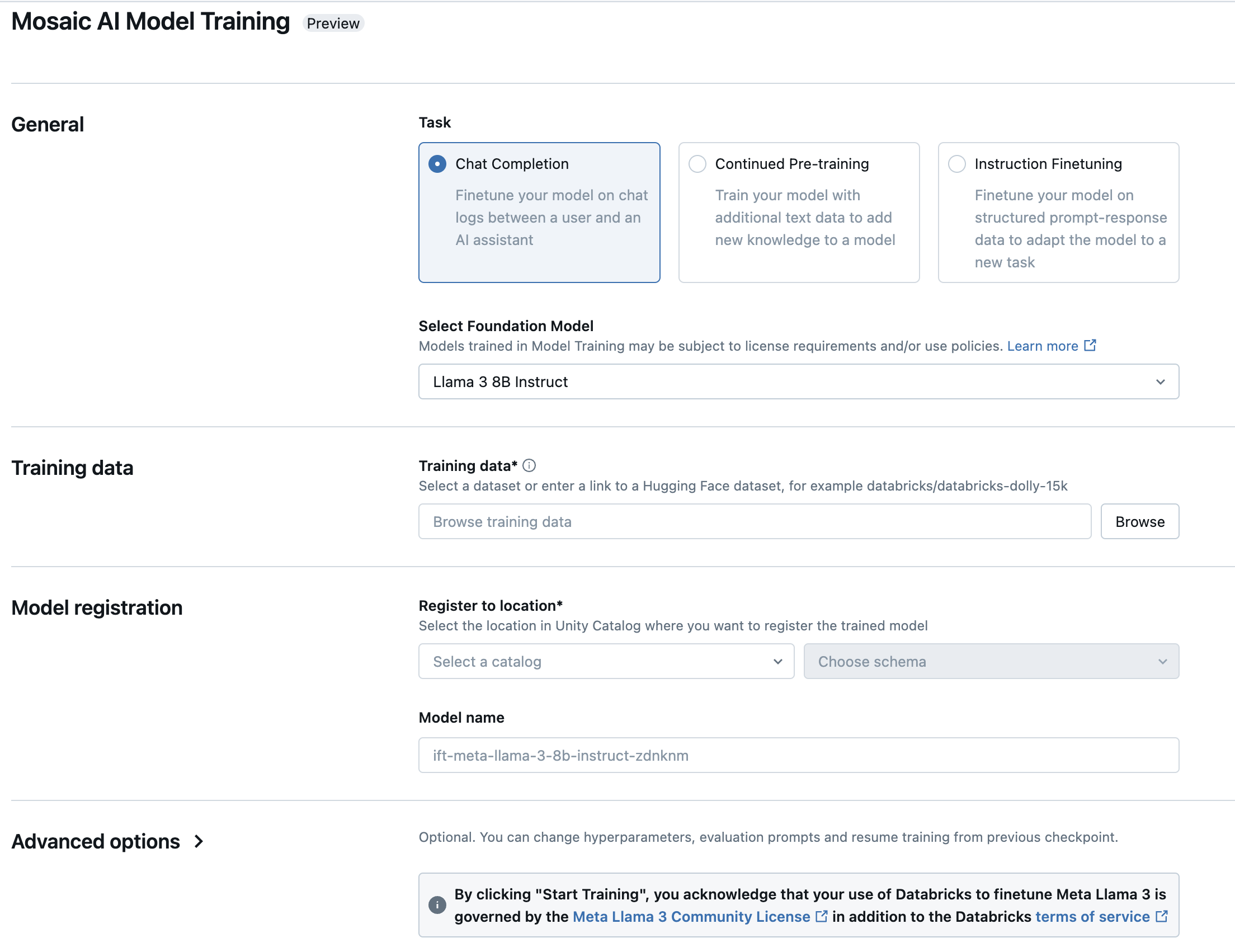
基盤モデル ファインチューニング フォームが開きます。アスタリスクが付いている項目は必須です。選択を行い、[ トレーニングの開始] をクリックします。
タイプ :実行するタスクを選択します。
タスク
説明
指示を微調整
特定のタスクに合わせてモデルを最適化するために、即応型のインプットを使って基盤モデルのトレーニングを続けてください。
継続的な事前学習
基礎モデルのトレーニングを継続して、ドメイン固有の知識を付与します。
チャット完了
Q&Aや会話アプリケーションに最適化するために、チャットログを使って基盤モデルのトレーニングを続けてください。
Select 基盤モデル : チューニングまたはトレーニングするモデルを選択します。 サポートされているモデルの一覧については、「 サポートされているモデル」を参照してください。
トレーニング データ : [参照 ] をクリックして Unity Catalog のテーブルを選択するか、Hugging Face データセットの完全な URL を入力します。 データ サイズの推奨事項については、「 モデル トレーニングの推奨データ サイズ」を参照してください。
Unity Catalogでテーブルを選択する場合は、テーブルの読み取りに使用するコンピュートも選択する必要があります。
ロケーションに登録 :ドロップダウンメニューからUnity Catalogのカタログとスキーマを選択します。トレーニング済みのモデルは、この場所に保存されます。
モデル名 :モデルは、指定したカタログとスキーマにこの名前で保存されます。このフィールドにはデフォルトの名前が表示されますが、必要に応じて変更できます。
高度なオプション :さらにカスタマイズするために、評価、ハイパーパラメーターチューニング、または既存の独自モデルからのトレーニングのためのオプション設定を構成することができます。
設定
説明
トレーニング期間
エポック(例えば
10epなど)またはトークン(1000000tokなど)で指定されるトレーニング実行の期間。デフォルトは1epです。学習率
モデル トレーニングの学習率。 すべてのモデルは、学習率のウォームアップを使用して AdamW オプティマイザーを使用してトレーニングされます。デフォルトの学習率はモデルによって異なる場合があります。ハイパーパラメータ スイープを実行して、さまざまな学習率とトレーニング期間を試し、最高品質のモデルを取得することをお勧めします。
コンテキストの長さ
データサンプルのシーケンスの最大長です。この設定より長いデータは切り捨てられます。デフォルトは、選択したモデルによって異なります。
評価データ
[ 参照 ]をクリックしてUnity Catalogのテーブルを選択するか、Hugging Faceデータセットの完全なURLを入力します。このフィールドを空白のままにすると、評価は実行されません。
モデルの評価プロンプト
モデルの評価に使用するオプションのプロンプトを入力します。
エクスペリメント名
デフォルトでは、実行ごとに新しい自動生成された名前が割り当てられます。必要に応じて、カスタム名を入力するか、ドロップダウンリストから既存のエクスペリメントを選択することもできます。
カスタム加重
デフォルトでは、トレーニングは選択したモデルの元の重みを使用して開始されます。ファインチューニング APIによって生成されたチェックポイントから開始するには、チェックポイントを含む MLflow アーティファクトフォルダへのパスを入力します。 注: 2025 年 3 月 26 日より前にモデルをトレーニングした場合、それらのモデル チェックポイントから継続的にトレーニングすることはできなくなります。以前に完了したトレーニングの実行は、プロビジョニングされたスループットで問題なく提供できます。
次のステップ
トレーニングの実行が完了したら、MLflowでメトリクスを確認し、推論用にモデルをデプロイできます。「チュートリアル: 基盤モデル ファインチューニング 実行の作成とデプロイ (非推奨)」のステップ5~7を参照してください。
データの準備、微調整トレーニング実行設定、およびデプロイメントを説明する指示を微調整の例については、指示を微調整:エンティティを識別できる名前デモノートブックを参照してください。