マテリアライズドビュー
標準ビューと同様に、マテリアライズドビューもクエリの結果であり、テーブルにアクセスするのと同じ方法でアクセスできます。クエリごとに結果を再計算する標準ビューとは異なり、マテリアライズドビューは結果をキャッシュし、指定された間隔で更新します。マテリアライズドビューは事前に計算されているため、それに対するクエリは通常のビューに対するクエリよりもはるかに高速に実行できます。
マテリアライズドビューとストリーミングテーブルまたはビューの使い分けについては、 「パイプラインとは?」を参照してください。
マテリアライズドビュー は宣言型パイプライン オブジェクトです。それを定義する*クエリ*、それを更新するための フロー 、そして高速アクセス用のキャッシュされた結果が含まれています。マテリアライズドビュー:
- 上流データの変更を追跡します。
- トリガー時、変更されたデータを増分的に処理し、必要な変換を適用します。
- 指定された更新間隔に基づいて、ソースデータと同期して出力テーブルを維持します。
マテリアライズドビューは、多くの変換に適しています。
- 行ではなく、キャッシュされた結果に推論を適用します。実際には、単にクエリーを記述します。
- これらは更新された時点では常に正しいです。必要なすべてのデータは、遅れて到着したり、順不同で到着したりした場合でも処理されます。
- 多くの場合、増分です。Databricks は、マテリアライズドビューの更新コストを最小限に抑える適切な戦略を選択しようとします。
マテリアライズドビューの仕組み
次の図は、マテリアライズドビューの仕組みを示しています。

マテリアライズドビューは、単一のパイプラインによって定義および更新されます。パイプラインのソースコード内で、マテリアライズドビューを明示的に定義できます。パイプラインによって定義されたテーブルは、他のパイプラインによって変更または更新することはできません。
Lakeflowパイプラインの外部でスタンドアロンのマテリアライズドビューを作成すると、Databricksはビューの更新に使用されるパイプラインを作成します。ワークスペースの左側のナビゲーションから**[ジョブとパイプライン]**を選択すると、パイプラインを表示できます。ビューに**パイプラインタイプ**列を追加できます。パイプラインで定義されているマテリアライズドビューのタイプはETLです。スタンドアロンのマテリアライズドビューのタイプはMV/STです。スタンドアロンのマテリアライズドビューを使用するを参照してください。
Databricks は Unity Catalog を使用して、クエリや増分更新用の追加システムビューなど、ビューに関するメタデータを保存します。Databricks は、キャッシュされたデータをクラウドストレージに具現化します。Databricks は、いくつかのバッキングデータを __databricks_internalカタログに保存します。__databricks_internalカタログを参照してください。
Databricksは、マテリアライズドビューの増分更新をサポートするために、内部テーブルを作成します。system.information_schema.tablesにこれらのテーブルが表示されますが、カタログエクスプローラーや他のワークスペースUIには表示されません。
次の例では、2 つのテーブルを結合し、マテリアライズドビューを使用して結果を最新の状態に保ちます。
- Python
- SQL
from pyspark import pipelines as dp
@dp.materialized_view
def regional_sales():
partners_df = spark.read.table("partners")
sales_df = spark.read.table("sales")
return (
partners_df.join(sales_df, on="partner_id", how="inner")
)
CREATE OR REPLACE MATERIALIZED VIEW regional_sales
AS SELECT *
FROM partners
INNER JOIN sales ON
partners.partner_id = sales.partner_id;
自動増分更新
マテリアライズドビューを定義するパイプラインがトリガーされると、ビューは自動的に、多くの場合増分的に更新されます。Databricks は、マテリアライズドビューを最新の状態に保つために必要なデータのみを処理します。マテリアライズドビューは、クエリ結果を最初から完全に再計算する必要がある場合でも、常に正しい結果を表示します。ただし、多くの場合、Databricks はマテリアライズドビューに対して増分更新のみを行うため、完全な再計算よりもはるかにコストを抑えることができます。
以下の図は、 sales_reportと呼ばれるマテリアライズドビューを示しています。これは、 clean_customersとclean_transactionsと呼ばれる 2 つの上流テーブルを結合し、国別にグループ化した結果です。上流プロセスでは、3か国(米国、オランダ、英国)のclean_customersに200行を挿入し、これらの新規顧客に対応するclean_transactionsの5,000行を更新します。sales_reportマテリアライズドビューは、新規顧客または対応する取引がある国のみについて段階的に更新されます。この例では、売上レポート全体ではなく、3行のみが更新されます。
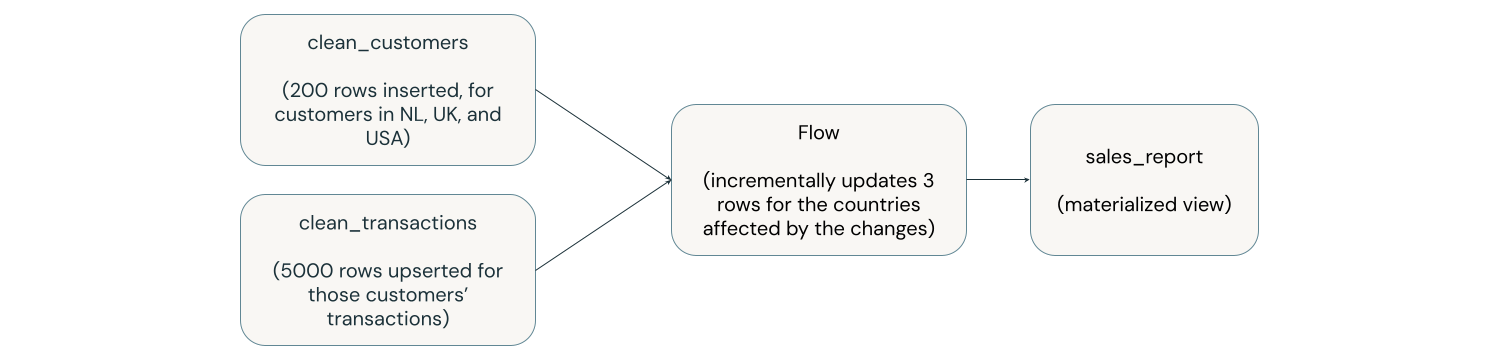
マテリアライズドビューでの増分更新の仕組みに関する詳細については、「マテリアライズドビューの増分更新」を参照してください。
マテリアライズドビューの制限事項
マテリアライズドビューには、以下の制限事項があります。
- 更新によって正しいクエリが作成されるため、入力に対する一部の変更では、マテリアライズドビューの完全な再計算が必要になり、これにはコストがかかる可能性があります。
- これらは低レイテンシユースケース向けには設計されていません。マテリアライズドビューを更新する際のレイテンシーは、ミリ秒ではなく、数秒から数分です。
- すべての計算が増分的に計算できるわけではありません。
- Databricks は、マテリアライズドビューで使用される UDF の動作が変更されたことを検出すると、更新された UDF を適用するために完全な更新を実行します。ただし、他の関数やライブラリを呼び出す UDF は、Databricks では認識できない形で動作が変更される可能性があります。その一例として、呼び出されたライブラリがアップグレードされる場合が挙げられます。UDF の動作が変更された場合、それを使用するマテリアライズドビューに対し、完全更新を実行する必要があります。
- マテリアライズドビューは
CLONEをサポートしていません。マテリアライズドビューを、ディープクローンまたはシャロークローンのソースまたはターゲットとして使用することはできません。詳細については、 「 制限 」を参照してください。 - マテリアライズドビューをバックアップするパイプラインを表示するには、管理者以外のユーザーはパイプラインに対する権限に加えて、マテリアライズドビューに対する
REFRESH権限が必要です。パイプラインとその出力は誰が閲覧できますか?を参照してください。