ストリーミング チェックポイントの障害からパイプラインを回復する
ストリーミングチェックポイントが無効または破損した場合に、フル更新、バックアップとバックフィル、または選択的チェックポイントResetを使用してLakeflow pipelineを回復します。
ストリーミング チェックポイントとは何ですか?
Apache Spark構造化ストリーミングでは、チェックポイントはストリーミング クエリの状態を保持するために使用されるメカニズムです。 この状態には次のものが含まれます。
- 進行状況情報 : ソースからのどのオフセットが処理されたか。
- 中間状態 : ステートフル操作のためにマイクロバッチ間で維持する必要があるデータ (集計など、
mapGroupsWithState)。 - メタデータ : ストリーミング クエリの実行に関する情報。
チェックポイントは、ストリーミング アプリケーションにおけるフォールト トレランスとデータの一貫性を確保するために不可欠です。
- フォールト トレランス : ストリーミング アプリケーションに障害が発生した場合 (たとえば、ノード障害、アプリケーション クラッシュなど)、チェックポイントにより、アプリケーションは最初からすべてのデータを再処理するのではなく、最後に成功したチェックポイントの状態から再起動できます。これにより、データの損失を防ぎ、増分処理が保証されます。
- 正確に 1 回の処理 : 多くのストリーミング ソースでは、チェックポイントをべき等シンクと組み合わせることで、正確に 1 回の処理が可能になり、障害が発生した場合でも各レコードが正確に 1 回処理されることが保証され、重複や省略が防止されます。
- 状態管理 : ステートフル変換の場合、チェックポイントによってこれらの操作の内部状態が保持され、ストリーミング クエリは蓄積された履歴状態に基づいて新しいデータの処理を正しく続行できるようになります。
パイプラインのチェックポイント
パイプラインは構造化ストリーミングに基づいて構築されており、基礎となるチェックポイント管理の多くを抽象化し、より宣言的なアプローチを提供します。パイプラインでストリーミングテーブルを定義すると、ストリーミングテーブルに書き込むフローごとにチェックポイント状態があります。これらのチェックポイントの場所はパイプラインの内部にあり、ユーザーはアクセスできません。
通常、次の場合を除いて、ストリーミング テーブルの基礎となるチェックポイントを管理したり理解したりする必要はありません。
- 巻き戻しと再生 : テーブルの現在の状態を維持しながら、特定の時点からのデータを再処理する場合は、ストリーミング テーブルのチェックポイントをリセットする必要があります。
- チェックポイントの障害または破損からの回復 : ストリーミング テーブルへのクエリ書き込みがチェックポイント関連のエラーのために失敗した場合、ハード障害が発生し、クエリはそれ以上進めなくなります。 このクラスの障害から回復するには、次の 3 つの方法があります。
- テーブル全体の更新 : テーブルをリセットし、既存のデータを消去します。
- バックアップとバックフィルによる完全なテーブル更新 : 完全なテーブル更新を実行して古いデータをバックフィルする前に、テーブルのバックアップを作成しますが、これは非常にコストがかかるため、最後の手段にする必要があります。
- チェックポイントをリセットして段階的に続行する : 既存のデータを失うわけにはいかない場合は、影響を受けるストリーミング フローに対して選択的なチェックポイント リセットを実行する必要があります。
例: コード変更によるパイプラインの失敗
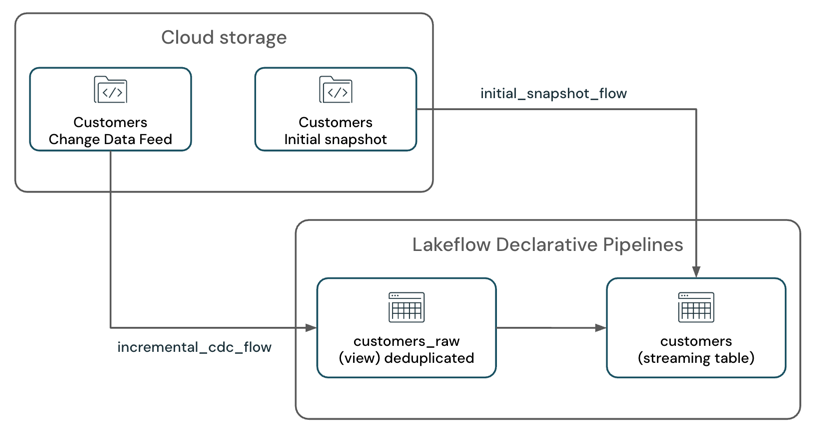
Amazon S3 などのクラウド ストレージ システムからの初期テーブル スナップショットとともに変更データフィードを処理し、SCD-1 ストリーミング テーブルに書き込むAmazon S3があるシナリオを考えてみましょう。
パイプラインには 2 つのストリーミング フローがあります。
customers_incremental_flow:customerソース テーブル CDC フィードを増分読み取り、重複レコードをフィルター処理して、ターゲット テーブルに upsert します。customers_snapshot_flow:customersソース テーブルの初期スナップショットを 1 回読み取り、レコードをターゲット テーブルにアップサートします。
@dp.temporary_view(name="customers_incremental_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load(customers_incremental_path)
.dropDuplicates(["customer_id"])
)
@dp.temporary_view(name="customers_snapshot_view")
def full_orders_snapshot():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.includeExistingFiles", "true")
.option("cloudFiles.inferColumnTypes", "true")
.load(customers_snapshot_path)
.select("*")
)
dp.create_streaming_table("customers")
dp.create_auto_cdc_flow(
flow_name = "customers_incremental_flow",
target = "customers",
source = "customers_incremental_view",
keys = ["customer_id"],
sequence_by = col("sequenceNum"),
apply_as_deletes = expr("operation = 'DELETE'"),
apply_as_truncates = expr("operation = 'TRUNCATE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
dp.create_auto_cdc_flow(
flow_name = "customers_snapshot_flow",
target = "customers",
source = "customers_snapshot_view",
keys = ["customer_id"],
sequence_by = lit(0),
stored_as_scd_type = 1,
once = True
)
このパイプラインのデプロイ後、正常に実行され、チェンジデータフィードと初期スナップショットの処理が開始されます。
その後、 customers_incremental_viewクエリ内の重複排除ロジックが冗長であり、パフォーマンスのボトルネックを引き起こしていることがわかります。パフォーマンスを向上させるには、 dropDuplicates()を削除します。
@dp.temporary_view(name="customers_raw_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load()
# .dropDuplicates()
)
dropDuplicates() API を削除してパイプラインを再デプロイすると、次のエラーが発生して更新が失敗します。
Streaming stateful operator name does not match with the operator in state metadata.
This is likely to happen when a user adds/removes/changes stateful operators of existing streaming query.
Stateful operators in the metadata: [(OperatorId: 0 -> OperatorName: dedupe)];
Stateful operators in current batch: []. SQLSTATE: 42K03 SQLSTATE: XXKST
このエラーは、チェックポイントの状態と現在のクエリ定義が一致しないため変更が許可されず、パイプラインがそれ以上進めないことを示します。
チェックポイント関連の障害は、 dropDuplicates API の削除以外にもさまざまな理由で発生する可能性があります。一般的なシナリオは次のとおりです:
- 既存のストリーミング クエリでステートフル演算子を追加または削除します (たとえば、
dropDuplicates()または集計の導入または削除)。 - 以前にチェックポイントが設定されたクエリでストリーミング ソースを追加、削除、または結合する (たとえば、既存のストリーミング クエリを新しいストリーミング クエリと結合したり、既存の結合操作からソースを追加/削除する)。
- ステートフル ストリーミング操作の状態スキーマの変更 (重複排除や集約に使用される列の変更など)。
サポートされている変更とサポートされていない変更の包括的なリストについては、「 Spark構造化ストリーミング ガイド」および「構造化ストリーミング クエリの変更の種類」を参照してください。
回復オプション
データの耐久性要件とリソースの制約に応じて、次の 3 つの回復戦略があります。
方法 | 複雑 | コスト | 潜在的なデータ損失 | 潜在的なデータ重複 | 初期スナップショットが必要 | テーブル全体のリセット |
|---|---|---|---|---|---|---|
低 | M | はい (初期スナップショットが利用できない場合、またはソースで生のファイルが削除されている場合) | いいえ (変更の適用先テーブルの場合) | はい | はい | |
M | 高 | No | いいえ (べき等シンクの場合)。たとえば、自動 CDC などです。 | No | No | |
中〜高 (不変のオフセットを提供する追加専用ソースの場合は中)。 | 低 | いいえ(慎重に検討する必要があります。) | いいえ (べき等ライターの場合)。たとえば、ターゲット テーブルへの自動 CDC のみなどです。 | No | No |
中〜高の複雑さは、ストリーミング ソースの種類とクエリの複雑さによって異なります。
推奨事項
- チェックポイントのリセットの複雑な処理を避けたい場合で、かつテーブル全体を再計算できる場合は、フルテーブル更新をご利用ください。完全更新には、コードを変更するオプションもあります。
- チェックポイントのリセットの複雑さに対処したくない場合、およびバックアップの取得とヒストリカルデータのバックフィルの追加コストを許容できる場合は、バックアップとバックフィルを使用した完全なテーブル更新を使用します。
- テーブル内の既存のデータを保持し、新しいデータを段階的に処理し続ける必要がある場合は、リセット テーブル チェックポイントを使用します。ただし、この方法では、テーブル内の既存のデータが失われていないこと、パイプラインが新しいデータの処理を続行できることを確認するために、チェックポイントのリセットを慎重に処理する必要があります。
チェックポイントをリセットして段階的に続行する
チェックポイントをリセットして段階的に処理を続行するには、次のステップに従います。
-
パイプラインを停止します。パイプラインでアクティブな更新が実行されていないことを確認します。
-
新しいチェックポイントの開始位置を決定します。処理を続行する最後の正常なオフセットまたはタイムスタンプを識別します。これは通常、障害が発生する前に正常に処理された最新のオフセットです。
前の例では Auto Loader を使用して JSON ファイルを読み込むため、
modifiedAfterオプションを使用して、Auto Loader が新しいファイルの処理を開始する時刻のタイムスタンプを設定できます。Kafka ソースの場合、
startingOffsetsオプションを使用して、ストリーミング クエリが新しいデータの処理を開始するオフセットを指定できます。Delta Lake ソースの場合、
startingVersionオプションを使用して、ストリーミング クエリが新しいデータの処理を開始するバージョンを指定できます。 -
コードの変更:ストリーミングクエリを変更して、
dropDuplicates()API を削除したり、その他の変更を加えたりすることができます。また、 Auto Loader読み取りパスにmodifiedAfterオプションが追加されていることを確認してください。Python@dp.temporary_view(name="customers_incremental_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.option("modifiedAfter", "2025-04-09T06:15:00")
.load(customers_incremental_path)
# .dropDuplicates(["customer_id"])
)
不正確なmodifiedAfterタイムスタンプを指定すると、データが失われたり重複したりする可能性があります。古いデータが再度処理されたり、新しいデータが失われたりするのを避けるために、タイムスタンプが正しく設定されていることを確認してください。
クエリにストリーム-ストリーム結合またはストリーム-ストリーム ユニオンがある場合は、参加しているすべてのストリーミング ソースに上記の戦略を適用する必要があります。 例えば:
cdc_1 = spark.readStream.format("cloudFiles")...
cdc_2 = spark.readStream.format("cloudFiles")...
cdc_source = cdc_1..union(cdc_2)
-
チェックポイントのリセットを希望するストリーミングテーブルに紐付けられているフロー名を特定してください。各フロー名を完全修飾
catalog.schema.flow_nameの形式で渡してください。例では、完全修飾フロー名はmy_catalog.my_schema.customers_incremental_flowです。フローは、明示的なflow_nameパラメーターの値をcustomers_incremental_flowとして使用します。明示的なフロー名を設定しない場合、デフォルトのフロー名は、catalog.schema.table形式の完全修飾ターゲットテーブル名になります(例:my_catalog.my_schema.customers)。フロー名は、パイプラインコード、パイプライン UI、またはパイプラインイベントログで確認できます。 -
チェックポイントをリセットします。Python ノートブックを作成し、それを Databricks クラスターに接続します。
チェックポイントをリセットするには、次の情報が必要です。
- Databricks ワークスペース URL
- パイプラインID
- チェックポイントをリセットするフロー名
Pythonimport requests
import json
# Define your Databricks instance and pipeline ID
databricks_instance = "<DATABRICKS_URL>"
token = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
pipeline_id = "<YOUR_PIPELINE_ID>"
flows_to_reset = ["<YOUR_FLOW_NAME>"]
# Set up the API endpoint
endpoint = f"{databricks_instance}/api/2.0/pipelines/{pipeline_id}/updates"
# Set up the request headers
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json"
}
# Define the payload
payload = {
"reset_checkpoint_selection": flows_to_reset
}
# Make the POST request
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Check the response
if response.status_code == 200:
print("Pipeline update started successfully.")
else:
print(f"Error: {response.status_code}, {response.text}") -
パイプラインの実行: パイプラインは、新しいチェックポイントを使用して指定された開始位置から新しいデータの処理を開始し、増分処理を継続しながら既存のテーブル データを保持します。
ベストプラクティス
- 本番運用ではプライベート プレビュー機能の使用を避けてください。
- 本番運用環境に変更を加える前に、変更をテストしてください。
- 理想的には、より低い環境でテスト パイプラインを作成します。これが不可能な場合は、テストに別のカタログとスキーマを使用してみてください。
- エラーを再現します。
- 変更を適用します。
- 結果を検証し、継続/中止を決定します。
- 変更を本番運用パイプラインにロールアウトします。