ストリーミングテーブル
ストリーミングテーブルは、ストリーミングまたは増分データ処理の追加サポートを備えたDeltaテーブルです。パイプライン内の1つ以上のフローが、ストリーミングテーブルをターゲットにできます。
ストリーミングテーブルとマテリアライズドビューまたはビューのどちらを使用するかについてのガイダンスについては、 「パイプラインとは?」を参照してください。
ストリーミングテーブルがデータ取り込みに適している理由は次のとおりです。
- 各入力行は一度だけ処理され、これにより、大半の取り込みワークロード(つまり、テーブルに行を追加またはアップサートすることによって)のモデルとなります。
- 膨大な量の追加専用データを処理できます。
ストリーミングテーブルは、行と時間枠に基づいて推論でき、大量のデータを処理し、低レイテンシーの処理を提供できるため、低レイテンシーのストリーミング変換にも適しています。
次の図は、フローがストリーミング ソースから読み取り、パイプライン内のストリーミングテーブルに段階的に書き込む方法を示しています。
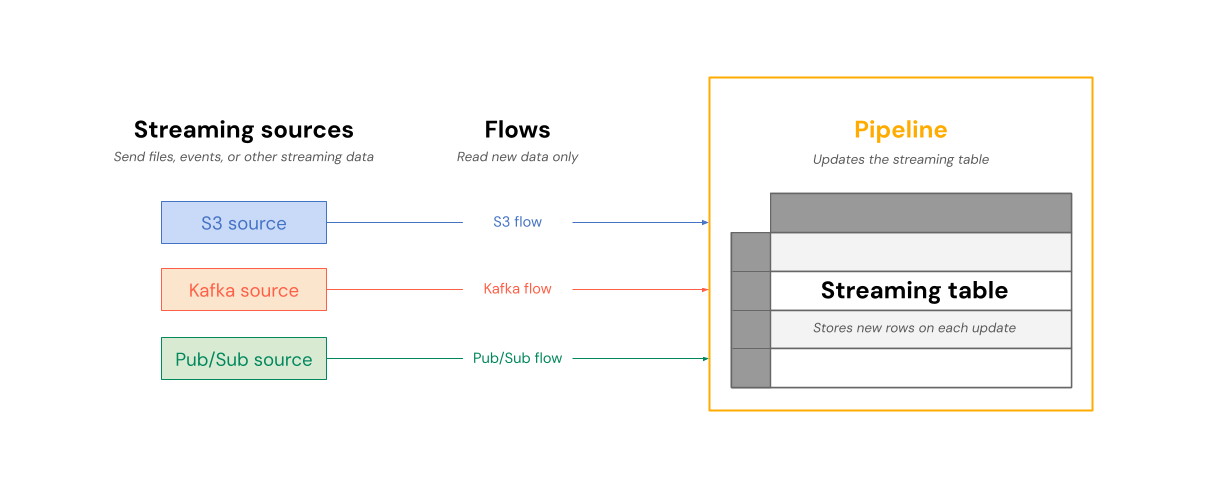
更新ごとに、ストリーミングテーブルに関連付けられたフローは、ストリーミングソース内の変更された情報を読み込み、そのテーブルに新しい情報を追加します。
ストリーミングテーブルは1つのパイプラインによって所有され、更新されます。パイプラインのソースコードでストリーミングテーブルを明示的に定義します。パイプラインによって定義されているテーブルは、他のパイプラインで変更または更新することはできません。単一のストリーミングテーブルに複数のフローを定義して追加することができます。
Databricks はストリーミングテーブル処理をサポートするために内部テーブルを作成します。これらのテーブルは system.information_schema.tables に表示されますが、カタログエクスプローラーやその他のワークスペース UI ページでは表示されません。
LakeFlow Pipelinesの外部でスタンドアロンのストリーミングテーブルを作成すると、Databricksはテーブルの更新に使用されるパイプラインを作成します。ワークスペースの左側のナビゲーションで ジョブ & パイプライン を選択すると、パイプラインを表示できます。ビューに パイプラインタイプ 列を追加できます。パイプラインで定義されたストリーミングテーブルは ETL タイプです。スタンドアロンのストリーミングテーブルは MV/ST タイプです。
フローに関する詳細については、「Load and process data incrementally with LakeFlow Pipelines」を参照してください。
データ取り込みのためのストリーミングテーブル
ストリーミングテーブルは、追加専用のデータソース用に設計されており、入力を一度だけ処理します。これは、データが継続的に到着し、既存のレコードを再処理することなく確実にキャプチャする必要がある取り込みワークロードに最適です。Databricks は、クラウドオブジェクトストレージ(Auto Loader を使用)や、Apache Kafka、Azure Event Hubs、Google Pub/Sub などのストリーミングメッセージバスからのストリーミングテーブルへの取り込みをサポートしています。取り込みのハウツーとコード例については、「パイプラインでデータをロードする」を参照してください。
時間と共に変化するソースデータ(たとえば、ソースで更新または削除されるレコード)をストリームするには、それらを追記する代わりに、AUTO CDC を使用してそれらの変更をストリーミングテーブルに適用します。「チェンジデータキャプチャとスナップショット」を参照してください。
次の図は、追記専用ストリーミングテーブルの仕組みを示しています。
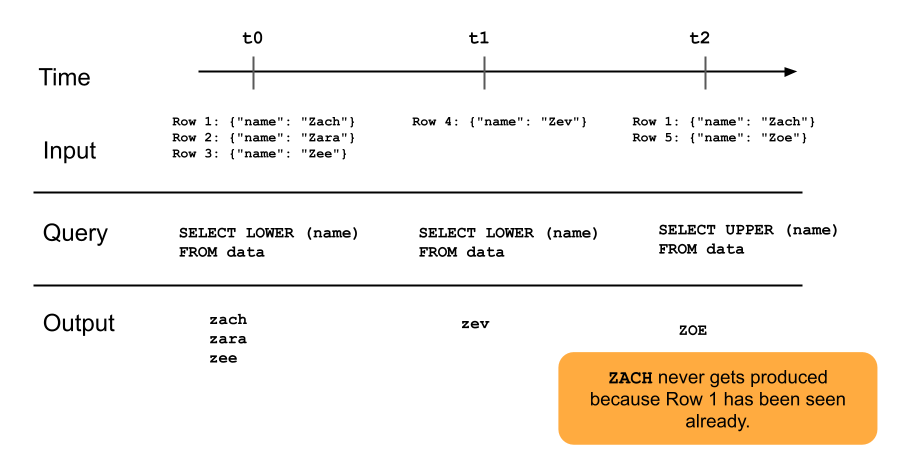
ストリーミングテーブルにすでに追加されている行は、パイプラインの後続の更新で再度クエリされることはありません。クエリを変更した場合(例: SELECT LOWER (name) から SELECT UPPER (name) に)、既存の行は大文字に更新されませんが、新しい行は大文字になります。ソーステーブルから以前のすべてのデータを再クエリし、ストリーミングテーブル内のすべての行を更新するために、フル更新を実行できます。
ストリーミングテーブルと低レイテンシーのストリーミング
ストリーミングテーブルは、境界を超えたステートに対する低レイテンシーのストリーミング用に設計されています。ストリーミングテーブルはチェックポイント管理を使用するため、低レイテンシーのストリーミングに適しています。ただし、自然な境界のあるストリームまたはウォーターマークで囲まれたストリームが想定されます。
自然な境界のあるストリームは、開始と終了が明確に定義されたストリーミング データソースによって生成されます。自然な境界のあるストリームの例としては、ファイルの最初のバッチが配置された後に新しいファイルが追加されないファイルのディレクトリからデータを読み取る場合があります。ファイルの数が有限であるため、ストリームには境界があると見なされ、すべてのファイルが処理された後にストリームは終了します。
ウォーターマークを使用して、ストリームを囲むこともできます。構造化ストリーミングにおけるウォーターマークは、期間が完了したと見なす前に、システムが遅延イベントをどのくらい待機すべきかを指定することで、遅延データを処理するのに役立つメカニズムです。ウォーターマークがない無制限のストリームは、メモリ不足が原因でパイプラインが失敗する可能性があります。
最低限のレイテンシーを必要とする運用ワークロードでは、リアルタイムモードでパイプラインを実行し、エンドツーエンドで1秒未満のレイテンシーでレコードを処理できます。
詳細については、以下を参照してください。
ストリーミングテーブルの制限
ストリーミングテーブルには次の制限があります。
- 限定的な変更: データセット全体を再計算することなく、クエリを変更できます。完全な更新を行わない場合、ストリーミングテーブルは各行を一度しか参照しないため、異なるクエリは異なる行を処理することになります。例えば、クエリ内のフィールドに
UPPER()追加すると、変更後に処理された行のみが大文字になります。つまり、データセット上で実行されているクエリの過去のすべてのバージョンを把握しておく必要があるということです。変更前に処理された既存の行を再処理するには、完全な更新が必要です。 - 状態管理: ストリーミングテーブルは低レイテンシーであり、自然に境界が設定されているか、ウォーターマークで囲まれているストリームを必要とします。詳細については、「ウォーターマークを使用したステートフル処理の最適化」を参照してください。
- 結合は再計算されません : ストリーミングテーブル内の結合は、ディメンションが変更されても再計算されません。この特性は、「速いが間違っている」シナリオに適しています。ビューを常に正しく表示する場合は、マテリアライズドビューを使用できます。マテリアライズドビューは、ディメンションが変更されたときに結合を自動的に再計算するため、常に正しいビューです。詳細については、 「マテリアライズドビュー」を参照してください。ストリームを静的ディメンションテーブルに結合する例については、ストリーム静的JOINを参照してください。
CLONEはサポート対象外: ストリーミングテーブルは、ディープクローンまたはシャロークローンのソースまたはターゲットとして使用できません。サポートされていないその他のコマンドについては、制限事項を参照してください。- パイプラインを表示するには
REFRESH権限が必要です。 ストリーミングテーブルをサポートするパイプラインを表示するには、管理者以外のユーザーは、パイプラインに対する権限に加えて、ストリーミングテーブルに対するREFRESH権限が必要です。パイプラインとその出力は誰が閲覧できますか?を参照してください。