Lakeflow Spark宣言型パイプラインの概念
Lakeflow Spark宣言型パイプライン (SDP) とは何か、それを定義する中心的な概念 (パイプライン、ストリーミング テーブル、マテリアライズドビューなど)、それらの概念間の関係、データ処理ワークフローで SDP を使用する利点について学びます。
SDPとは何ですか?
Lakeflow Spark宣言型パイプラインは、SQLおよびPythonでバッチおよびストリーミング データパイプラインを開発および実行するための宣言型フレームワークです。Lakeflow SDP は、パフォーマンスが最適化されたDatabricks Runtime上で実行されながら、Apache Spark宣言型パイプラインを拡張し、相互運用可能です。また、Lakeflow Spark宣言型パイプライン flows API は Apache Sparkと構造化ストリーミングと同じDataFrame API を使用します。SDP の一般的な使用例には、クラウド ストレージ (Amazon S3、Azure ADLS Gen2、Google Cloud Storage など) やメッセージ バス (Apache Kafka、Amazon Kinesis、Google Pub/Sub、Azure EventHub、Apache Pulsar など) などのソースからの増分データ取り込み、ステートレスおよびステートフル オペレーターによる増分バッチおよびストリーミング変換、メッセージ バスやデータベースなどのトランザクション ストア間の リアルタイム ストリーム処理 などがあります。
宣言型データ処理の詳細については、 「Databricks での手続き型データ処理と宣言型データ処理」を参照してください。
SDP の利点は何ですか?
SDP の宣言的な性質によりApache SparkおよびSpark構造化ストリーミングAPIs使用してデータ プロセスを開発し、 Lakeflowジョブを介した手動オーケストレーションを使用してDatabricks Runtimeでそれらを実行するのと比較して、次の利点が得られます。
- 自動オーケストレーション : SDP は、処理ステップ (「フロー」と呼ばれる) を自動的にオーケストレーションし、正しい実行順序と最大レベルの並列処理を確保して、最適なパフォーマンスを実現します。さらに、パイプラインは一時的な障害を自動的かつ効率的に再試行します。再試行プロセスは、最も細分化されコスト効率の高い単位である Spark タスクから始まります。タスク レベルの再試行が失敗した場合、SDP はフローの再試行に進み、必要に応じて最後にパイプライン全体を再試行します。
- 宣言型処理 : SDP は、数百行、あるいは数千行に及ぶ手動の Spark および構造化ストリーミング コードをわずか数行にまで削減できる宣言型関数を提供します。SDP AUTO CDC API 、 SCD Type 1 とSCD Type 2 の両方をサポートすることで、チェンジデータ キャプチャ ( CDC ) イベントの処理を簡素化します。これにより、順序外れのイベントを処理するための手動コードの必要性がなくなり、ストリーミング セマンティクスやウォーターマークなどの概念を理解する必要もありません。
- インクリメンタル処理 : SDP はマテリアライズドビュー用のインクリメンタル処理エンジンを提供します。 これを使用するには、バッチ セマンティクスを使用して変換ロジックを作成します。エンジンは、可能な限り新しいデータとデータ ソース内の変更のみを処理します。 増分処理により、ソースに新しいデータまたは変更が発生したときに非効率的な再処理が削減され、増分処理を処理するための手動コードが不要になります。
重要な概念
以下の図は、 Lakeflow Spark宣言型パイプラインの最も重要な概念を示しています。
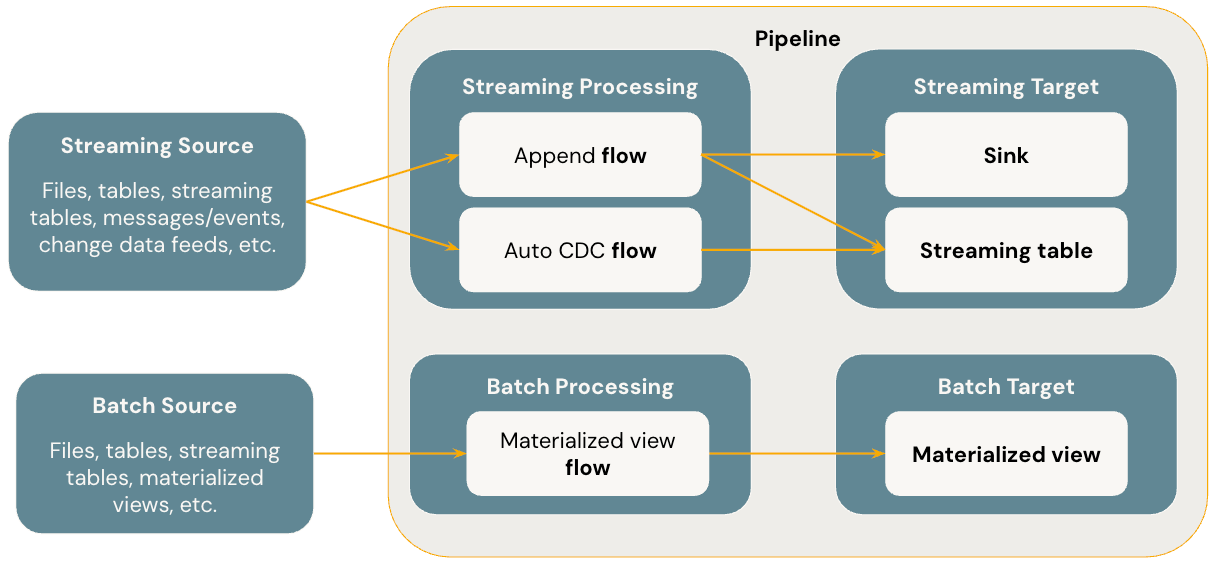
フロー
フローはSDPにおける基本的なデータ処理概念であり、ストリーミングとバッチの両方のセマンティクスをサポートします。フローは、ソースからデータを読み取り、ユーザー定義の処理ロジックを適用し、結果をターゲットに書き込みます。SDP は、Spark 構造化ストリーミングと同じストリーミングフローの種類(追加、更新、完了)を共有します。(現在、 Append および Update フローのみが公開されています。)詳細については、 構造化ストリーミングの出力モードを参照してください。
Lakeflow Spark宣言型パイプラインは、追加のフロー タイプも提供します。
- AUTO CDC 、順序外れのCDCイベントを処理し、 SCD Type 1 とSCD Type 2 の両方をサポートするLakeflow SDP の独自のストリーミング フローです。Auto CDC 、 Apache Spark 宣言型パイプラインでは使用できません。
- マテリアライズドビュー は、可能な限り新しいデータとソース テーブルの変更のみを処理する SDP のバッチ フローです。
詳細については、次を参照してください。
ストリーミングテーブル
ストリーミングテーブル はUnity Catalogマネージドテーブルの形式であり、 Lakeflow SDP のストリーミング ターゲットでもあります。 ストリーミング テーブルには、1 つ以上のストリーミング フロー ( Append 、 AUTO CDC ) を書き込むことができます。 AUTO CDC 、 Databricksのストリーミング テーブルでのみ使用できる独自のストリーミング フローです。 ストリーミング フローは、ターゲット ストリーミング テーブルとは別に明示的に定義できます。 ストリーミング フローをストリーミング テーブル定義の一部として暗黙的に定義することもできます。
詳細については、次を参照してください。
マテリアライズドビュー
マテリアライズドビュー は、Unity Catalog マネージドテーブルの形式であり、バッチ ターゲットでもあります。マテリアライズドビューには、1 つ以上のマテリアライズドビューフローを書き込むことができます。マテリアライズドビューがストリーミングテーブルと異なるのは、常にマテリアライズドビューの定義の一部としてフローを暗黙的に定義する点です。
詳細については、次を参照してください。
シンク
シンク はパイプラインのストリーミング ターゲットであり、Delta テーブル、Apache Kafka トピック、Azure EventHubs トピック、およびカスタム Python データソースをサポートしています。シンクには、1つ以上のストリーミングフロー( Append 、 Update )を書き込むことができます。
詳細については、次を参照してください。
パイプライン
パイプラインは、 Lakeflow Spark宣言型パイプラインの開発と実行の単位です。 パイプラインには、1 つ以上のフロー、ストリーミング テーブル、マテリアライズドビュー、シンクを含めることができます。 SDP を使用するには、パイプライン ソース コードでフロー、ストリーミング テーブル、マテリアライズドビュー、シンクを定義し、パイプラインを実行します。 パイプラインの実行中に、定義されたフロー、ストリーミング テーブル、マテリアライズドビュー、シンクの依存関係が分析され、それらの実行順序と並列化が自動的に調整されます。
詳細については、次を参照してください。
Databricks SQLパイプライン
ストリーミング テーブルとマテリアライズドビューは、 Databricks SQLの 2 つの基本機能です。 標準SQL使用して、 Databricks SQLでストリーミング テーブルとマテリアライズドビューを作成および更新できます。 Databricks SQL実行のストリーミング テーブルとマテリアライズドビューは、同じDatabricksインフラストラクチャ上にあり、 Lakeflow Spark宣言型パイプラインと同じ処理セマンティクスを持ちます。 Databricks SQLでストリーミング テーブルとマテリアライズドビューを使用すると、フローはストリーミング テーブルとマテリアライズドビュー定義の一部として暗黙的に定義されます。
詳細については、次を参照してください。