実験の追跡と観察可能性
プレビュー
この機能は パブリック プレビュー段階です。
AI Runtimeは、エクスペリメントトラッキングのためにMLflowとネイティブに統合されており、利用率、メモリ、温度をモニタリングするための組み込みGPUリソースペインが含まれています。MLflowを使用してメトリクスと実行をログに記録し、ノートブックとMLflow UIでトレーニング出力を表示し、モデルのチェックポイントをUnity Catalogボリュームに保存し、コードの実行中にGPUの健全性を追跡します。
MLflowとの連携
AI Runtime 、エクスペリメントの追跡、モデルのログ記録、メトリクスの視覚化のためにMLflowとネイティブに統合します。
設定に関する推奨事項:
-
MLflowをバージョン3.7以降にアップグレードし、ディープラーニングのワークフローパターンに従ってください。
-
PyTorch Lightningの自動ログ記録を有効にする:
Pythonimport mlflow
mlflow.pytorch.autolog() -
MLflowの実行名をカスタマイズするには、モデルのトレーニングコードを
mlflow.start_run()APIスコープ内にカプセル化します。これにより、実行名を制御でき、以前の実行から再開できるようになります。mlflow.start_run(run_name="your-custom-name")またはMLflowをサポートするサードパーティ ライブラリ ( Hugging Face Transformers など) のrun_name懸念を使用して実行名をカスタマイズできます。 それ以外の場合、デフォルトの実行名はjobTaskRun-xxxxxです。Pythonfrom transformers import TrainingArguments
args = TrainingArguments(
report_to="mlflow",
run_name="llama7b-sft-lr3e5", # <-- MLflow run name
logging_steps=50,
) -
サーバレス GPU API を使用する場合、
.distributed()の呼び出しごとに MLflow エクスペリメントの実行が自動的に作成されます。アクティブな MLflow 実行内で呼び出された場合、ネストされた子実行が作成され、代わりにアクティブな親の下に作成されます。Pythonimport mlflow
with mlflow.start_run() as outer_run:
...
run_train.distributed() # creates a nested child run under outer_run -
.distributed()が使用するエクスペリメントをカスタマイズするには、.distributed()を呼び出す前にmlflow.set_experiment()を呼び出すか、MLFLOW_EXPERIMENT_NAME環境変数を設定します。デフォルトのエクスペリメント名は/Users/{WORKSPACE_USER}/{notebook-name}です。常に絶対パスを使用してください。Pythonimport mlflow
mlflow.set_experiment("/Users/<username>/my-experiment")
run_train.distributed()代わりに:
Pythonimport os
os.environ["MLFLOW_EXPERIMENT_NAME"] = "/Users/<username>/my-experiment" -
以前のMLflow実行を再開するには、
mlflow.start_run(run_id="<previous-run-id>")を使用します。 -
.distributed()で以前のMLflow実行を再開するには、呼び出す前にMLFLOW_RUN_IDを設定します:Pythonos.environ["MLFLOW_RUN_ID"] = "<previous-run-id>"
run_train.distributed() -
MLFlowLoggerのstepパラメーターを適切なバッチ数に設定します。MLflow は 1,000 万のメトリクスステップの制限があるため、大規模なトレーニング実行で単一のバッチごとにログを記録すると、この制限に達する可能性があります。リソース制限を参照してください。
閲覧ログ
- ノートブック出力 : トレーニングコードからの標準出力とエラーは、ノートブックセル出力に表示されます。
- MLflow ログ :MLflow エクスペリメント UI には、トレーニングメトリクス、パラメーター、およびアーティファクトが表示されます。
モデルチェックポイント
分散トレーニングの場合、他のUnity Catalogオブジェクトと同じガバナンスを提供するUnity Catalog ボリュームに、モデルチェックポイントを非同期で保存およびロードします。serverless_gpu.dataパッケージのUCVolumeWriterとUCVolumeReaderを、Torch Distributed Checkpoint (DCP) APIと組み合わせて使用します。これらのストレージバックエンドは、高速なローカルディレクトリ(/tmp、サーバレスGPUノードではNVMeでバックアップされています)を介してすべてのI/Oをステージングし、Unity Catalogボリュームにアップロードまたはダウンロードします。これは、チェックポイントシャードをFUSEマウントに直接書き込むよりも高速です。メタデータの原子性は保持されます。書き込み側は、データシャードのアップロードが完了した後にのみ、.metadataファイルを公開します。
UCVolumeWriter``UCVolumeReader、およびUCVolumeDatasetにはGPU環境5以上が必要です (サーバレスGPU Python API 0.5.16+)。
中断によって失われる作業を最小限に抑えるために、チェックポイントは十分に頻繁に作成しますが、I/Oオーバーヘッドによってトレーニングが遅くならないようにしてください。チェックポイントは30分から1時間ごとに1つ設定することを目指し、ステップ時間とチェックポイントサイズに基づいて間隔を調整します。
トレーニングを続行しながら、バックグラウンドでチェックポイントをアップロードするには、UCVolumeWriter を storage_writer として dcp.async_save に渡します。非同期保存ではプロセスグループにCPUバックエンドが必要なため、torch.distributed.init_process_group(backend="cpu:gloo,cuda:nccl", ...)で初期化してください:
import torch.distributed.checkpoint as dcp
from serverless_gpu.data import UCVolumeWriter
checkpoint_path = "/Volumes/my_catalog/my_schema/model/checkpoints"
writer = UCVolumeWriter(checkpoint_path)
future = dcp.async_save(state_dict, storage_writer=writer)
# ...continue training...
future.result() # blocks until the upload lands on the UC volume
UCVolumeReaderを使用してチェックポイントを読み込みます。
from serverless_gpu.data import UCVolumeReader
reader = UCVolumeReader(checkpoint_path)
dcp.load(state_dict, storage_reader=reader)
データパイプラインのチェックポイント
モデルのチェックポイントは、モデルとオプティマイザーの状態をキャプチャしますが、データセット内でのデータパイプラインの位置はキャプチャしません。そのため、再開された実行は、停止した正確なサンプルに早送りすることはできません。再開する際には、この点を考慮してください:エポックの境界から再開するか、または、再開時にそれらをスキップできるように、処理済みのサンプルやシャードを独自のトレーニング状態で追跡してください。
GPUリソースの監視
AI Runtimeでコードを実行している間の GPU リソース ペインを使用して、GPU の健全性と使用率を監視します。 このペインは、シングルノードとマルチノードの両方のワークロードをサポートしています。
このペインを開くには、ノートブックをAI Runtimeに接続し、![]() 右側のペインの GPU リソース 。
右側のペインの GPU リソース 。
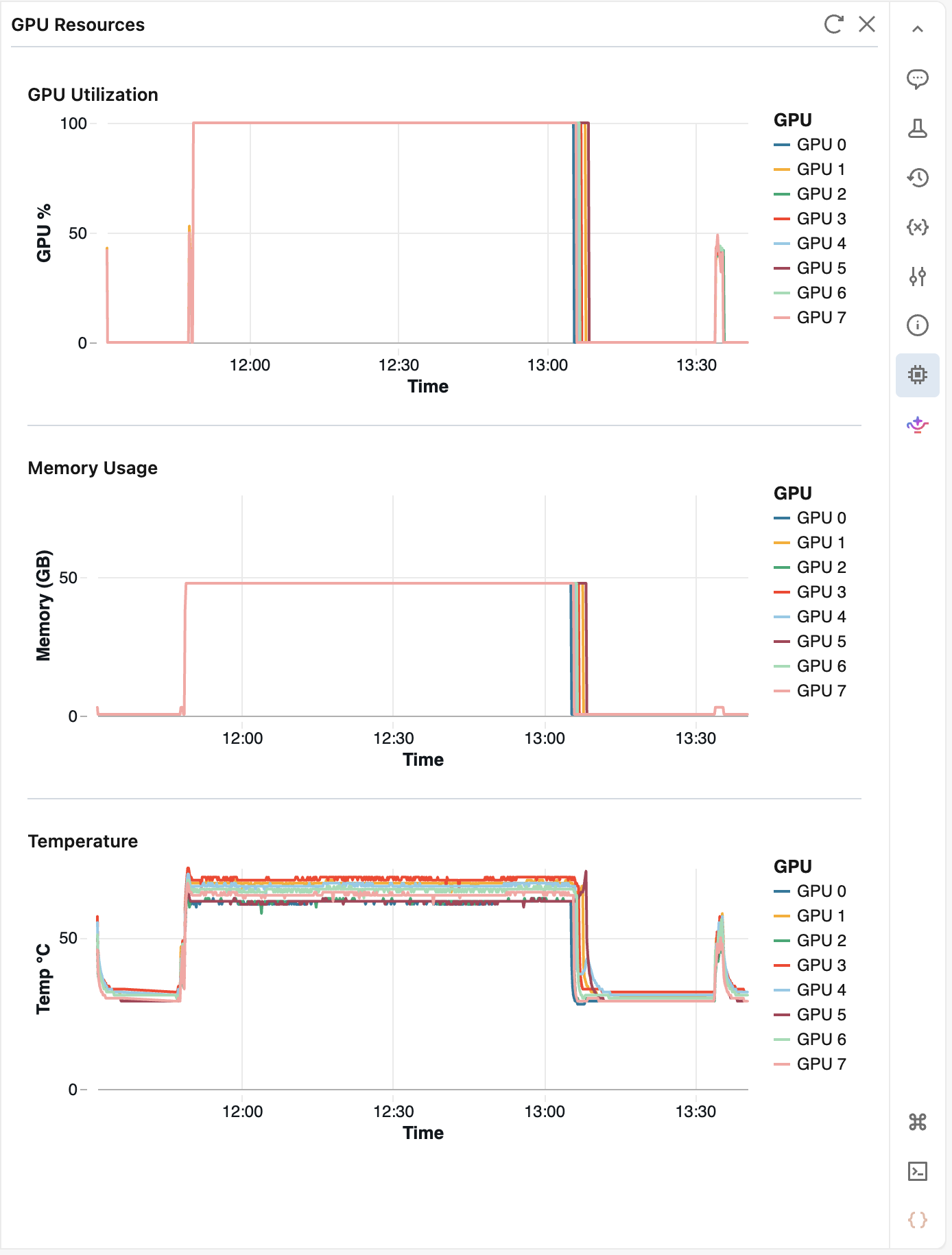
このペインには、GPU ごとに次のメトリクスが表示されます。
- GPU使用率
- GPUメモリ使用量
- 温度
このペインは10秒ごとにメトリクスをポーリングし、最大2時間分の履歴を保持します。クリック![]() 最新の値をすぐに取得するには、 ページを更新してください 。5 分間何も操作しないと、ペインが停止します。再度開くとモニタリングが再開されます。
最新の値をすぐに取得するには、 ページを更新してください 。5 分間何も操作しないと、ペインが停止します。再度開くとモニタリングが再開されます。
複数ユーザーによるコラボレーション
- すべてのユーザーが共有コード(ヘルパーモジュールや環境YAMLファイルなど)にアクセスできるようにするには、
/Workspace/Users/<your_email>/のようなユーザー固有のフォルダではなく、/Workspace/Sharedに保存してください。 - 現在開発中のコードについては、ユーザー固有のフォルダ
/Workspace/Users/<your_email>/内の Git フォルダを使用し、リモート Git リポジトリにプッシュしてください。これにより、複数のユーザーがユーザー固有のクローンとブランチを持つことができ、同時にバージョン管理にはリモートのGitリポジトリを使用できます。 DatabricksでGitを使用する際のベストプラクティスを参照してください。 - 共同作業者はノートブックを共有したり、コメントしたりできます。
Databricksのグローバル制限
リソース制限を参照してください。