MLflowとJobsの実行ページで実行を追跡する
備考
プレビュー
この機能は パブリック プレビュー段階です。
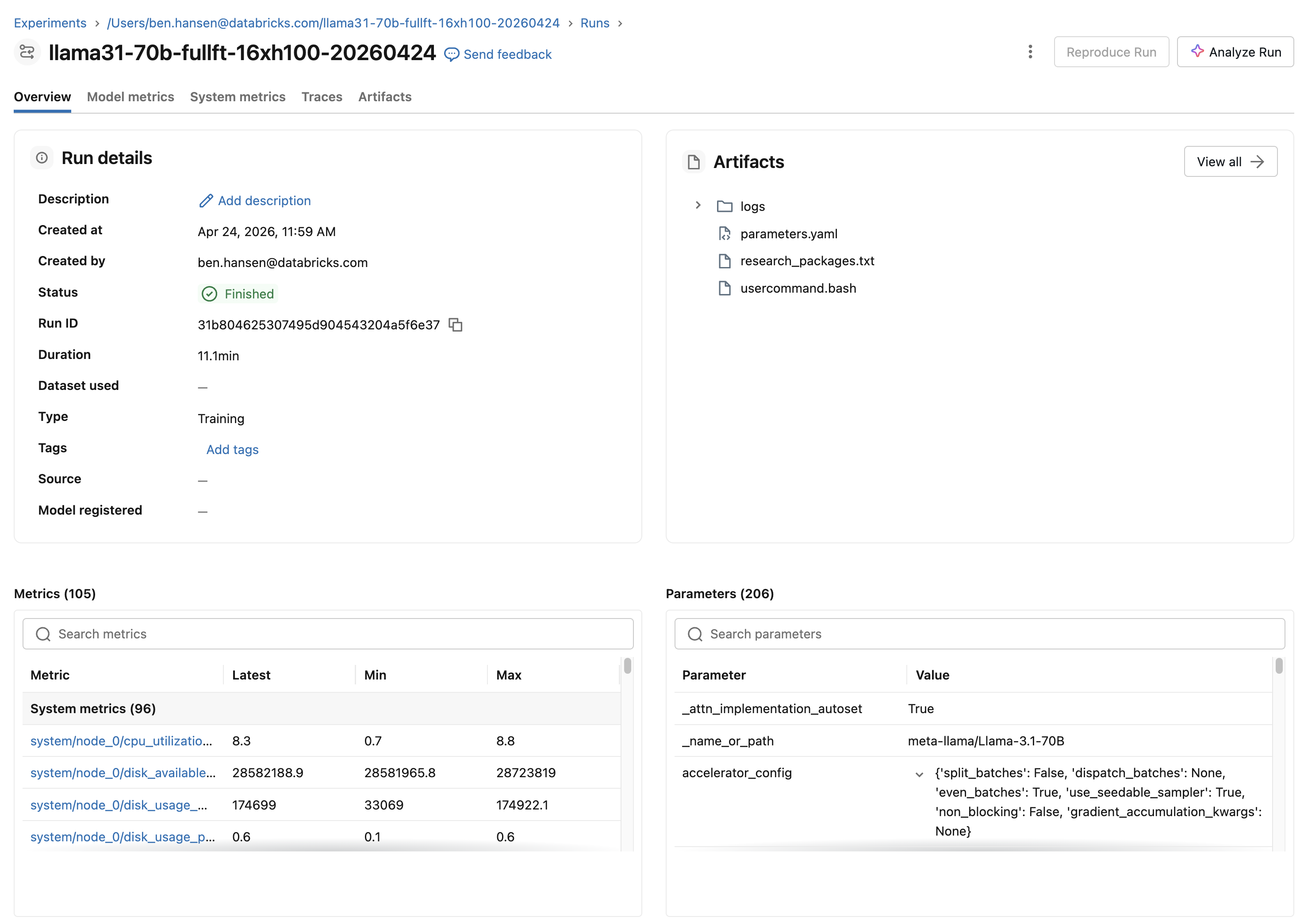
air run で送信する各ワークロードは、Databricks ジョブ実行でもあり、MLflow 実行でもあります。
- ジョブ実行(ワークスペースの ジョブとパイプライン ページで確認できます)は、実行のステータス、コンピュート、再試行、およびドライバーの出力を追跡します。
- MLflow の実行は、エクスペリメントを追跡します:パラメーター、メトリクス、システムメトリクス、アーティファクト。
1回の送信で、1つのジョブ実行と1つのMLflow実行が作成されます。再試行により、新しいMLflow実行が作成されます。
エクスペリメントと実行
2つのワークロードYAMLフィールドは、MLflowでの実行の表示方法を制御します:
YAML
experiment_name: my-training # Creates or appends to this MLflow experiment
mlflow_run_name: baseline-lr3e5 # Names the MLflow run for this submission
compute:
num_accelerators: 8
accelerator_type: GPU_8xH100
command: torchrun --nproc_per_node=8 train.py
max_retries: 2
experiment_name(必須):MLflowエクスペリメントがこの名前で存在しない場合は新規作成し、既存のエクスペリメントには新しい実行を追加します。エクスペリメントには多くの実行が含まれます。mlflow_run_name(オプション):実行名を設定します。省略された場合、実行名はデフォルトでエクスペリメント名(experiment_name)になります。max_retries(任意)各再試行は、同じエクスペリメント内の新しいMLflow実行なので、試行を比較できます。最初の送信とその再試行は1つのジョブ実行を共有します。
Jobs、MLflow、および以前のワークロード間を切り替えます
3つの場所から実行にアクセスできます。
- ジョブ : ジョブ実行ページには、実行が一覧表示され、各実行はMLflow実行とエクスペリメントにリンクしています。
- MLflow:エクスペリメントページには、MLflowエクスペリメントが一覧表示されます。
- 以前のワークロード :
air get run <job-run-id>は、実行ジョブ、エクスペリメント、MLflow実行へのクリック可能なリンクを表示します。air list runsは以前の実行を一覧表示し、特定の実行を検索するためにフィルターできます。
Bash
air get run <job-run-id> # Links to the job, experiment, and MLflow run
air list runs # List previous runs; filter to find a specific run
システムメトリクス
GPU、CPU、およびメモリシステムメトリクスは、すべての実行で自動的に取得されます。設定は不要です。MLflow の実行の システムメトリクス タブでご覧ください。
![MLflow実行の[システムメトリクス]タブ (GPU/CPU/メモリ)](/aws/ja/assets/images/mlflow-system-metrics-1a0898f1033502b9c1fb89df94b34473.png)
カスタムメトリクスのログ
プラットフォームはMLflow 実行を作成し、そのIDをMLFLOW_RUN_ID環境変数を通じてトレーニングプロセスに公開します。MLflow tracking API を使用して、独自のパラメーター、メトリクス、およびアーティファクトをその実行にログに記録します。
分散型 (マルチノード) ワークロードでは、各ノードが同じ MLflow の実行を共有します。rank-0 プロセスからのみログを記録するため、各メトリクスは一度だけ記録されます。
Python
import os
import mlflow
# Log from rank 0 only; all nodes share the same MLFLOW_RUN_ID.
if os.environ.get("RANK", "0") == "0":
with mlflow.start_run(run_id=os.environ["MLFLOW_RUN_ID"]):
mlflow.log_param("learning_rate", 3e-4)
for step, loss in enumerate(training_losses):
mlflow.log_metric("train_loss", loss, step=step)
ログとアーティファクト
実行のログをair logsを使用してストリームまたはダウンロードする:
Bash
air logs <job-run-id> # Stream logs from node 0
air logs <job-run-id> --node 2 # Logs from a specific node
air logs <job-run-id> --download-to ./logs/ # Download instead of streaming
ログはMLflow 実行でアーティファクトとしても利用できます。モデルチェックポイントを永続化するには、Unity Catalog ボリュームに書き込みます。チェックポイントパターンとボリュームの管理については、エクスペリメントの追跡と観察可能性を参照してください。